|
Annotating images with pixel-wise labels is a time-consuming and costly process. Recently, DatasetGAN showcased a promising
alternative - to synthesize a large labeled dataset via a generative adversarial network (GAN) by exploiting a small set of manually labeled,
GAN-generated images. Here, we scale DatasetGAN to ImageNet scale of class diversity. We take image samples from the class-conditional generative model BigGAN trained on ImageNet,
and manually annotate 5 images per class, for all 1k classes. By training an effective feature segmentation architecture on top of BigGAN,
we turn BigGAN into a labeled dataset generator. We further show that VQGAN can similarly serve as a dataset generator, leveraging the already annotated data.
We create a new ImageNet benchmark by labeling an additional set of 8k real images and evaluate segmentation performance in a variety of settings.
Through an extensive ablation study we show big gains in leveraging a large generated dataset to train different supervised and self-supervised backbone models on pixel-wise tasks.
Furthermore, we demonstrate that using our synthesized datasets for pre-training leads to improvements over standard ImageNet pre-training on several downstream datasets,
such as PASCAL-VOC, MS-COCO, Cityscapes and chest X-ray, as well as tasks (detection, segmentation). Our benchmark will be made public and maintain a leaderboard for
this challenging task.
|
News
- [June 2022] Our code and dataset are released! Github
- [March 2022] Our benchmark and dataset will be released soon!
- [Fed 2022] Paper accepted to CVPR 2022!
- [December 2021] Project page is up!
Methods
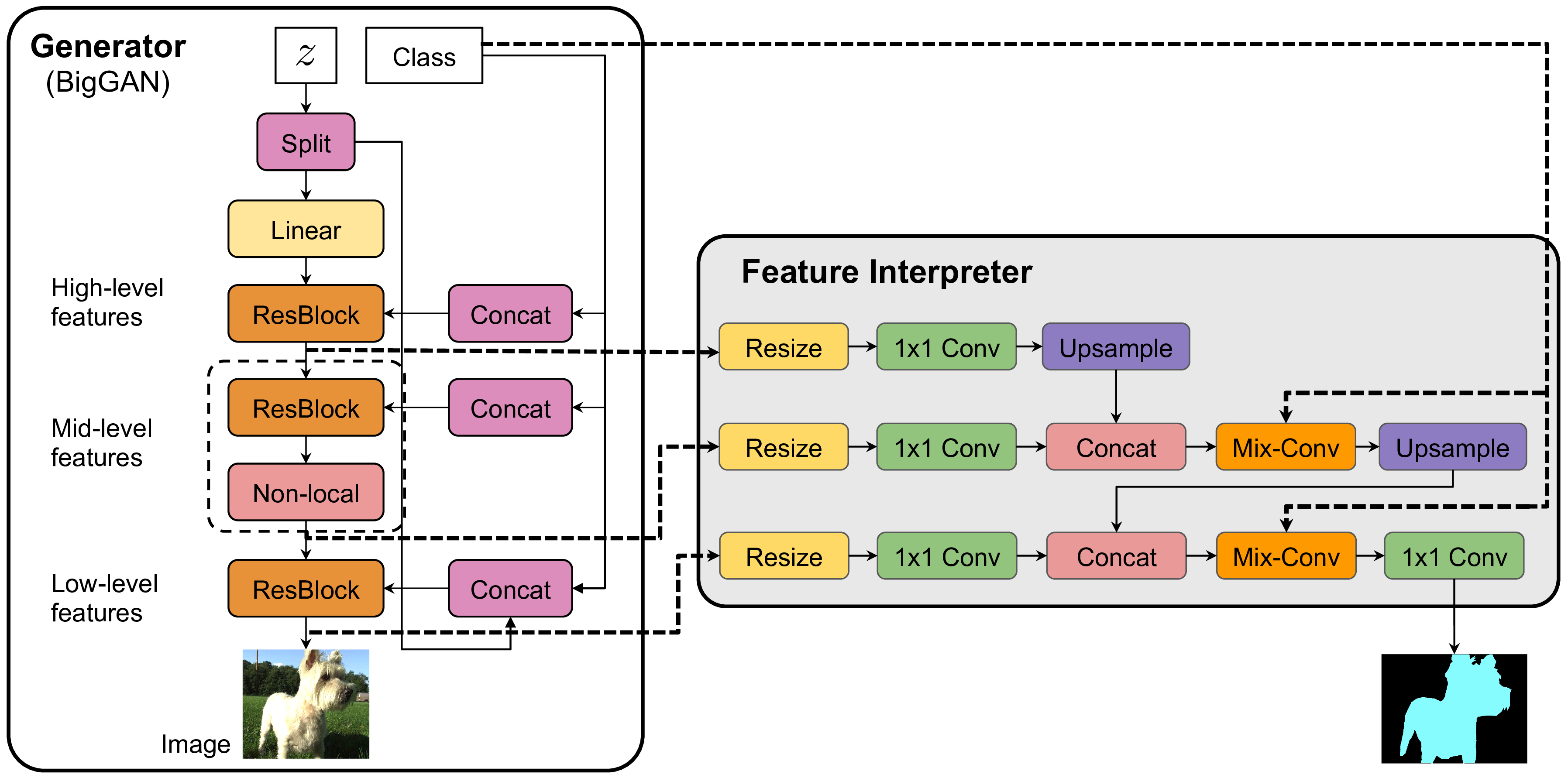
|
|
Architecture of BigDatasetGAN based on BigGAN. We augment BigGAN with a segmentation branch using BigGAN's features.
We exploit the rich semantic features of generative models in order to synthesize paired data, segmentation masks and images, turning generative models into dataset generators.
|
Dataset Analysis
|
We provide analyses of our synthesized datasets compared to the real annotated ImageNet samples.
We compare image and label quality in terms of distribution metrics using the real annotated dataset as reference. We also compare
various label statistics and perform shape analysis on labeled polygons in terms of shape complexity and diversity.
|

