Generative models for 2D images has recently seen tremendous progress in quality, resolution and speed as a result of the efficiency of 2D convolutional architectures. However it is difficult to extend this progress into the 3D domain since most current 3D representations rely on custom network components. This paper addresses a central question: Is it possible to directly leverage 2D image generative models to generate 3D shapes instead? To answer this, we propose XDGAN, an effective and fast method for applying 2D image GAN architectures to the generation of 3D object geometry combined with additional surface attributes, like color textures and normals. Specifically, we propose a novel method to convert 3D shapes into compact 1-channel geometry images and leverage StyleGAN3 and image-to-image translation networks to generate 3D objects in 2D space. The generated geometry images are quick to convert to 3D meshes, enabling real-time 3D object synthesis, visualization and interactive editing. Moreover, the use of standard 2D architectures can help bring more 2D advances into the 3D realm. We show both quantitatively and qualitatively that our method is highly effective at various tasks such as 3D shape generation, single view reconstruction and shape manipulation, while being significantly faster and more flexible compared to recent 3D generative models.
Perhaps one of the greatest challenges to the development of generative models for 3D content is converging on the right representation. Direct extension of 2D pixel grids to 3D voxel grids suffers from high memory demands of 3D convolutions, limiting resolution. Point cloud samples of surface geometry, while popular for generative tasks, are limited in their ability to model sharp features or high-resolution textures. Recently implicit 3D representations, such as NeRF and DeepSDF, as well as hybrids, have shown great promise for generative tasks. However, these approaches typically are too slow for interactive applications and their output does not interface with existing 3D tools, which typically use triangular meshs, calling for costly or lossy conversion of models before use. In this work, we show that it is possible to directly leverage a 2D GAN architecture designed for images to generate high-quality 3D shapes. The key to our approach is parameterization of 3D shapes as 2D planar geometry images, which we use as the training dataset for an image-based generator. Our method uses 2D generative architectures to produce fixed-topology textured meshes with a single forward pass, and is thus immediately practical.
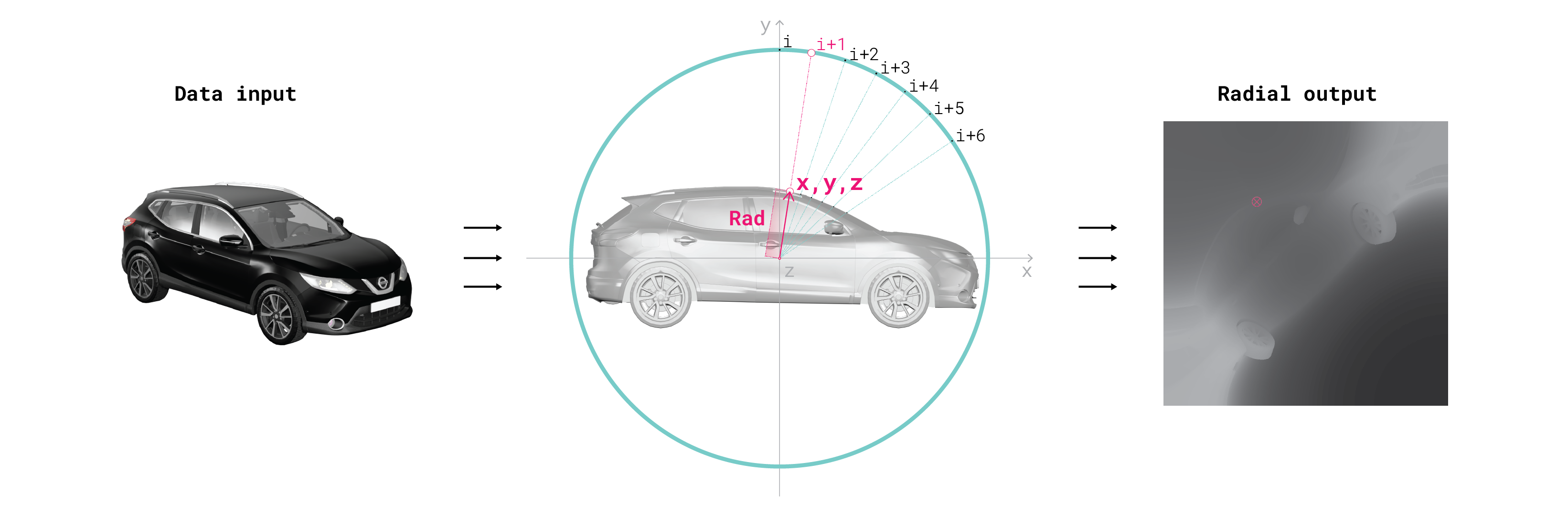
Generation of Rad geometry images from 3D meshes using sphereical projection.
