Toronto AI Lab
Toronto AI Lab
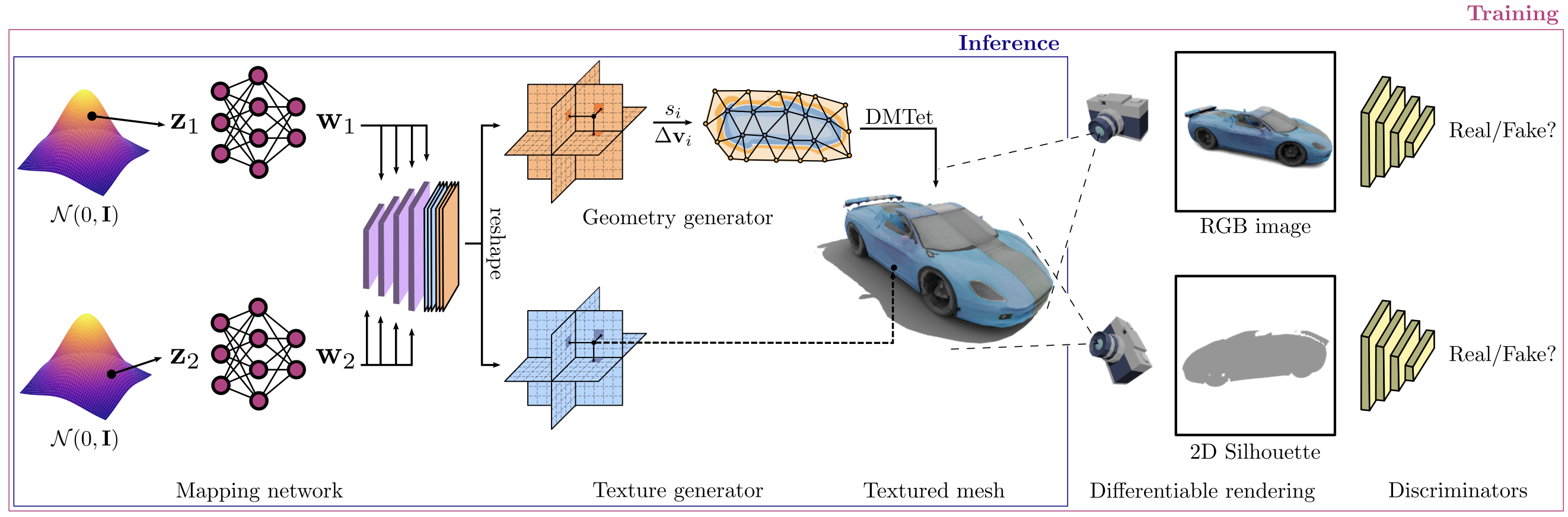
As several industries are moving towards modeling massive 3D virtual worlds, the need for content creation tools that can scale in terms of the quantity, quality, and diversity of 3D content is becoming evident. In our work, we aim to train performant 3D generative models that synthesize textured meshes which can be directly consumed by 3D rendering engines, thus immediately usable in downstream applications. Prior works on 3D generative modeling either lack geometric details, are limited in the mesh topology they can produce, typically do not support textures, or utilize neural renderers in the synthesis process, which makes their use in common 3D software non-trivial. In this work, we introduce GET3D, a Generative model that directly generates Explicit Textured 3D meshes with complex topology, rich geometric details, and high fidelity textures. We bridge recent success in the differentiable surface modeling, differentiable rendering as well as 2D Generative Adversarial Networks to train our model from 2D image collections. GET3D is able to generate high-quality 3D textured meshes, ranging from cars, chairs, animals, motorbikes and human characters to buildings, achieving significant improvements over previous methods.

GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images
Jun Gao, Tianchang Shen, Zian Wang, Wenzheng Chen, Kangxue Yin, Daiqing Li, Or Litany, Zan Gojcic, Sanja Fidler
Qualitative results on unconditional 3D generation. We highlight the diversity and quality of our generated 3D meshes with textures, including: 1. wheels on the legs of the chairs; 2. wheels, all the lights and windows for the cars; 3. mouse, ears, horns for the animals; 4. back mirrors, wireframes on the tires for the motorbike, 5. the high-heeled shoes, cloths for humans
In each row, we show shapes generated from the same geometry latent code, while changing the texture latent code. In each column, we show shapes generated from the same texture latent code, while changing the geometry code. Our model achieves a good disentanglement between geometry and texture.
In each row, we show shapes generated from the same texture latent code, while interpolating the geometry latent code from left to right. In each column, we show shapes generated from the same geometry latent code, while interpolating the texture code from top to bottom. This result demonstrates a meaningful interpolation for each of them.
In each subfigure, we apply a random walk in the latent space and generate corresponding 3D shapes. GET3D is able to generate a smooth transition between different shapes for all categories.
In each row, we locally perturb the latent code by adding a small noise. In this way, GET3D is able to generate similar looking shapes with slight difference locally.
Combined with DIBR++, GET3D is able to generate materials and produce meaningful view-dependent lighting effects in a completely unsupervised manner.
Text-guided shape generation. We follow recent work StyleGAN-NADA , where users provide a text and we finetune our 3D generator by computing the directional CLIP loss on the rendered 2D images and the provided texts from the users. Our model generates a large amount of meaningful shapes with text prompts from the users.
@inproceedings{gao2022get3d,
title={GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images},
author={Jun Gao and Tianchang Shen and Zian Wang and Wenzheng Chen and Kangxue Yin
and Daiqing Li and Or Litany and Zan Gojcic and Sanja Fidler},
booktitle={Advances In Neural Information Processing Systems},
year={2022}
}
GET3D builds upon several previous works:
Please also consider citing these papers if you follow our work.
@inproceedings{dmtet,
title = {Deep Marching Tetrahedra: a Hybrid Representation for High-Resolution 3D Shape Synthesis},
author = {Tianchang Shen and Jun Gao and Kangxue Yin and Ming-Yu Liu and Sanja Fidler},
year = {2021},
booktitle = {Advances in Neural Information Processing Systems}
}
@inproceedings{nvdiffrec,
title={Extracting Triangular 3D Models, Materials, and Lighting From Images},
author={Munkberg, Jacob and Hasselgren, Jon and Shen, Tianchang and Gao, Jun and Chen, Wenzheng and
Evans, Alex and M{\"u}ller, Thomas and Fidler, Sanja},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={8280--8290},
year={2022}
}
For business inquiries, please visit our website and submit the form: NVIDIA Research Licensing