|
|
Dataset analysis. We report image & mask statistics across our datasets. We compute image and
label quality using FID and KID and use Real-annotated dataset as reference. IN: instance count per image, MI: ratio of mask area over
image area, BI: ratio of tight bounding box of the mask over image area, MB: ratio of mask area over area of its tight bounding box, PL:
polygon length (polygon normalized to width and height of 1), SC: shape complexity measured by the number of points in a simplified
polygon, SD: shape diversity measured by mean pair-wise Chamfer distance per class and averaged across classes.
|

|
|
Examples from our datasets: Real-annotated (real ImageNet subset labeled manually), Synthetic-annotated
(BigGAN’s samples labeled manually), and synthetic BigGAN-sim, VQGAN-sim datasets. Notice the high quality of synthetic sampled labeled examples.
|

|
|
Mean shapes from our BigGAN-sim dataset. For our 100k BigGAN-sim dataset, each class has around 100 samples. We crop
the mask from the segmentation label and run k-means with 5 clusters to extract the major modes of the selected ImageNet class shapes.
|
Imagenet Segmentation Benchmark
|
We introduce a benchmark with a suite of segmentation challenges using our Synthetic-annotated dataset (5k) as training set
and evaluate on our Real-annotated held-out dataset (8k). Specifically, we evaluate performance for (1)
two individual classes (dog and bird), (2) foreground/background (FG/BG) segmentation evaluated across all 1k classes,
and (3) multi-class semantic segmentation for various subsets of classes.
|
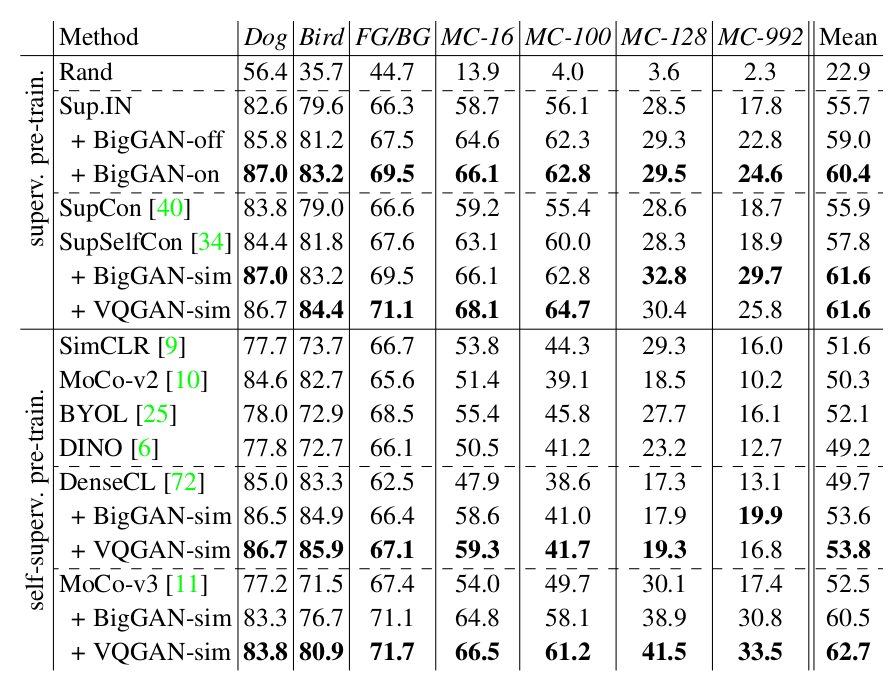
|
|
ImageNet pixel-wise benchmark. Numbers are mIoU.
We compare various methods on several tasks, with supervised and self-supervised pre-training. We use Resnet-50 for all methods. We ablate the use of
synthetic datasets for three methods. FG/BG evaluates binary segmentation across all classes; MC-N columns evaluate multi-class segmentation performance in setups with N classes.
Adding synthetic datasets improves performance by a large margin BigGAN-off and BigGAN-on compare offline & online sampling strategy.
|
Imagenet Segmentation Visualization

|
|
Qualitative results on MC-128. We visualize predictions (second column) of DeepLab trained on our BigGAN-sim dataset, compared to
ground-truth annotations (third column). The final row shows typical failure cases, which include multiple parts, thin structures or complicated scenes.
|
Imagenet Segmentation vs Classification Analysis

