Toronto AI Lab
Toronto AI Lab
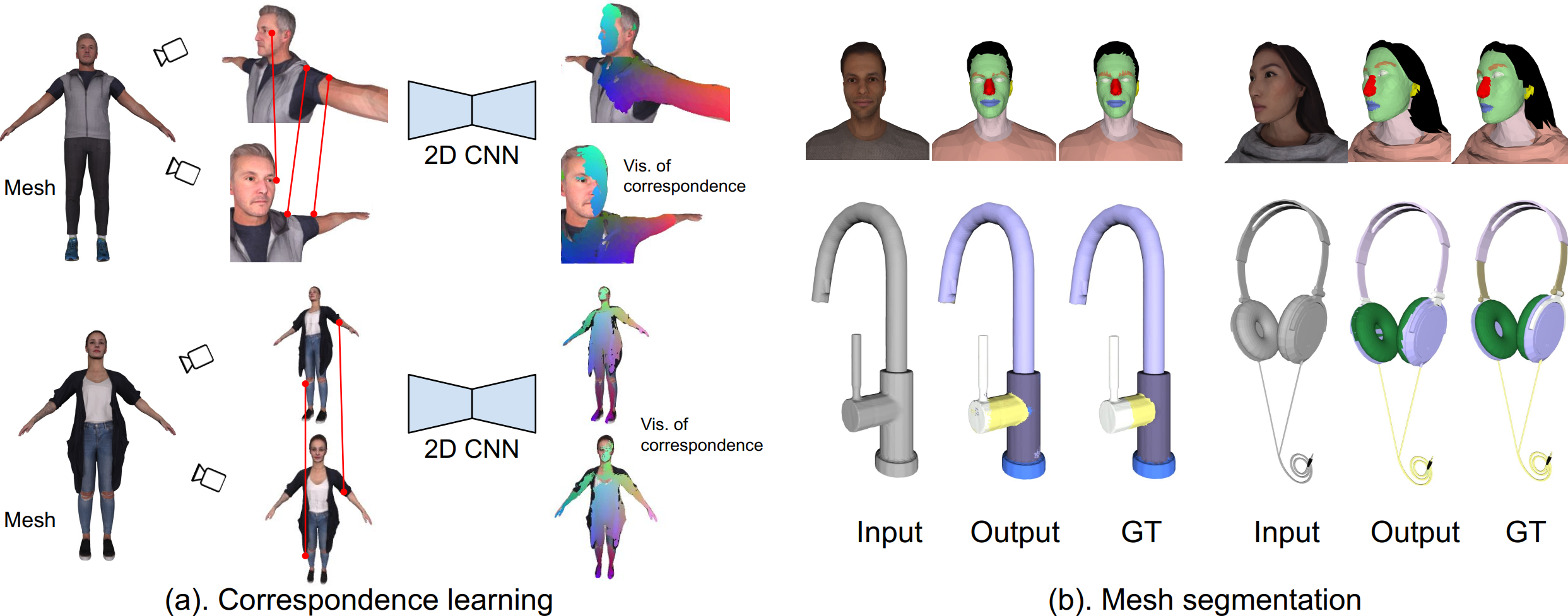
We propose to utilize self-supervised techniques in the 2D domain for fine-grained 3D shape segmentation tasks. This is inspired by the observation that view-based surface representations are more effective at modeling high-resolution surface details and texture than their 3D counterparts based on point clouds or voxel occupancy. Specifically, given a 3D shape, we render it from multiple views, and set up a dense correspondence learning task within the contrastive learning framework. As a result, the learned 2D representations are view-invariant and geometrically consistent, leading to better generalization when trained on a limited number of labeled shapes compared to alternatives that utilize self-supervision in 2D or 3D alone. Experiments on textured (RenderPeople) and untextured (PartNet) 3D datasets show that our method outperforms state-of-the-art alternatives in fine-grained part segmentation. The improvements over baselines are greater when only a sparse set of views is available for training or when shapes are textured, indicating that MvDeCor benefits from both 2D processing and 3D geometric reasoning.
