Toronto AI Lab
Toronto AI Lab
|
We improve diffusion models by distilling into multiple students, allowing (a) improved quality by specializing in data subsets and (b) improved latency by distilling into smaller models, allowing 1-step generation, now additionally with smaller, lower-latency architectures. |
|
Abstract: Diffusion models achieve high-quality sample generation at the cost of a lengthy multistep inference procedure. To overcome this, diffusion distillation techniques produce student generators capable of matching or surpassing the teacher in a single step. However, the student model’s inference speed is limited by the size of the teacher architecture, preventing real-time generation for computationally heavy applications. In this work, we introduce Multi-Student Distillation (MSD), a framework to distill a conditional teacher diffusion model into multiple single- step generators. Each student generator is responsible for a subset of the con- ditioning data, thereby obtaining higher generation quality for the same capacity. MSD trains multiple distilled students allowing smaller sizes and, therefore, faster inference. Also, MSD offers a lightweight quality boost over single-student dis- tillation with the same architecture. We demonstrate MSD is effective by training multiple same-sized or smaller students on single-step distillation using distribu- tion matching and adversarial distillation techniques. With smaller students, MSD gets competitive results with faster inference for single-step generation. Using 4 same-sized students, MSD sets a new state-of-the-art for one-step image genera- tion: FID 1.20 on ImageNet-64×64 and 8.20 on zero-shot COCO2014. |

|
Yanke Song, Jonathan Lorraine, Weili Nie,
Karsten Kreis, James Lucas Multi-student Diffusion Distillation for Better One-step Generators |
|
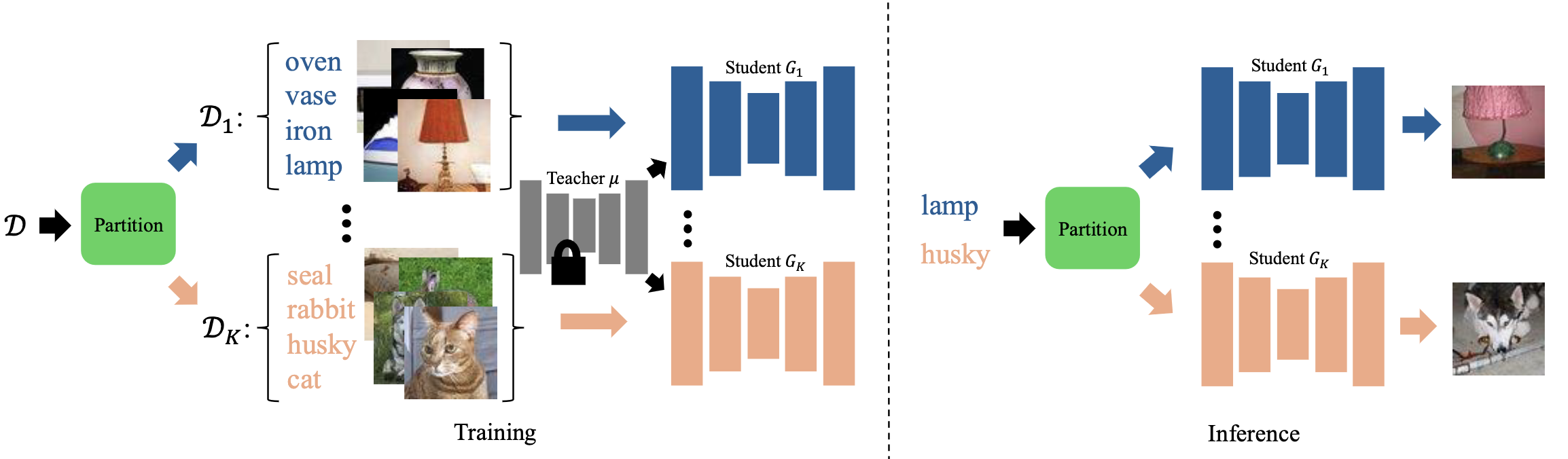
