Toronto AI Lab
Toronto AI Lab
|
Spotlight paper at International Conference on Learning Representations (ICLR) 2024 |
|
What if neural nets could process, analyze, interpret, and edit other neural nets' weights? We design metanets capable of processing diverse input neural net architectures, with provable guarantees. |
|
Abstract: Neural networks efficiently encode learned information within their parameters. Consequently, many tasks can be unified by treating neural networks themselves as input data. When doing so, recent studies demonstrated the importance of accounting for the symmetries and geometry of parameter spaces. However, those works developed architectures tailored to specific networks such as MLPs and CNNs without normalization layers, and generalizing such architectures to other types of networks can be challenging. In this work, we overcome these challenges by building new metanetworks — neural networks that take weights from other neural networks as input. Put simply, we carefully build graphs representing the input neural networks and process the graphs using graph neural networks. Our approach, Graph Metanetworks (GMNs), generalizes to neural architectures where competing methods struggle, such as multi-head attention layers, normalization layers, convolutional layers, ResNet blocks, and group-equivariant linear layers. We prove that GMNs are expressive and equivariant to parameter permutation symmetries that leave the input neural network functions unchanged. We validate the effectiveness of our method on several metanetwork tasks over diverse neural network architectures. |

|
Derek Lim, Haggai Maron, Marc T. Law,
Jonathan Lorraine, James Lucas Graph Metanetworks for Processing Diverse Neural Architectures 
|
|
What if neural nets could process, analyze, interpret, and edit other neural nets' weights? These models, termed metanetworks, are extremely versatile and useful. For instance, metanets have been used for learned optimization (map [params, gradients] → new params), 3D data generation (generating INR weights), analyzing parameter spaces (predict hyperparameters from weights), and more.
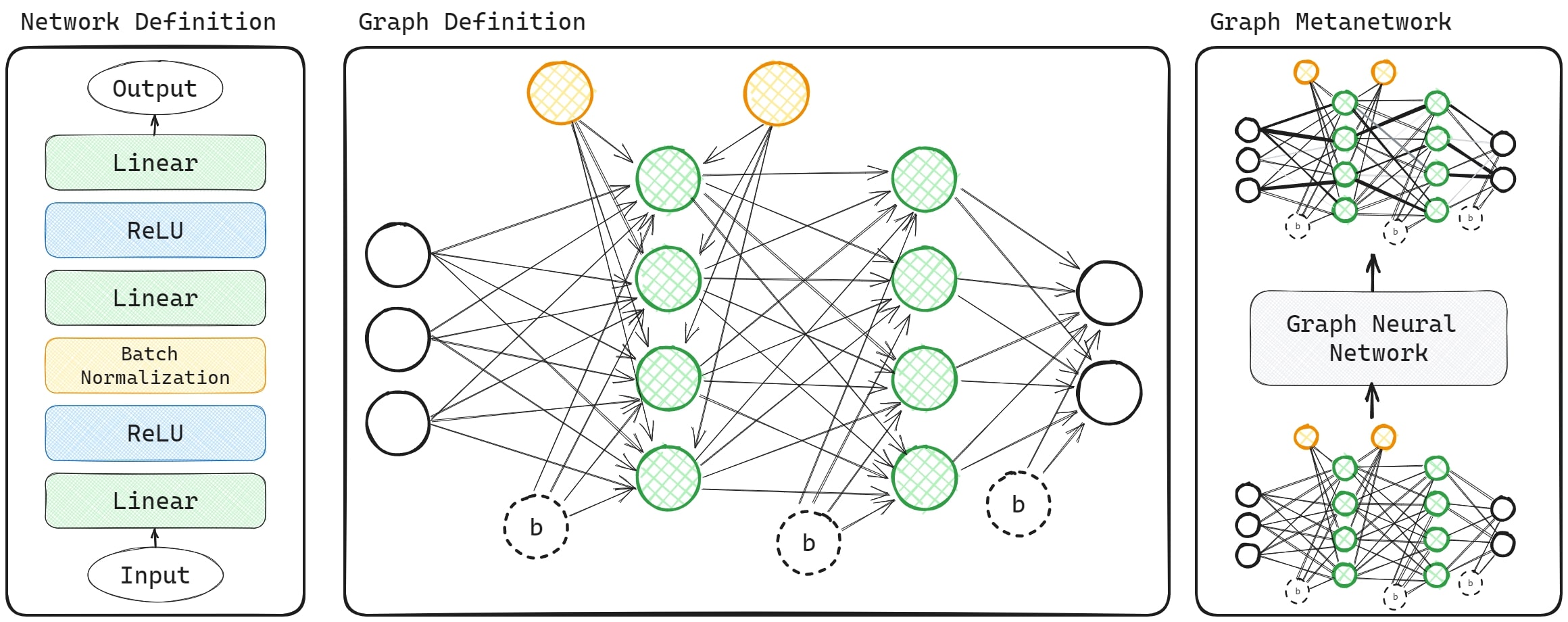
We develop Graph Metanetworks (GMNs). GMNs are metanetworks that operate on neural architectures while respecting parameter symmetries. To achieve this we,