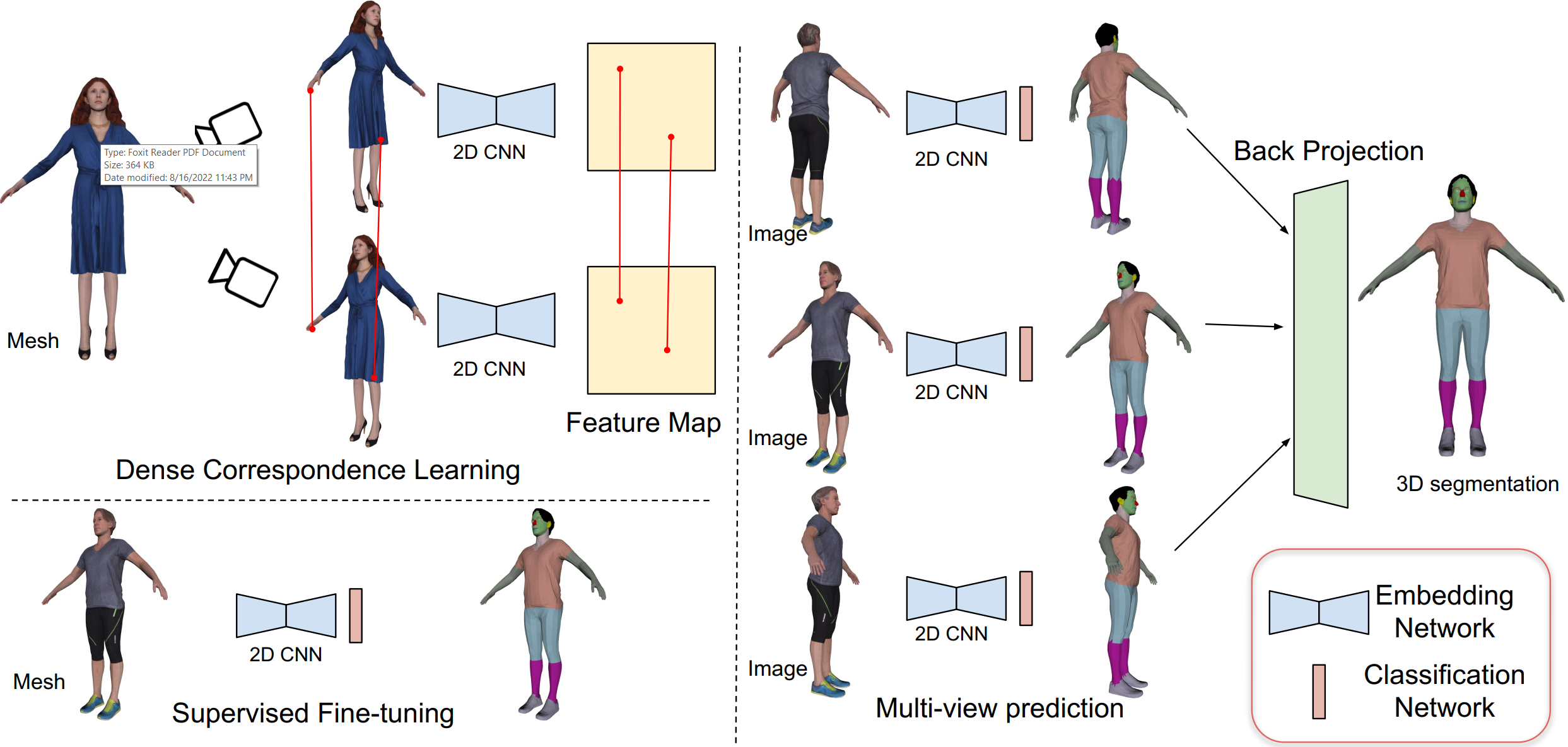
Top left: Our self-supervision approach takes two overlapping views (RGB image, with optional normal and depth maps) of a 3D shape and passes it through a network that produces per-pixel embeddings. We define a dense contrastive loss promoting similarity between matched pixels and minimizing similarity between un-matched pixels. Bottom left: Once the network is trained we add a segmentation head and fine-tune the entire architecture on a few labeled examples to predict per-pixel semantic labels. Right: Labels predicted by the 2D network for each view are back-projected to the 3D surface and aggregated using a voting scheme.
