 Toronto AI Lab
Toronto AI Lab
In this paper, we address the problem of texture representation for 3D shapes for the challenging and underexplored tasks of texture transfer and synthesis. Previous works either apply spherical texture maps which may lead to large distortions, or use continuous texture fields that yield smooth outputs lacking details. We argue that the traditional way of representing textures with images and linking them to a 3D mesh via UV mapping is more desirable, since synthesizing 2D images is a well-studied problem. We propose AUV-Net which learns to embed 3D surfaces into a 2D aligned UV space, by mapping the corresponding semantic parts of different 3D shapes to the same location in the UV space. As a result, textures are aligned across objects, and can thus be easily synthesized by generative models of images. Texture alignment is learned in an unsupervised manner by a simple yet effective texture alignment module, taking inspiration from traditional works on linear subspace learning. The learned UV mapping and aligned texture representations enable a variety of applications including texture transfer, texture synthesis, and textured single view 3D reconstruction. We conduct experiments on multiple datasets to demonstrate the effectiveness of our method.
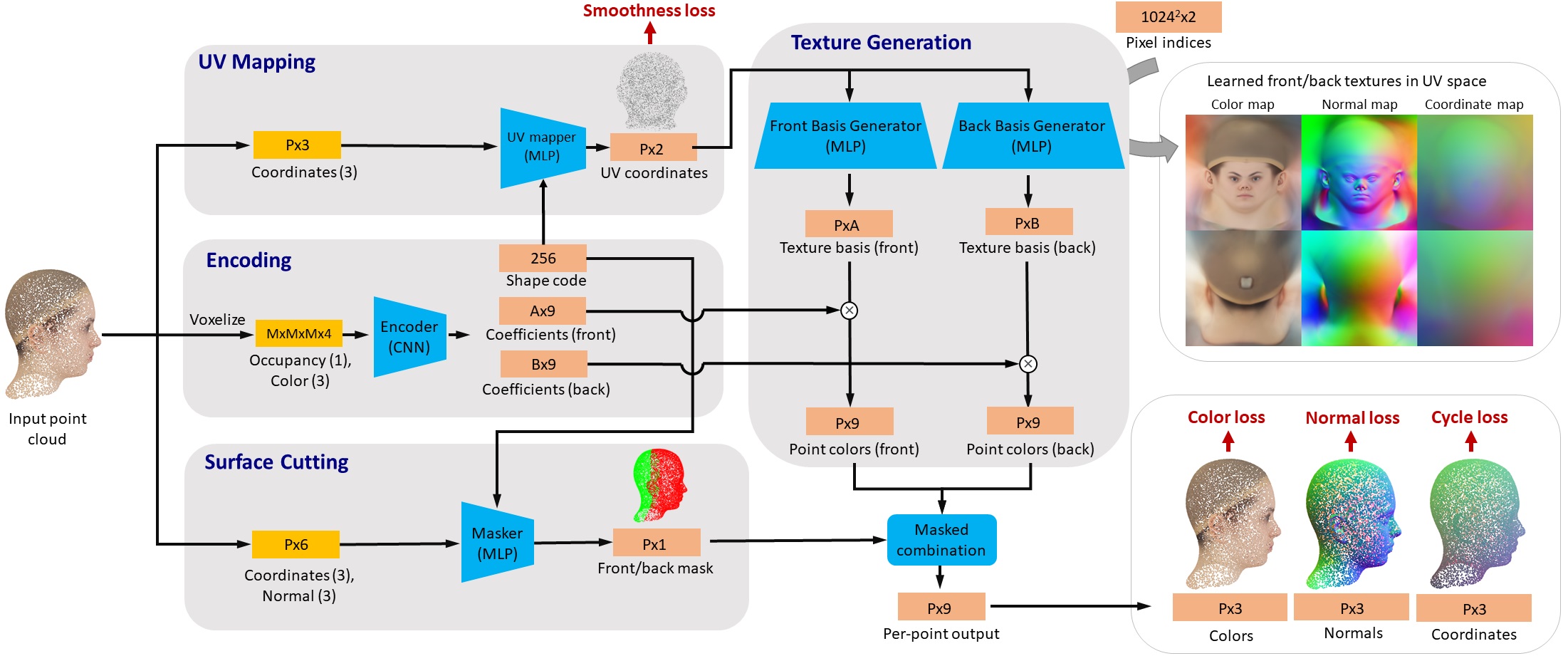
The network architecture of our AUV-Net is shown above.
The core of AUV-Net is an unsupervised texture alignment module, inspired by Principal Component Analysis (PCA). Specifically, the basis generator networks predict basis images shared by all shapes in the training set. Then, those basis images are linearly combined with respect to the predicted per-shape coefficients to produce the texture images of each shape. Such a process forces the network to learn aligned texture images so that they can be effectively decomposed into basis images.
For each training shape, the encoder predicts the shape code and the coefficients from the voxelized input point cloud. The UV mapper and the masker take as input the shape code and the query points from the input point cloud, and output the UV coordinates and the segmentation mask, respectively. The UV coordinates are fed into the two basis generators to obtain the basis colors for each query point, and the basis colors are multiplied by the predicted coefficients to generate the actual colors for each query point. Those colors from the two basis generators are selected by the predicted segmentation mask to produce the final colors.
