
|
|
|
|
|
|
|
|
|
|
|
|
|
Many machine learning models operate on images, but ignore the fact that images are 2D projections formed by 3D geometry interacting with light, in a process called rendering. Enabling ML models to understand image formation might be key for generalization. However, due to an essential rasterization step involving discrete assignment operations, rendering pipelines are non-differentiable and thus largely inaccessible to gradient-based ML techniques. In this paper, we present DIB-R, a differentiable rendering framework which allows gradients to be analytically computed for all pixels in an image. Key to our approach is to view foreground rasterization as a weighted interpolation of local properties and background rasterization as an distance-based aggregation of global geometry. Our approach allows for accurate optimization over vertex positions, colors, normals, light directions and texture coordinates through a variety of lighting models. We showcase our approach in two ML applications: single-image 3D object prediction, and 3D textured object generation, both trained using exclusively using 2D supervision.
 |
Wenzheng Chen, Jun Gao*, Huan Ling*, Edward J. Smith*, Jaakko Lehtinen, Alec Jacobson, Sanja Fidler Learning to Predict 3D Objects with an Interpolation-based Differentiable Renderer |
|
|
|
|
|
 |
|
 |
|
 |
|
 |
|
Predicting 3D Objects from Single Images: Geometry and Color.
The first column is the ground-truth image, the second and third columns are the prediction from our model, the forth and fifth column are results from SoftRas-Mesh, the last two columns are results from N3MR. |
 |
 |
 |
|||
 |
 |
 |
|
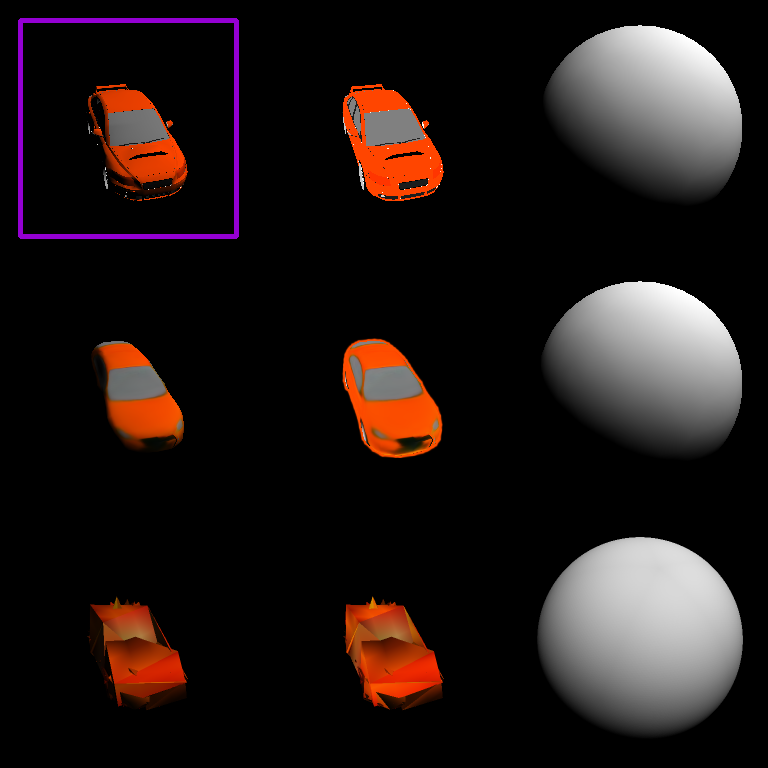
Predicting 3D Objects from Single Images: Geometry, Texture and Light
For every 3x3 grid, the purple rectangle shows the input image. The first row is Ground Truth, the second row is prediction with DIB-R and the third tow is prediction from N3MR. The first column shows shapes that are rendered with texture and light, the second column shows shapes that are rendered with texture only. And the third column show the light. |
|
|
|
Texture and Lighting Results (Phong model)
The first column is the rendered image, second column is predicted shape, third column is predicted texture, forth column is rendered car and last column is the predicted light. |
 |
|
 |
|
Texture and Lighting Results (Spherical Harmonic Model)
For every 3x9 grid, the purple rectangle shows the input image. The first row shows the Ground Truth. The second row show prediction with adversarial loss. And the third row shows prediction without adversarial loss. The first column shows shapes that are rendered with texture and light. The second column shows shapes that are rendered withh texture only. The third column shows the predicted light. The forth to ninth column show shapes that are rendered with texture only from different views. |
 |
|
Real Images
Qualitative results on CUB bird dataset. The first row shows GT image and mask, Our predictions and CMR predictions, respectively. The second row shows the learned shape and texture rendered in multiple views. |
|
|
|
3D GAN of Textured Shapes via 2D Supervision.
|
|
|