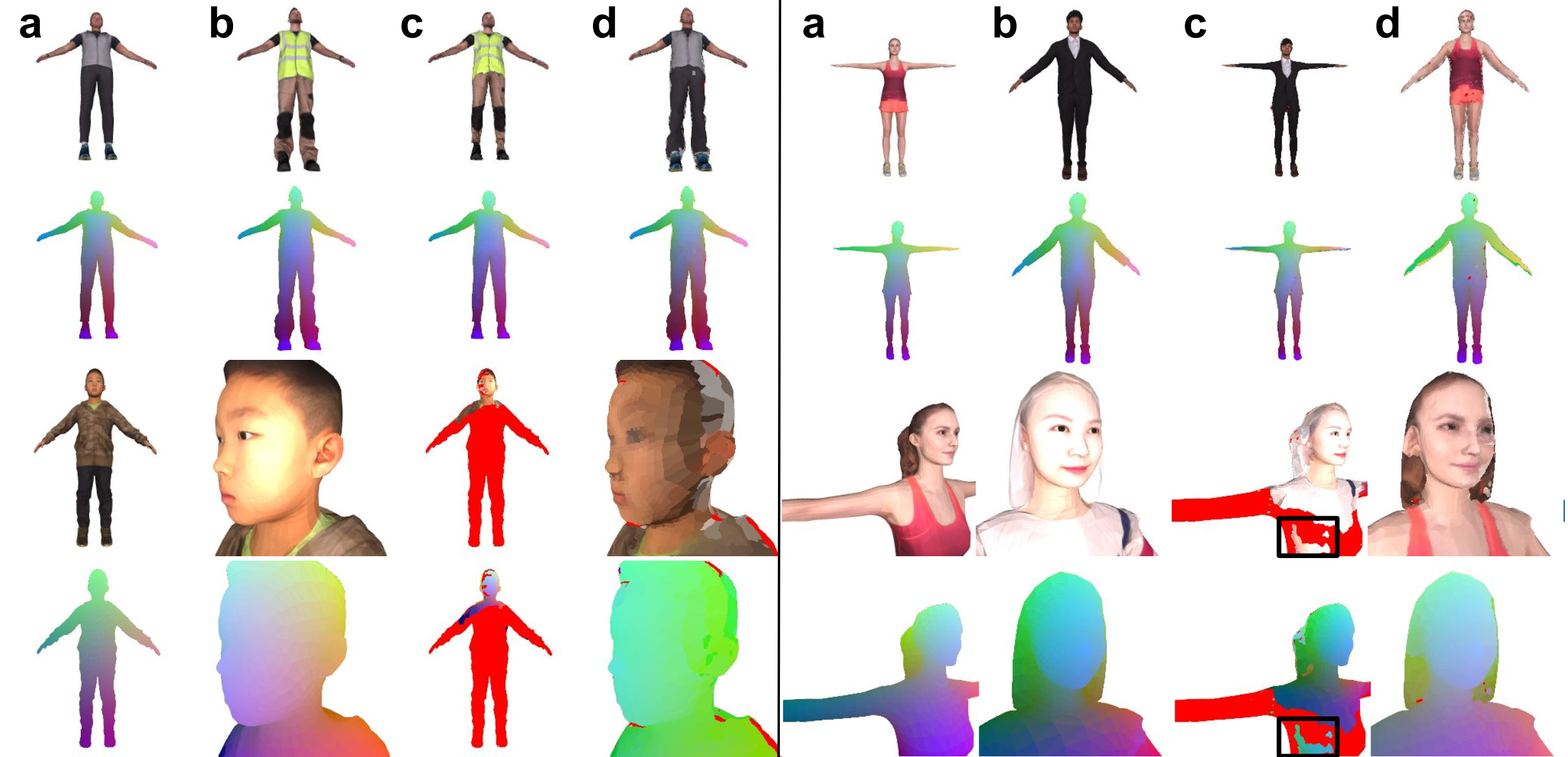
Visualization of learned embeddings. Given a pair of images in (a) and
(b), our network produces per-pixel embedding for each image. We map pixels from
(b) to (a) according to feature similarity, resulting in (c). Similarly (d) is generated by
transferring texture from (a) to (b). For pixels which have similarity below a threshold are colored red. We visualize the smoothness of our learned correspondence in the
second and forth row. Our method learns to produce correct correspondences between
human subject in different clothing and same human subject in different camera poses
(left). Our approach also finds correct correspondences between different human subjects in different poses (right). Mistakes are highlighted using black boxes.