|
|
Top-5 analysis of ImageNet benchmark. Text below images indicates: Class name, FG/BG segmentation measured in mIoU, classification
accuracy of a Resnet-50 pre-trained on ImageNet. Top Row: We visualize Top-5 best predictions of DeepLabv3 trained on BigGAN-sim dataset for the
FG/BG task, compared to ground-truth annotations (third column). Bottom Row: We visualize Top-5 worst predictions. Typical failure cases include small
objects or thin structures. Interestingly, classes the are hard to segment, such as baskeball and bow, are not necessarily hard to classify.
|
Imagenet Segmentation Ablation Study
|
|
|
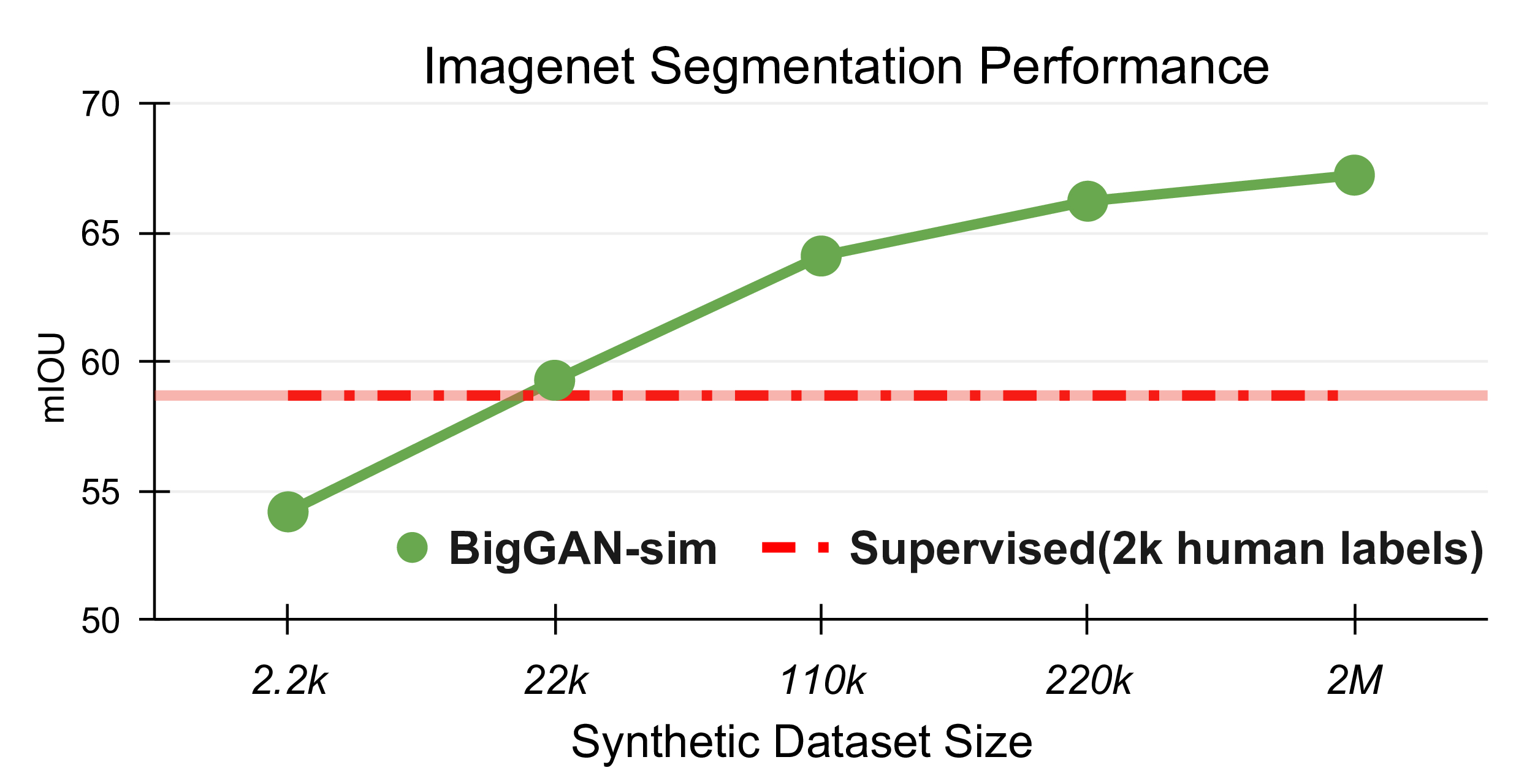
Ablating synthetic dataset size. We fix the model to the Resnet50 backbone and compare the performance when we increase the
synthetic dataset size. The model trained using a 22k synthetic dataset outperforms the same model trained with 2k human-annotated dataset. Another
