Score-based generative models (SGMs) have demonstrated remarkable synthesis quality. SGMs rely on a diffusion process that gradually perturbs the data towards a tractable distribution, while the generative model learns to denoise. The complexity of this denoising task is, apart from the data distribution itself, uniquely determined by the diffusion process. We argue that current SGMs employ overly simplistic diffusions, leading to unnecessarily complex denoising processes, which limit generative modeling performance. Based on connections to statistical mechanics, we propose a novel critically-damped Langevin diffusion (CLD) and show that CLD-based SGMs achieve superior performance. CLD can be interpreted as running a joint diffusion in an extended space, where the auxiliary variables can be considered "velocities" that are coupled to the data variables as in Hamiltonian dynamics. We derive a novel score matching objective for CLD and show that the model only needs to learn the score function of the conditional distribution of the velocity given data, an easier task than learning scores of the data directly. We also derive a new sampling scheme for efficient synthesis from CLD-based diffusion models. We find that CLD outperforms previous SGMs in synthesis quality for similar network architectures and sampling compute budgets. We show that our novel sampler for CLD significantly outperforms solvers such as Euler—Maruyama. Our framework provides new insights into score-based denoising diffusion models and can be readily used for high-resolution image synthesis.
Score-based generative models (SGMs) and denoising diffusion probabilistic models have emerged as a promising class of generative models. SGMs offer high quality synthesis and sample diversity, do not require adversarial objectives, and have found applications in image, speech, and music synthesis, image editing, super-resolution, image-to-image translation, and 3D shape generation. SGMs use a diffusion process to gradually add noise to the data, transforming a complex data distribution to an analytically tractable prior distribution. A neural network is then utilized to learn the score function—the gradient of the log probability density—of the perturbed data. The learnt scores can be used to solve a stochastic differential equation (SDE) to synthesize new samples. This corresponds to an iterative denoising process, inverting the forward diffusion.
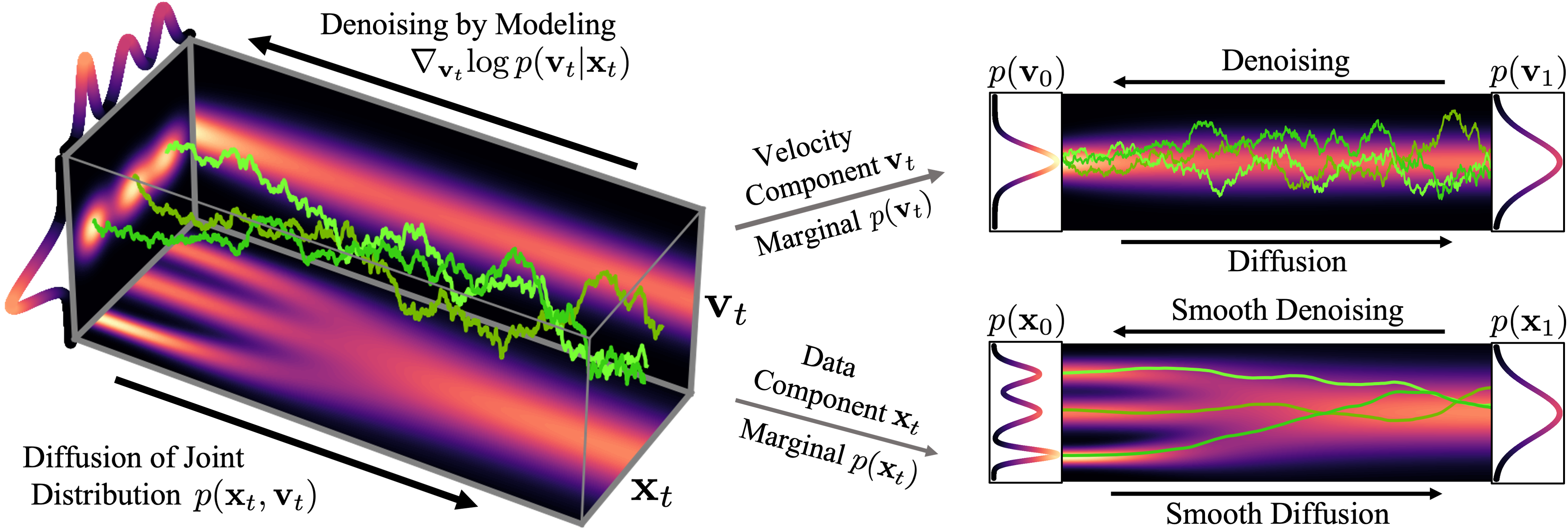
It has been shown that the score function that needs to be learnt by the neural network is uniquely determined by the forward diffusion process. Consequently, the complexity of the learning problem depends, other than on the data itself, only on the diffusion. Hence, the diffusion process is the key component of SGMs that needs to be revisited to further improve SGMs, for example, in terms of synthesis quality or sampling speed.
Inspired by statistical mechanics, we propose a novel forward diffusion process, the critically-damped Langevin diffusion (CLD). In CLD, the data variable, \(\bf{x}_t\) (time \(t\) along the diffusion), is augmented with an additional "velocity" variable \(\bf{v}_t\) and a diffusion process is run in the joint data-velocity space. Data and velocity are coupled to each other as in Hamiltonian dynamics, and noise is injected only into the velocity variable. Similarly as in Hamiltonian Monte Carlo, the Hamiltonian component helps to efficiently traverse the joint data-velocity space and to transform the data distribution into the prior distribution more smoothly. We derive the corresponding score matching objective and show that for CLD the neural network is tasked with learning only the score of the conditional distribution of velocity given data \(\nabla_{\bf{v}_t} \log p_t(\bf{v}_t |\bf{x}_t )\), which is arguably easier than learning the score of the diffused data distribution directly. Using techniques from molecular dynamics, we also derive a novel SDE integrator tailored to CLD's reverse-time synthesis SDE.
We make the following technical contributions:
We extensively validate CLD and the new SDE solver:


Generated samples for CIFAR-10 (left) and CelebA-HQ-256 (right). CLD-based SGMs generate sharp, high-quality, and diverse samples.
The sequence above is generated by randomly traversing the latent space of our CLD-SGM model (using the probability flow ODE formulation).

Visualization of the generation paths of samples from our CelebA-HQ-256 model (synthesis uses only 150 steps). Odd and even rows visualize data and velocity variables, respectively. The eight columns correspond to times \(t \in \{1.0, 0.5, 0.3, 0.2, 0.1, 10^{-2}, 10^{-3}, 10^{-5}\}\) (from left to right). The velocity distribution converges to a Normal (different variances) for both \(t \to 0\) and \(t \to 1\). See Appendix F.3 in our paper for visualization details and discussion.

Score-Based Generative Modeling with Critically-Damped Langevin Diffusion
Tim Dockhorn, Arash Vahdat, Karsten Kreis
International Conference on Learning Representations (ICLR), 2022 (spotlight)
@inproceedings{dockhorn2022score,
title={Score-Based Generative Modeling with Critically-Damped Langevin Diffusion},
author={Tim Dockhorn and Arash Vahdat and Karsten Kreis},
booktitle={International Conference on Learning Representations (ICLR)},
year={2022}
}