After training AUV-Net, we obtain aligned high-quality texture images for all training shapes. The fact that these texture images are aligned allows us to transfer textures between two shapes by simply swapping their texture images. The results on cars, animals, chairs, and cartoon characters are shown below. Note that the textures of the cartoon characters are transferred from realistic 3D people meshes.
A big advantage of having aligned texture images is that it allows us to utilize existing 2D generative models to synthesize new textures, and easily map them onto the provided 3D shapes. We train StyleGAN2 in experiments and show results below. For each generated texture image, we can couple it with different shapes. Note that we are provided with geometry and only synthesize texture. The holes on chairs are hallucinated via texture transparency (alpha channels in the texture images).
With the aligned texture representation, we can condition texture synthesis on an input single-view image for 3D reconstruction. To perform this task, in addition to the pre-trained UV mapper and Masker from AUV-Net to predict the UV mapping of the output shape, we add a 2D ResNet image encoder to predict the texture latent code and the shape code from the input image, a CNN decoder to predict the aligned texture images from the texture latent code, and an IM-Net decoder to predict the geometry of the shape conditioned on the shape code. The results comparing with Texture Fields are shown below.
@inproceedings{chen2022AUVNET,
title = {AUV-Net: Learning Aligned UV Maps for Texture Transfer and Synthesis},
author = {Zhiqin Chen and Kangxue Yin and Sanja Fidler},
booktitle = {The Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022}
}
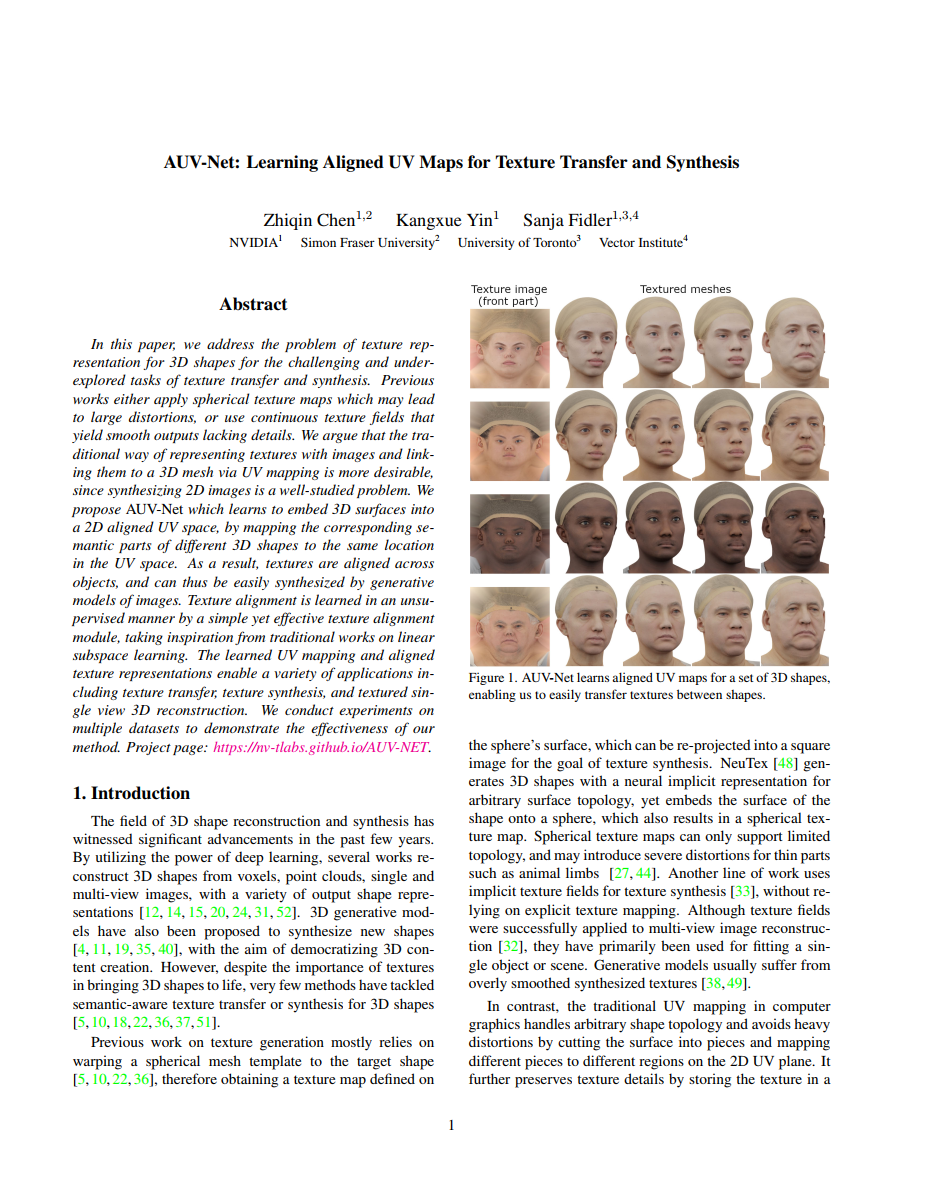
AUV-Net: Learning Aligned UV Maps for Texture Transfer and Synthesis
Zhiqin Chen, Kangxue Yin, Sanja Fidler