While modern machine learning models rely on increasingly large training datasets, data is often limited in privacy-sensitive domains. Generative models trained with differential privacy (DP) on sensitive data can sidestep this challenge, providing access to synthetic data instead. However, training DP generative models is highly challenging due to the noise injected into training to enforce DP. We propose to leverage diffusion models (DMs), an emerging class of deep generative models, and introduce Differentially Private Diffusion Models (DPDMs), which enforce privacy using differentially private stochastic gradient descent (DP-SGD). We motivate why DP-SGD is well suited for training DPDMs, and thoroughly investigate the DM parameterization and the sampling algorithm, which turn out to be crucial ingredients in DPDMs. Furthermore, we propose noise multiplicity, a simple yet powerful modification of the DM training objective tailored to the DP setting to boost performance. We validate our novel DPDMs on widely-used image generation benchmarks and achieve state-of-the-art (SOTA) performance by large margins. For example, on MNIST we improve the SOTA FID from 48.4 to 5.01 and downstream classification accuracy from 83.2% to 98.1% for the privacy setting DP-\((\varepsilon{=}10, \delta{=}10^{-5})\). Moreover, on standard benchmarks, classifiers trained on DPDM-generated synthetic data perform on par with task-specific DP-SGD-trained classifiers, which has not been demonstrated before for DP generative models.
Modern deep learning usually requires significant amounts of training data. However, sourcing large datasets in privacy-sensitive domains is often difficult. To circumvent this challenge, generative models trained on sensitive data can provide access to large synthetic data instead, which can be used flexibly to train downstream models. Unfortunately, typical overparameterized neural networks have been shown to provide little to no privacy to the data they have been trained on. For example, an adversary may be able to recover training