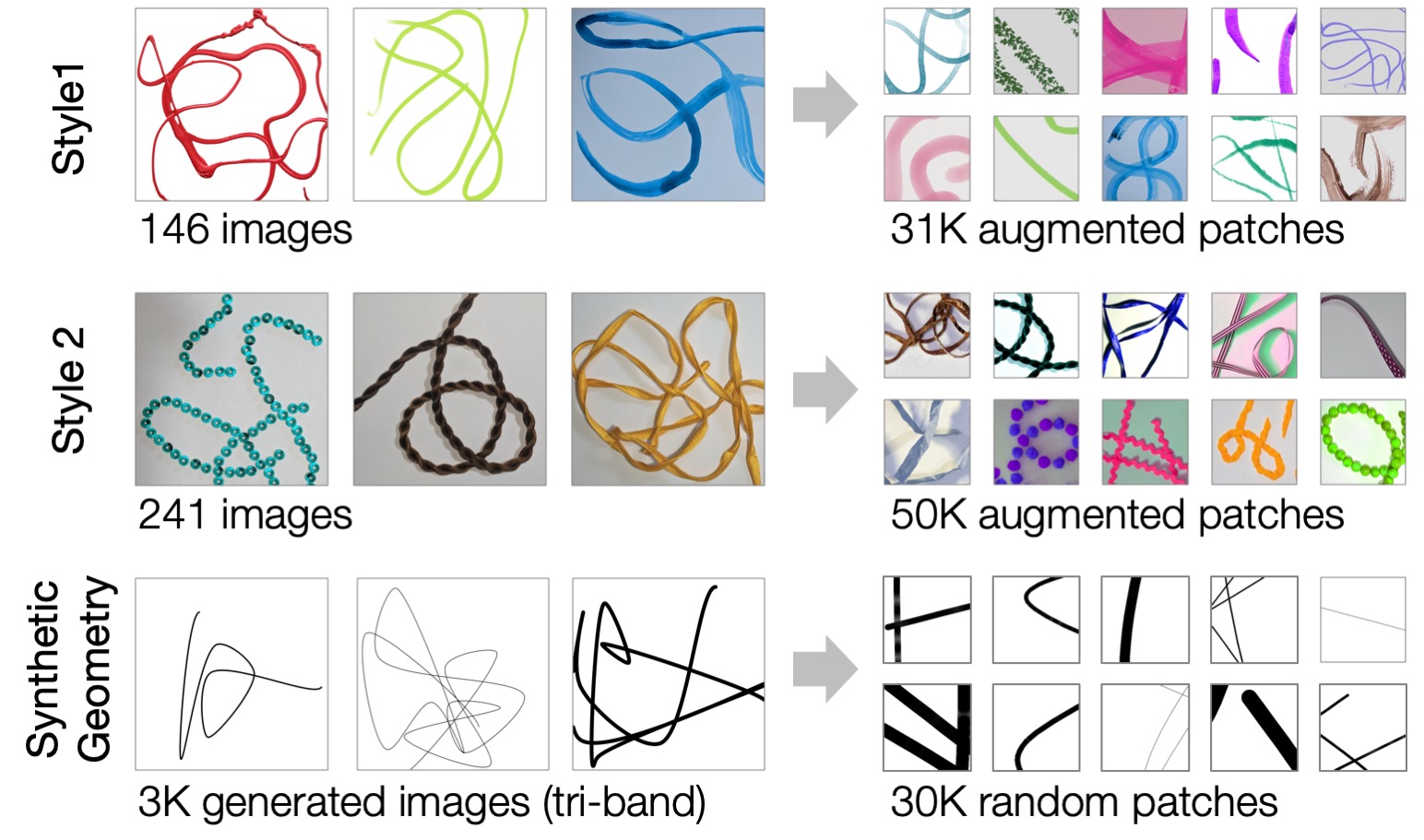
AStro dataset was collected to support Deep Learning techniques for interactive drawing media by learning from unlabeled media samples. We informally captured two style datasets using a hand-held mobile phone. Style 1 contains 146 scribbles of common physical and digital tools like paints and crayons. Style 2 contains 241 photos of eclectic materials, like ribbons and beads. To obtain patch datasets X1 and X2, we draw random patches and augment them with standard image processing, expanding the training set diversity. As a proxy for user control, we also generate a synthetic geometry dataset of random splines, cut into a patch dataset G.
Coming soon.