|
|
Crucially, our design allows a single metanet to operate on a diverse set of neural architectures. |
|
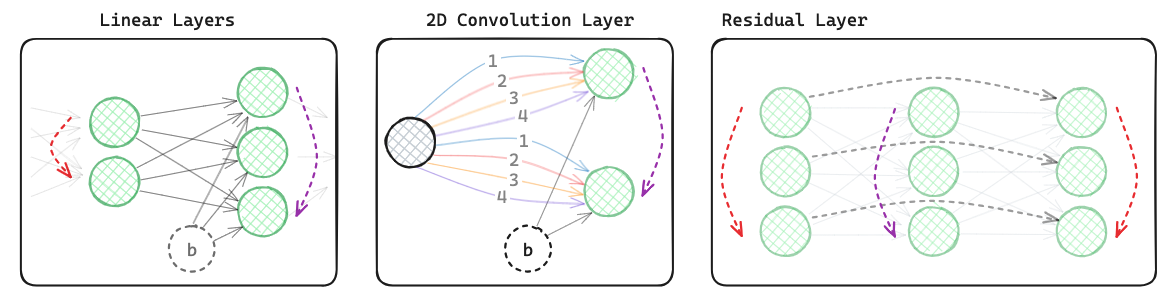
We develop procedures to turn many types of layers into graphs, such as: multihead attention, convolutions, linear, residual, group equivariant linear, spatial grid, and normalization layers. We experimentally process small ViTs, ResNets, DeepSets, and other input nets. |
|
Theoretically, we prove that our GMNs are equivariant/invariant to computation graph automorphisms of the inputs, which correspond to permutation parameter symmetries (e.g. permuting hidden neurons in MLPs, hidden channels in CNNs). |
|
Propositions 1&2 (informal): Graph Metanets are equivariant to parameter permutation symmetries. We prove that our GMNs are able to express existing metanets. Proposition 3: On MLP inputs (where parameter graphs and computation graphs coincide), Graph Metanets can express StatNN and NP-NFN. They can even simulate the forward pass of any network defined as a computation graph. This means they are at least as expressive as the input networks they operate on. Proposition 4: On computation graph inputs, graph metanets can express the forward pass of any input feedforward neural network. |
|
We empirically show that our GMNs improve over previous metanets on several tasks:
|
| Varying CNNs | Diverse Architectures | ||||
|---|---|---|---|---|---|
| R2 | τ | R2 | τ | ||
| 50% | DeepSets | 0.778 ± 0.002 | 0.697 ± 0.002 | 0.562 ± 0.020 | 0.559 ± 0.011 |
| DMC | 0.948 ± 0.009 | 0.876 ± 0.003 | 0.957 ± 0.009 | 0.883 ± 0.007 | |
| GMN (Ours) | 0.978 ± 0.002 | 0.915 ± 0.006 | 0.975 ± 0.002 | 0.908 ± 0.004 | |
| 5% | DeepSets | 0.692 ± 0.006 | 0.648 ± 0.002 | 0.126 ± 0.015 | 0.290 ± 0.010 |
| DMC | 0.816 ± 0.038 | 0.762 ± 0.014 | 0.810 ± 0.046 | 0.758 ± 0.013 | |
| GMN (Ours) | 0.876 ± 0.010 | 0.797 ± 0.005 | 0.918 ± 0.002 | 0.828 ± 0.005 | |
| OOD | DeepSets | 0.741 ± 0.015 | 0.683 ± 0.005 | 0.128 ± 0.071 | 0.380 ± 0.014 |
| DMC | 0.387 ± 0.229 | 0.760 ± 0.024 | -0.134 ± 0.147 | 0.566 ± 0.055 | |
| GMN (Ours) | 0.891 ± 0.037 | 0.870 ± 0.010 | 0.768 ± 0.063 | 0.780 ± 0.030 | |
|
Citation
|
|
Derek Lim, Haggai Maron, Marc T. Law, Jonathan Lorraine, James Lucas
@inproceedings{lim2024graph,
|