images of deep classifiers using gradients of the networks. Generative models may even overfit directly, generating data indistinguishable from the data they have been trained on. In fact, overfitting and privacy-leakage of generative models are more relevant than ever, considering recent works that train powerful photo-realistic image generators on large-scale Internet-scraped data. Since the latest variants of these impressive image generation systems leverage diffusion models, advancing specifically diffusion model-based generative modeling with privacy guarantees is a pressing topic.
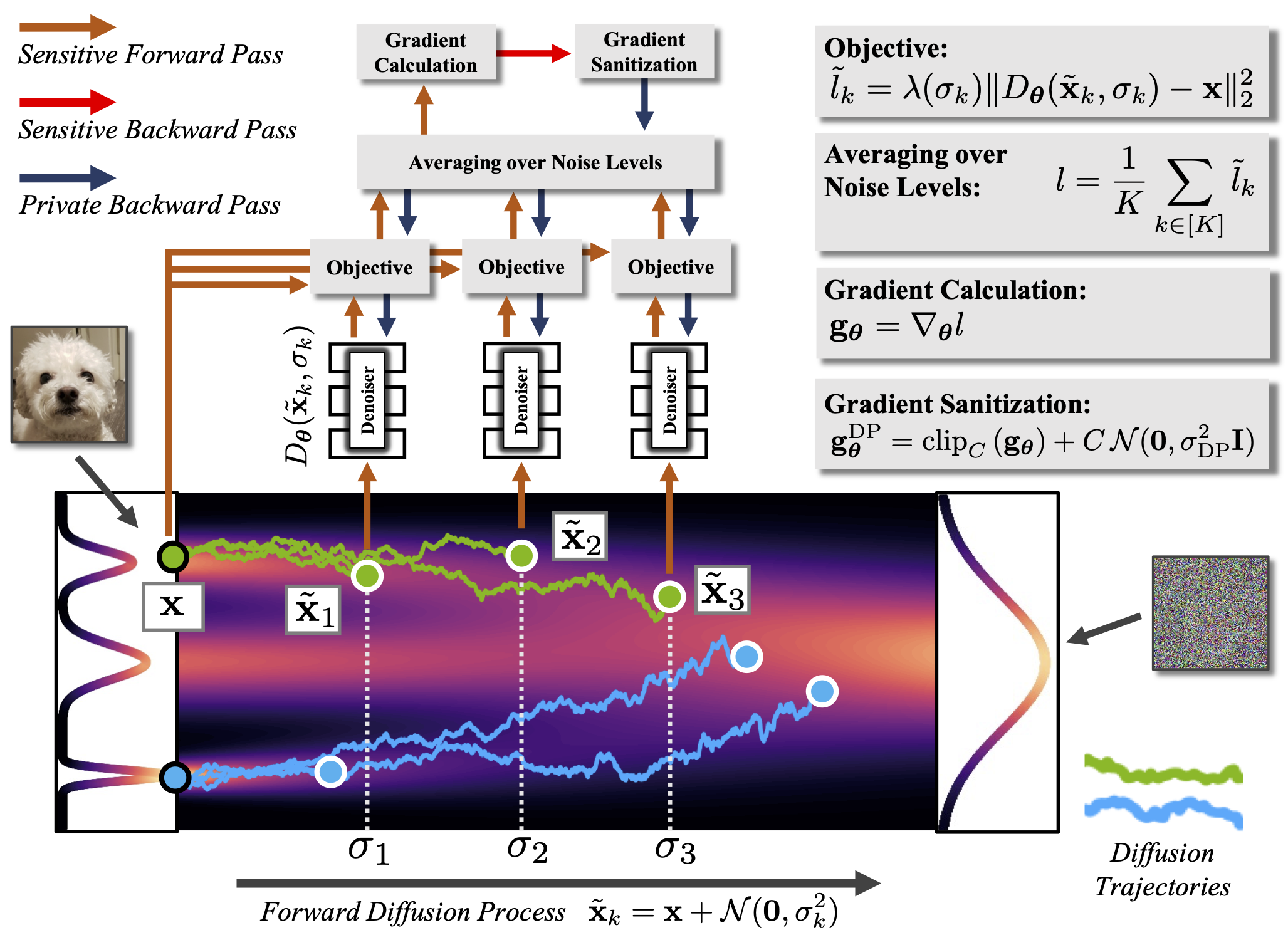
In this work, we propose Differentially Private Diffusion Models (DPDMs), diffusion models (DMs) trained with rigorous DP guarantees based on differentially private stochastic gradient descent (DP-SGD). Privacy in DP-SGD is enforced by clipping and noising parameter gradients. We motivate why DMs are uniquely well suited for DP generative modeling, and we study DPDM parameterization, training setting and model sampling in detail, and optimize it for the DP setup. We propose noise multiplicity to efficiently boost DPDM performance (see Figure above). Experimentally, we significantly surpass the state-of-the-art in DP synthesis on widely-studied image modeling benchmarks and we demonstrate that classifiers trained on DPDM-generated data perform on par with task-specific DP-trained discriminative models. This implies a very high utility of the synthetic data generated by DPDMs, delivering on the promise of DP generative models as an effective data sharing medium.
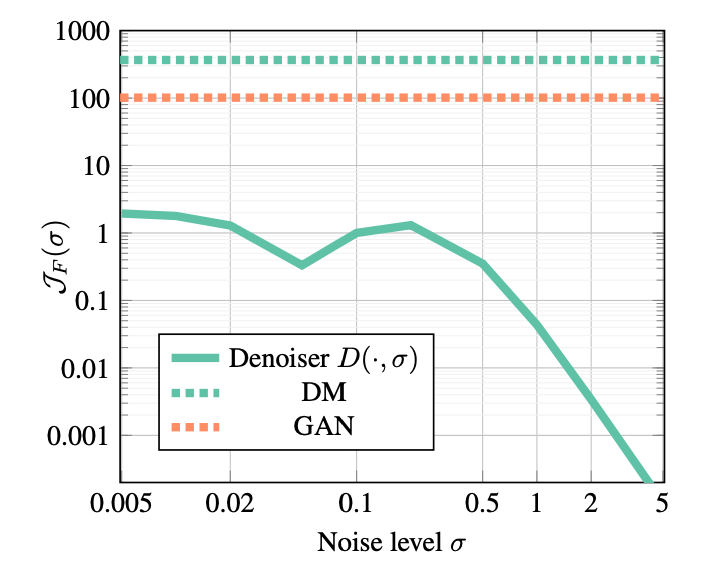
Frobenius norm of the Jacobian \(\mathcal{J}_F(\sigma)\) (measure of complexity) of the denoiser \(D\) at noise level \(\sigma\) and constant Frobenius norms of the Jacobians \(\mathcal{J}_F\) of the end-to-end sampling function defined by the DM as well as the one-shot synthesis network of a GAN. Less complex functions require smaller neural networks, which is beneficial for DP generative modeling; see paragraph below.