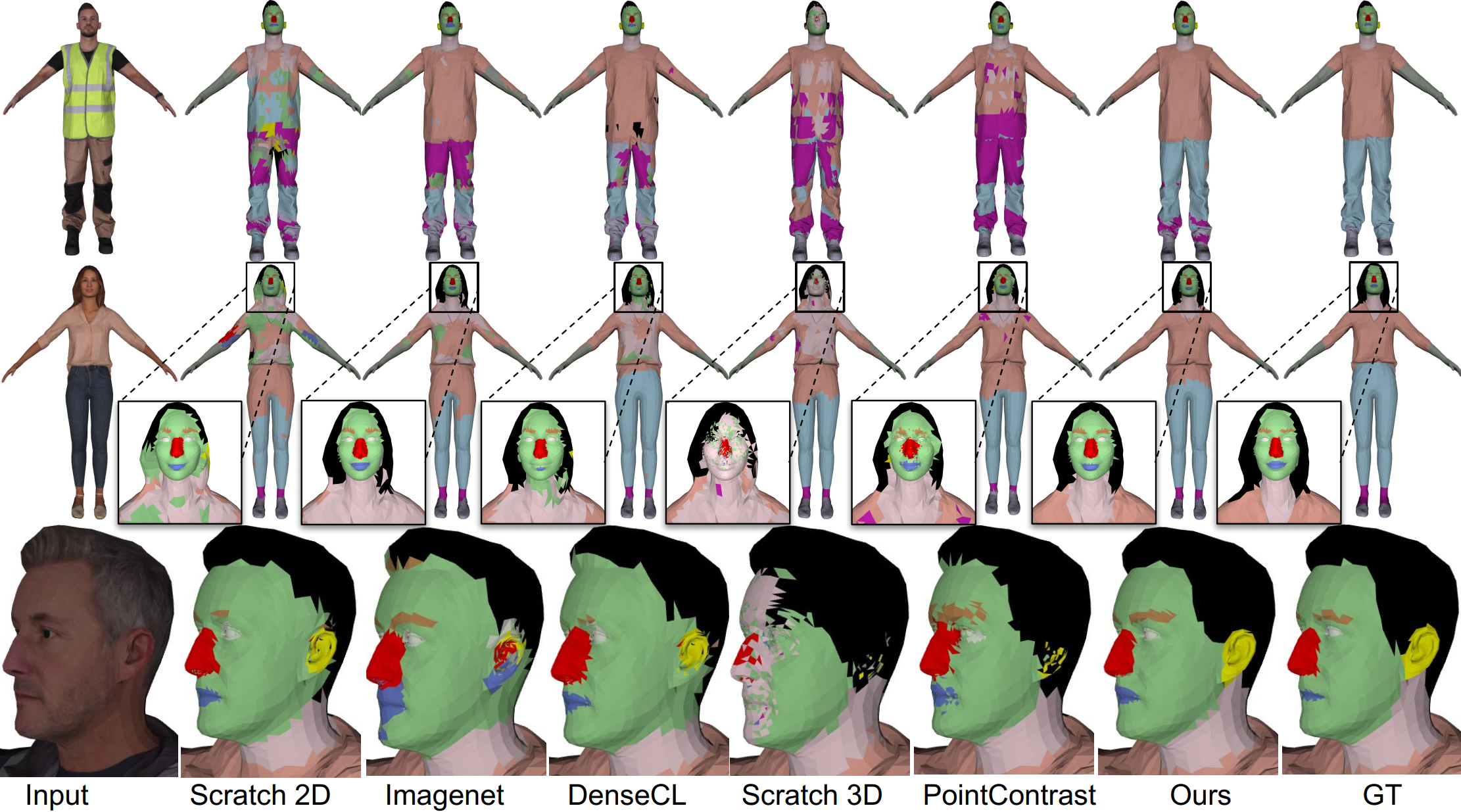
Visualization of predicted semantic labels on the Renderpeople dataset in the few-shot setting when k = 5 fully labeled shapes are used for fine-tuning. We visualize the predictions of all baselines. Our method produces accurate semantic labels for 3D shapes even for small parts, such as ears and eyebrows.