7 points is gained when further increasing the synthetic data size from 22k to 220k. Here, 2M is the total number of samples synthesized through our
online sampling strategy.
|
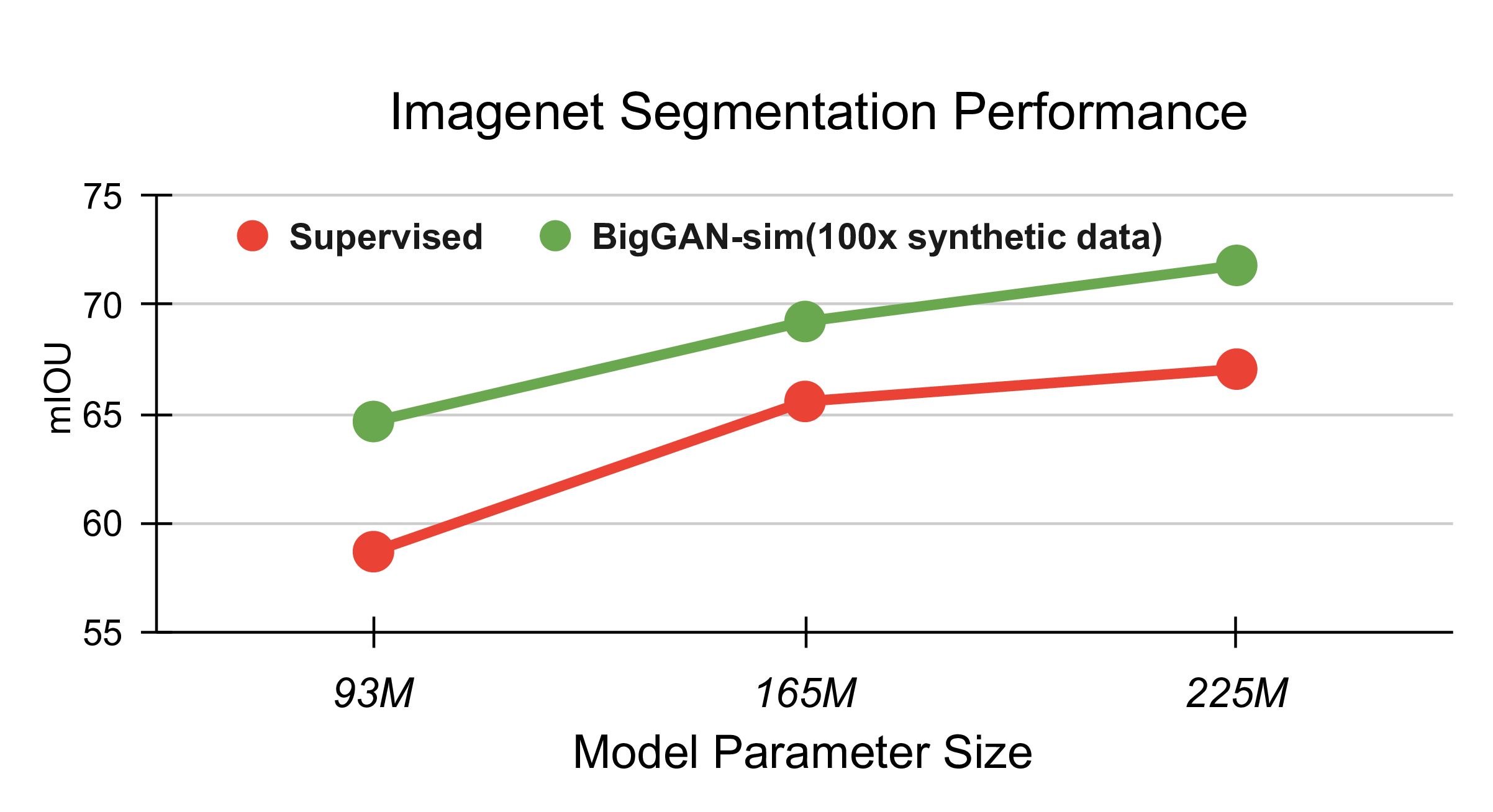
Ablating backbone size. We scale up the backbone from Resnet50 to Resnet101
and Resnet152. We supervise with 2k human-annotated labels (red), and with our BigGAN-sim
dataset (green), which is 100x larger. BigGAN-sim dataset supervision leads to consistent improvements, especially for larger models.
|
Downstream Tasks Performance
|
We propose a simple architecture design to jointly train model backbones with contrastive learning and supervision from our synthetic datasets as pretraining step.
Here we show transfer learning experiments results for dense prediction tasks on MS-COCO, PASCAL-VOC, Cityscapes, as well as chest X-ray segmentation in the medical domain.
|