Geometry images are a representation that captures 3D surface as a 2D array of \((x, y, z)\) values via an implicit surface parameterization, which is a bi-directional mapping from an object's surface to a 2D plane. Such parameterizations are often used in computer graphics to map 2D textures and other attributes onto a 3D surface mesh. Once the parameterization is determined, the plane is sampled to create a 3-channel \(n \times n\) image where each pixel represents an \((x, y, z)\) vertex location of a new geometry image mesh, which is independent from the original object's mesh topology or representation. The order and connectivity of each vertex within this geometry image mesh is encoded by its pixel index, where faces connect neighboring pixel-vertices using a regular structure.
Because projection from the sphere onto a 3D surface has only one degree of freedom (distance along the normal direction of the sphere, see Figure above), we represent the 3D location of a surface point as a single value measuring the distance (which we call “Rad") from the origin along the projection ray, effectively reducing the degrees of freedom of the representation from 3 channels per pixel to only 1. To compute the original \((x, y, z)\) coordinates of all the vertices, one only needs to multiply the Rad image by the image representing the normals of the projection sphere, fixed for the whole dataset. In addition to positions, we produce aligned images of normals and color textures.
Geometry images can contain additional channels encoding surface properties like color texture, normals, object segmentation and similar. Because the same surface parameterization is used when sampling these additional properties, all channels of the geometry image are aligned, with each pixel representing location and other properties of the same 3D vertex. In this work, we generate normals and texture geometry images and propose applying 2D convolutional generators to these aligned X-channel images.
Overview of XDGAN training.
Once our training dataset is converted to Rad geometry images, we train standard 2D GAN architectures to produce "realistic" Rad images. The only modification required is to adapt them to high-precision geometry images instead of the traditional 8-bit RGB images. Specifically, we experiment using StyleGAN3 for geometry generation, but nothing suggests that our approach will not generalize to other GAN architectures. We found training over single-channel Rad images to differ little in its stability from standard image-based GAN training.
Overview of XDGAN inference.
During the inference phase, we first generate a Rad geometry image using the StyleGAN3 network. The Rad geometry image is them fed into the image-to-image models which generate the normals and textures. The Rad geometry image is then converted into a mesh using the pixel index as a definition of the vertices connectivity. The normal and texture maps are then applied to the surface to produce a fully texture mesh.A major advantage of our 3D generative model is that it is based on standard GAN architectures, which allows us to directly apply various techniques developed for image-based GANs. To demonstrate this, we integrate the existing technique of InterFaceGAN [Shen et al.(2020b] in order to find editing directions within our trained latent space. To this end, we first project our training shapes into the latent space \(W\) to create a set of of projected latent vectors \(w\) with lables (e.g. sports-car, SUV, etc.). We then train one linear SVMs for each label using these labeled examples, and use the unit normal vector to the separation hyperplane of the SVM as an editing direction in latent space. The target attribute of a real or generated 3D shape can then be enhanced or negated by simply steering its latent vector \(w\) along this editing direction.
The latent space of XDGAN allows meaningful latent space exploration such as semantic editing.
For feedback and questions please
reach out to Hassan Abu Alhaija.
If you find this work useful for your research, please consider citing it as:
@inproceedings{Alhaija2022xdgan,
title={XDGAN: Multi-Modal 3D Shape Generation in 2D Space},
author={Alhaija, Hassan Abu and Dirik, Alara and Kn{\"o}rig, Andr{\'e} and Fidler, Sanja and Shugrina, Maria},
booktitle={British Machine Vision Conference (BMVC 2022)},
year={2022}
}