Recent works have used Knowledge Distillation to accelerate the sampling of multi-step diffusion models. Specifically, Distribution Matching and Adversarial Distillation have obtain one-step generators with comparable or better performance than the teacher. However, these methods must use an identical architecture, so they (a) have limited network capacity and quality for the more difficult one-step generation and (b) can not go faster than a single forward pass of the teacher. Can we make these models both better and faster? We present Multi-Student Distillation (MSD), which distills multiple students from the teacher. At training time, MSD partitions the input condition set, filters the corresponding dataset and assigns them to different students; During inference time, MSD uses only one student. In this way, MSD effectively increases the model's total capacity and, therefore, performance without incurring additional inference latency. |
|
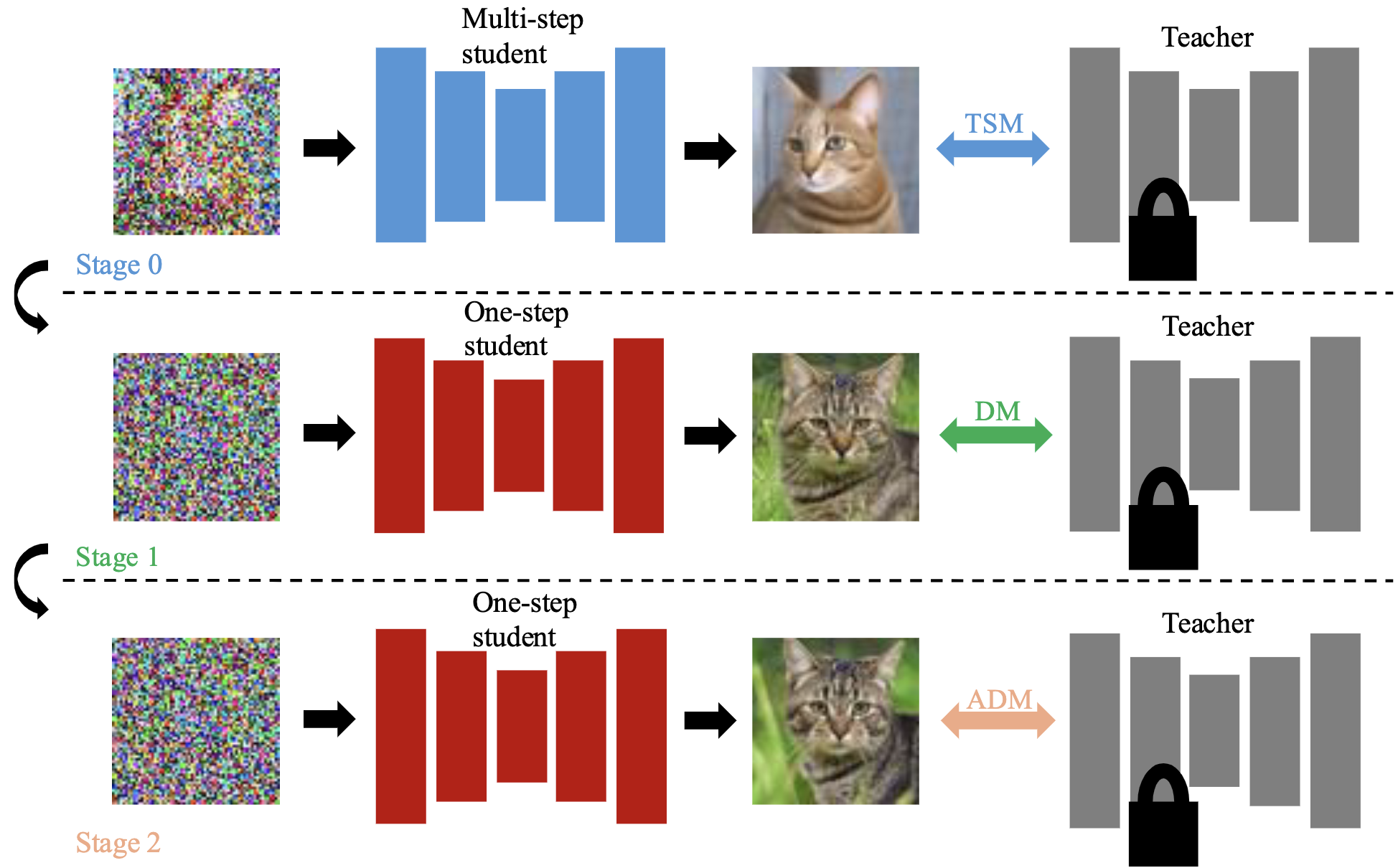
The inference speed of one-step generators are still bounded by its model size. We want to distill into a smaller student, which incurs additional challenges, such as initializing the student. We show that the issue can be resolved by prepending an additional teacher score matching (TSM) stage that trains multi-step students to emulate the teacher score estimation, which provides useful weight initializations for the following distillation stages. |
|
By training 4 students of the same architecture, we show that MSD improves upon single-student counterparts. This is measured by FID scores on: 1) Class-conditional image generation on ImageNet-64×64 and 2) Text-to-image generation on zero-shot COCO2014. |
| ImageNet-64×64 | COCO2014 | |
|---|---|---|
| DMD | 2.62 | 11.49 |
| MSD4-DM (ours) | 2.37 | 8.80 |
| DMD2 | 1.28 | 8.35 |
| MSD4-AMD (ours) | 1.20 | 8.20 |
|
In addition, we achieve competitive generation quality by distilling smaller students from scratch (figure on top). |
|
Citation |
|
Yanke Song, Jonathan Lorraine, Weili Nie, Karsten Kreis, James Lucas
@inproceedings{song2024multistudent,
|