|
|
MS-COCO object detection & instance segmentation. Using our synthetic data during pre-training improves object detection
performance by 0.4 AP bb , and instance segmentation by 0.3 AP mk in 1x training schedule. When training longer in the 2x schedule,
our synthetic data consistently helps improving the task performance by 0.3 AP bb and 0.2 AP mk.
|
|
|
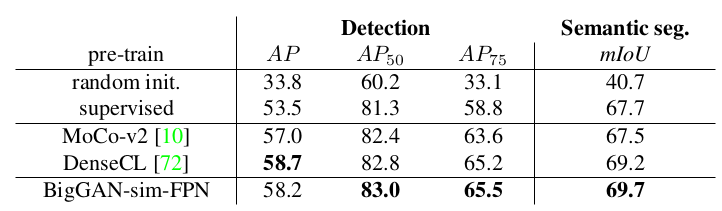
PASCAL VOC detection & semantic segmentation. For detection, we train on the trainval'07+12
set and evaluate on test07. For semantic segmentation, we train on train aug2012 and evaluate on val2012. Results
are average over 5 individual trials.
|
|

|
|
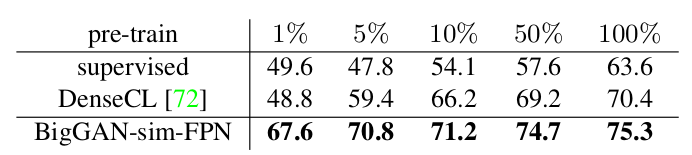
Semi-supervised chest X-ray segmentation with a frozen backbone. Performance numbers are mIoU. When using
our synthetic dataset, we match the performance of the supervised and self-supervised pre-trained networks with only 1% and 5% of
labels, respectively. We achieve a big gain using 100% of the data. Numbers are averaged over 3 independent trials.
|
Cityscapes instance and semantic segmentation. training with our BigGAN-sim dataset improves AP mk by 0.3 points in the instance segmentation task over
the baseline model. However, we do not see a significant performance boost for the semantic segmentation task.
|
Paper
 |
BigDatasetGAN:
Synthesizing ImageNet with Pixel-wise Annotations
Daiqing Li, Huan Ling, Seung Wook Kim,
Karsten Kreis, Adela Barriuso, Sanja Fidler, Antonio Torralba
[Paper] [Benchmark and dataset] (coming soon)
For feedback and questions please reach out to Daiqing Li and Huan Ling.
|
|
|
Citation
If you find this work useful for your research, please consider citing it as:
@inproceedings{bigDatasetGAN,
title = {BigDatasetGAN: Synthesizing ImageNet with Pixel-wise Annotations},
author = {Daiqing Li and Huan Ling and Seung Wook Kim and Karsten Kreis and
Adela Barriuso and Sanja Fidler and Antonio Torralba},
eprint={2201.04684},
archivePrefix={arXiv},
year = {2022}
}
See prior work on using GANs for downstream tasks, which BigDatasetGAN builds on:
DatasetGAN
@inproceedings{zhang21,
title={DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort},
author={Zhang, Yuxuan and Ling, Huan and Gao, Jun and Yin, Kangxue and Lafleche,
Jean-Francois and Barriuso, Adela and Torralba, Antonio and Fidler, Sanja},
booktitle={CVPR},
year={2021}
}
SemanticGAN
@inproceedings{semanticGAN,
title={Semantic Segmentation with Generative Models: Semi-Supervised Learning and Strong Out-of-Domain Generalization},
booktitle={Conference on Computer Vision and Pattern Recognition (CVPR)},
author={Li, Daiqing and Yang, Junlin and Kreis, Karsten and Torralba, Antonio and Fidler, Sanja},
year={2021},
}
Dataset Visualization
|
Here we show random samples from the human-annotated dataset Real-annotated (real ImageNet subset labeled manually),
Synthetic-annotated (BigGAN’s samples labeled manually) as well as synthetic datasets BigGAN-sim, VQGAN-sim generated by BigGAN and VQGAN.
We also show side-by-side comparison between BigGAN-sim and VQGAN-sim datasets.
|
|
Examples from the Real-annotated dataset. We visualize both the segmentation masks as well as the boundary polygons.
|

|
|
Examples from the Synthetic-annotated dataset. We visualize both the segmentation masks as well as the boundary polygons.
|

|
|
Examples from the BigGAN-sim random samples. We visualize both the segmentation masks as well as the boundary polygons.
|

|
|
Examples from the VQGAN-sim random samples. We visualize both the segmentation masks as well as the boundary polygons.
|

|
|
BigGAN-sim vs VQGAN-sim. We select the same classes at each row for both BigGAN-sim and VQGAN-sim for easy
comparison. Comparing to BigGAN-sim, the VQGAN-sim dataset samples are more diverse in terms of object scale,
pose as well as background. However, we see BigGAN-sim has better label quality than VQGAN-sim where in some
cases the labels have holes and are noisy.
|
|

|
|
BigGAN-sim per-class samples
|
VQGAN-sim per-class samples
|