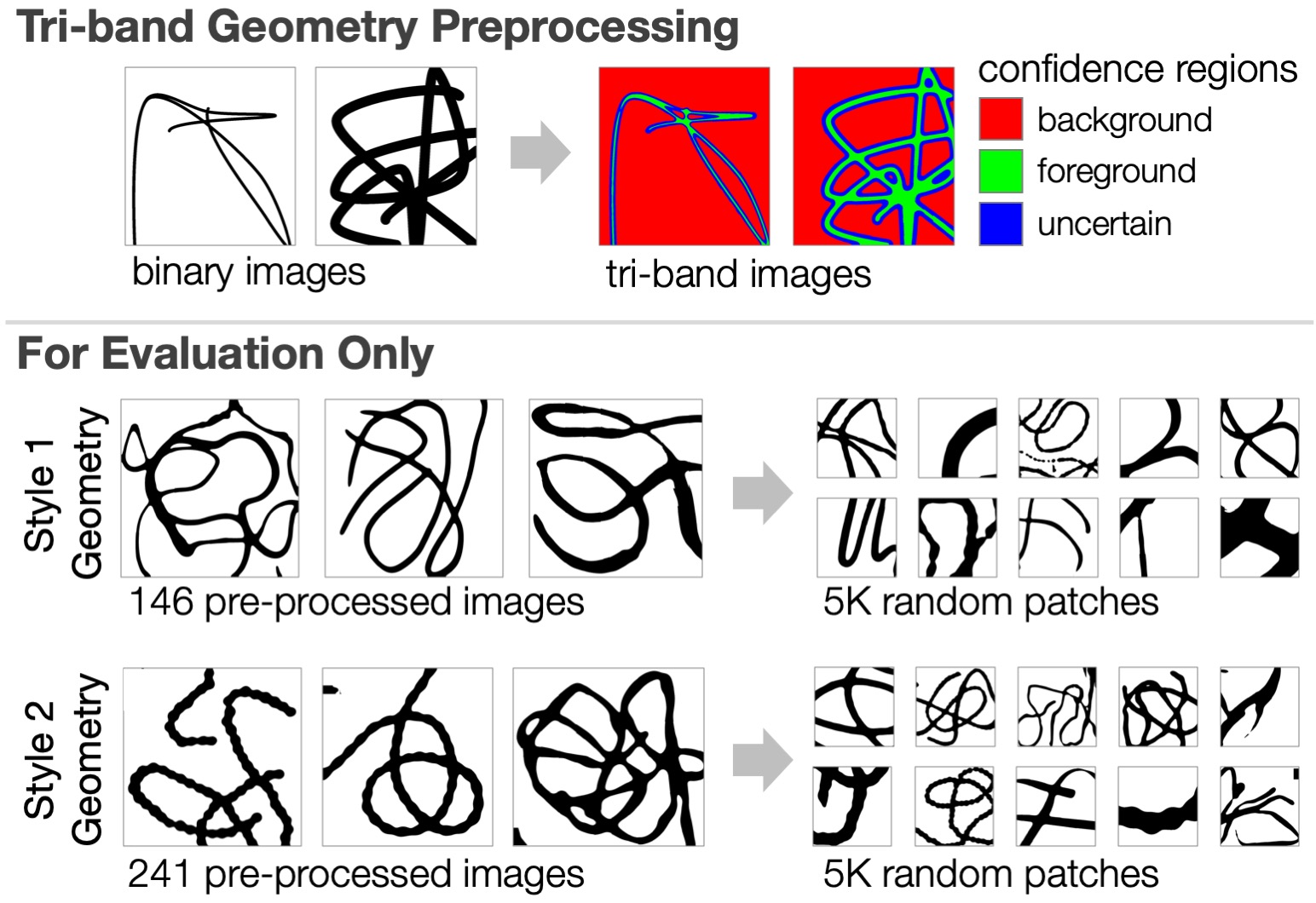
To support softer edge losses, we automatically preprocess G into a tri-band dataset, where curve boundaries are marked "uncertain". In addition, style datasets are passed through image-processing heuristics to generate corresponding black-on-white strokes. In the past these geometry datasets were only used for evaluation of methods, but they could be also useful for training.
If building on this data, please cite:
@article{shugrina2022neube,
title={Neural Brushstroke Engine: Learning a Latent Style Space of Interactive Drawing Tools},
author={Shugrina, Maria and Li, Chin-Ying and Fidler, Sanja},
journal={ACM Transactions on Graphics (TOG)},
volume={41},
number={6},
year={2022},
publisher={ACM New York, NY, USA}
}