Toronto AI Lab
Toronto AI Lab
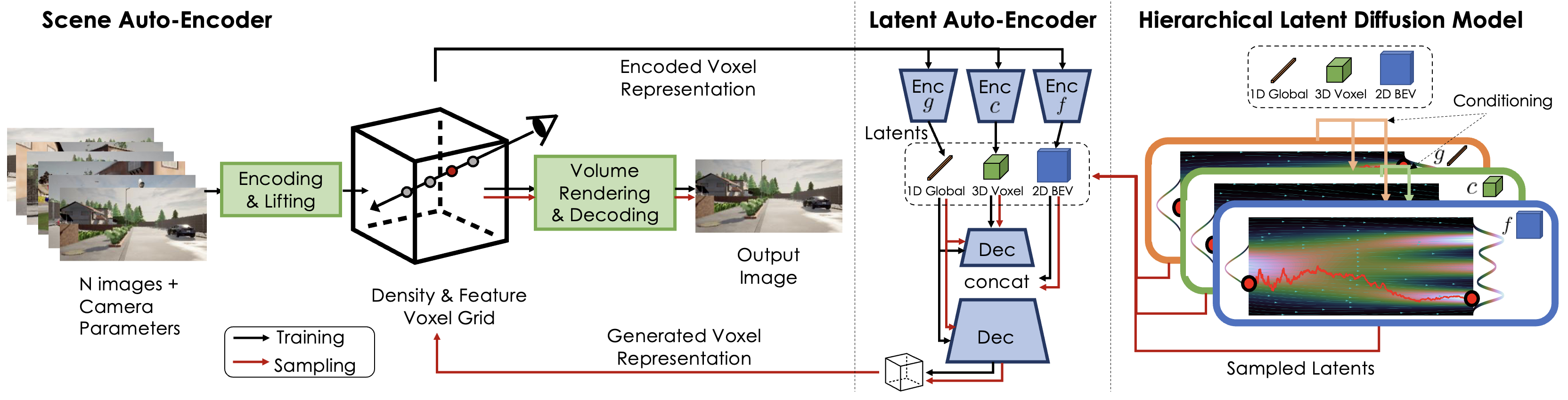
Automatically generating high-quality real world 3D scenes is of enormous interest for applications such as virtual reality and robotics simulation. Towards this goal, we introduce NeuralField-LDM, a generative model capable of synthesizing complex 3D environments. We leverage Latent Diffusion Models that have been successfully utilized for efficient high-quality 2D content creation. We first train a scene auto-encoder to express a set of image and pose pairs as a neural field, represented as density and feature voxel grids that can be projected to produce novel views of the scene. To further compress this representation, we train a latent-autoencoder that maps the voxel grids to a set of latent representations. A hierarchical diffusion model is then fit to the latents to complete the scene generation pipeline. We achieve a substantial improvement over existing state- of-the-art scene generation models. Additionally, we show how NeuralField-LDM can be used for a variety of 3D content creation applications, including conditional scene generation, scene inpainting and scene style manipulation.

NeuralField-LDM:
Scene Generation with Hierarchical Latent Diffusion Models
Seung Wook Kim, Bradley Brown, Kangxue Yin, Karsten Kreis, Katja Schwarz, Daiqing Li, Robin Rombach, Antonio Torralba, Sanja Fidler
We show synthesized samples from AVD (real-world driving) and Carla [1] datasets. For AVD, we first get a coarse voxel representation that has reasonable geometry & texture, and then optimize it further with a post-optimization step described in Section 3.4 of the paper. In particular, we leverage Score Distillation Sampling (SDS) [2] and devise negative guidance for improving the scene quality.
[1] Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. CARLA: An open urban driving simulator. 2017.
[2] Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. ICLR, 2023.
In addition to improving quality, we can also modify scene properties, such as time of day and weather, with the same post-optimization technique. We use an image-finetuned Stable Diffusion [3,4] for SDS and feed random images corresponding to the given style query for the post-optimization step.
[3] Robin Rombach, Andreas Blattmann, Dominik Lorenz, PatrickEsser, and BjörnOmmer. High-resolution image synthesis with latent diffusion models. CVPR, 2022.
[4] https://github.com/justinpinkney/stable-diffusion
Our neural field is based on a voxel-grid representation, which allows easy editing of scenes. Here, we show examples of combining two voxels by directly swapping out the center part of the voxel at the bottom with that of the top one.
When there exists additional information associated with training data, the diffusion models can be trained in a conditional manner. We leverage the Bird's Eye View (BEV) segmentation map in Carla and train the model to generate scenes conditioned on a given BEV map. In BEV maps, each color denotes a different semantic class - dark blue: vehicles, pink: sidewalk, purple: drivable road, green: vegetation, and blue: water.
@inproceedings{kim2023nfldm,
title={NeuralField-LDM: Scene Generation with Hierarchical Latent Diffusion Models},
author={Kim, Seung Wook and Brown, Bradley and Yin, Kangxue and Kreis, Karsten and
Schwarz, Katja and Li, Daiqing and Rombach, Robin and Torralba, Antonio and Fidler, Sanja},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition ({CVPR})},
year={2023}
}
For business inquiries, please visit our website and submit the form: NVIDIA Research Licensing