Sequential denoising. The sampling function in DMs is defined through a sequential denoising process, breaking the difficult generation task into many small denoising steps. We found that the denoiser \(D\), the learnable component in DMs, is significantly less complex than the one-shot synthesis neural network learned by a GAN or the end-to-end multi-step synthesis process of the DM (see Figure above). Generally, more complex functions require larger neural networks and are more difficult to learn. Importantly, the magnitude of the noise added in the DP-SGD updates scales linearly with the number of parameters, and therefore smaller networks are generally preferred. Consequently, DMs are well-suited for DP generative modeling with DP-SGD, considering the lower neural network complexity required in the denoiser.
Objective function. GANs are currently the predimomant class of generative models explored in DP generative modeling, despite them being difficult to optimize and prone to mode collapse due to their adversarial training scheme. This can be particularly problematic during noisy DP-SGD training. In contrast, DMs are trained with a simple regression-like \(L_2\)-loss which makes them robust and scalable in practice, and therefore arguably better-suited for DP-SGD-based training.
Stochastic diffusion model sampling. Generating samples from DMs with stochastic sampling can perform better than deterministic sampling when the score model is not learned well. Since we replace gradient estimates in DP-SGD training with biased large variance estimators, we cannot expect a perfectly accurate score model. We empirically show that stochastic sampling can in fact boost perceptual synthesis quality in DPDMs as measured by Fréchet Inception Distance (FID).
Noise multiplicity. When training DMs with DP-SGD, we incur a privacy
cost for each iteration, and therefore prefer a smaller number of iterations than in the non-DP setting. Furthermore, since the
per-example gradient clipping as well as the noise injection induce additional variance in DP-SGD, we would
like our objective function to be less noisy than in the non-DP case. We achieve this through