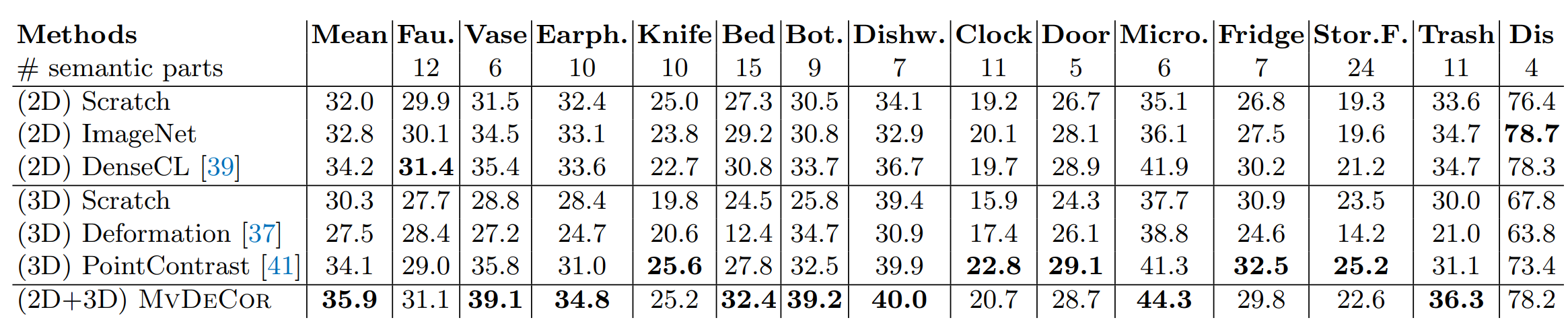
Few-shot segmentation on the Partnet dataset with k=10 labeled
shapes. 10 fully labeled shapes are provided for training. Evaluation is done on the
test set of PartNet using the mean part-iou metric (%). Training is done per category
separately. Results are reported by averaging over 5 random runs.
Note that evaluation on Chairs, Lamps and
Tables categories is shown separately in the Table below with k = 30, because our randomly selected k = 10 shapes do not cover all the part labels of these classes.

Few-shot segmentation on the PartNet dataset k=30 labeled
shapes. Left: 30 fully labeled
shapes are used for training. Right: 30 shapes are used for training, each containing
v = 5 random labeled views. Evaluation is done on the test set of PartNet with the
mean part-iou metric (%). Results are reported by averaging over 5 random runs.

Few-shot segmentation on the RenderPeople dataset. We evaluate the segmentation performance using the part mIOU metric. We experiment with two kinds of input, 1) when both RGB+Geom. (depth and normal maps) are input, and 2) when only RGB is input to the network. We evaluate all methods when k = 5, 10 fully labeled shapes are used for supervision and when k = 5, 10 shapes with 3 2D views are available for supervision. MvDeCor consistently outperform baselines on all settings.