Noise level sampling during training. Especially for high privacy settings (small DP-\(\varepsilon\)), we found it important to focus training of the denoiser, the learnable component in DMs, on high noise levels \(\sigma\). It is known that at large \(\sigma\) the DM learns the global coarse structure of the data, which is crucial to form visually coherent images that can also be used to train downstream models. This is relatively easy to achieve in the non-DP setting, due to the heavily smoothed diffused distribution at these high noise levels \(\sigma\). At high privacy levels, however, even training at such high noise levels \(\sigma\) can be challenging due to DP-SGD's gradient clipping and noising.
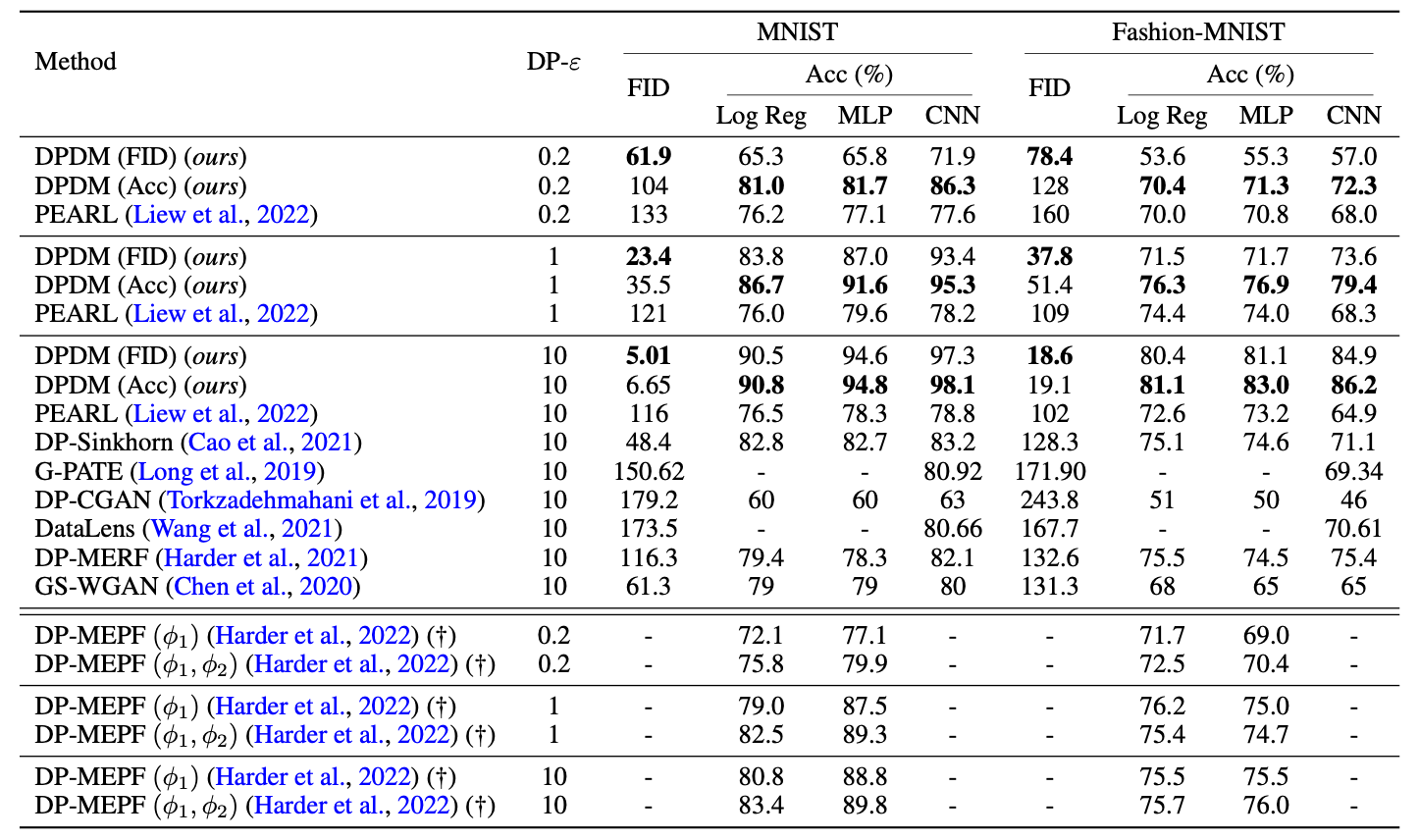
We extensively validate our DPDMs on several popular DP benchmark datasets, namely, (conditional) MNIST, (conditional) Fashion-MNIST, and (unconditional) CelebA (downsampled to 32x32 resolution). We measure sample quality via FID. On MNIST and Fashion-MNIST, we also assess utility of class-labeled generated data by training classifiers on synthesized samples and compute class prediction accuracy on real data. As is standard practice, we consider logistic regression (Log Reg), MLP, and CNN classifiers; see paper for details.

(Above) MNIST and Fashion-MNIST images generated by existing methods (above black line) and our DPDM (below black line). The DP privacy setting is \((\varepsilon{=}10, \delta{=}10^{-5})\). (Below) Class-conditional DP image generation performance (MNIST & Fashion-MNIST) measured in FID and downstream classifier utility (\(\delta{=}10^{-5}\) and three \(\varepsilon\)). DP-MEPF (†) uses additional public data for training (only included for completeness).

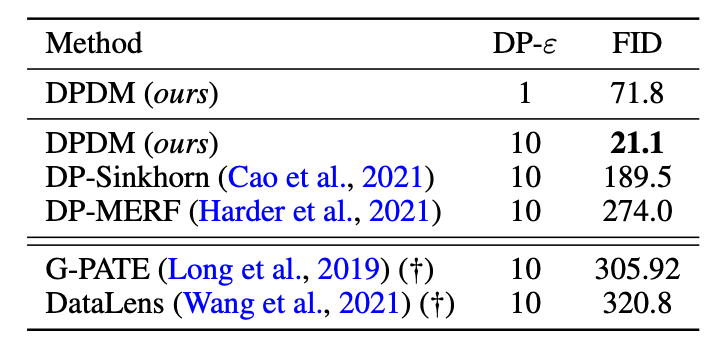
(Above) CelebA images generated by existing methods (above black line) and our DPDM (below black line). The DP privacy setting is \((\varepsilon{=}10, \delta{=}10^{-6})\). (Below) DP image generation performance on CelebA measured in FID (\(\delta{=}10^{-6}\) and two \(\varepsilon\)). G-PATE and DataLens (†) use \(\delta{=}10^{-5}\) (less privacy) and model images at 64x64 resolution.

Differentially Private Diffusion Models
Tim Dockhorn, Tianshi Cao, Arash Vahdat, Karsten Kreis
Transactions on Machine Learning Research, 2023
@article{dockhorn2022differentially,
title={{Differentially Private Diffusion Models}},
author={Tim Dockhorn and Tianshi Cao and Arash Vahdat and Karsten Kreis},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2023},
url={https://openreview.net/forum?id=ZPpQk7FJXF}
}