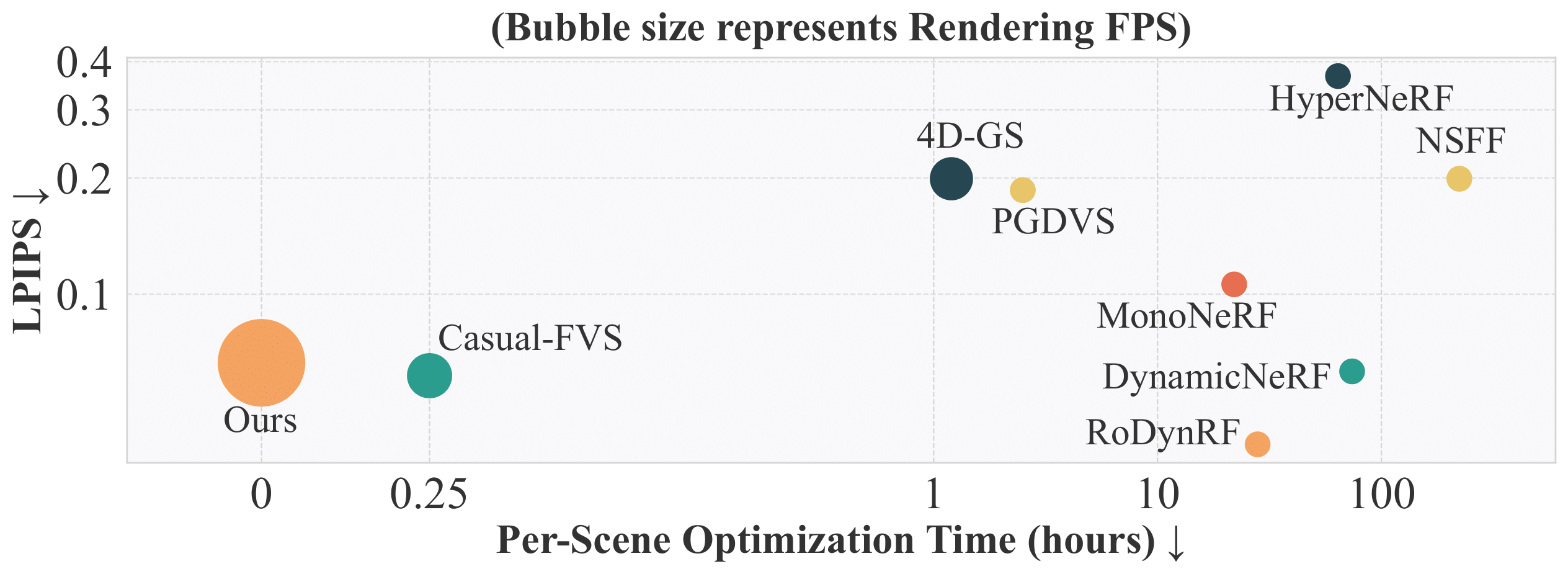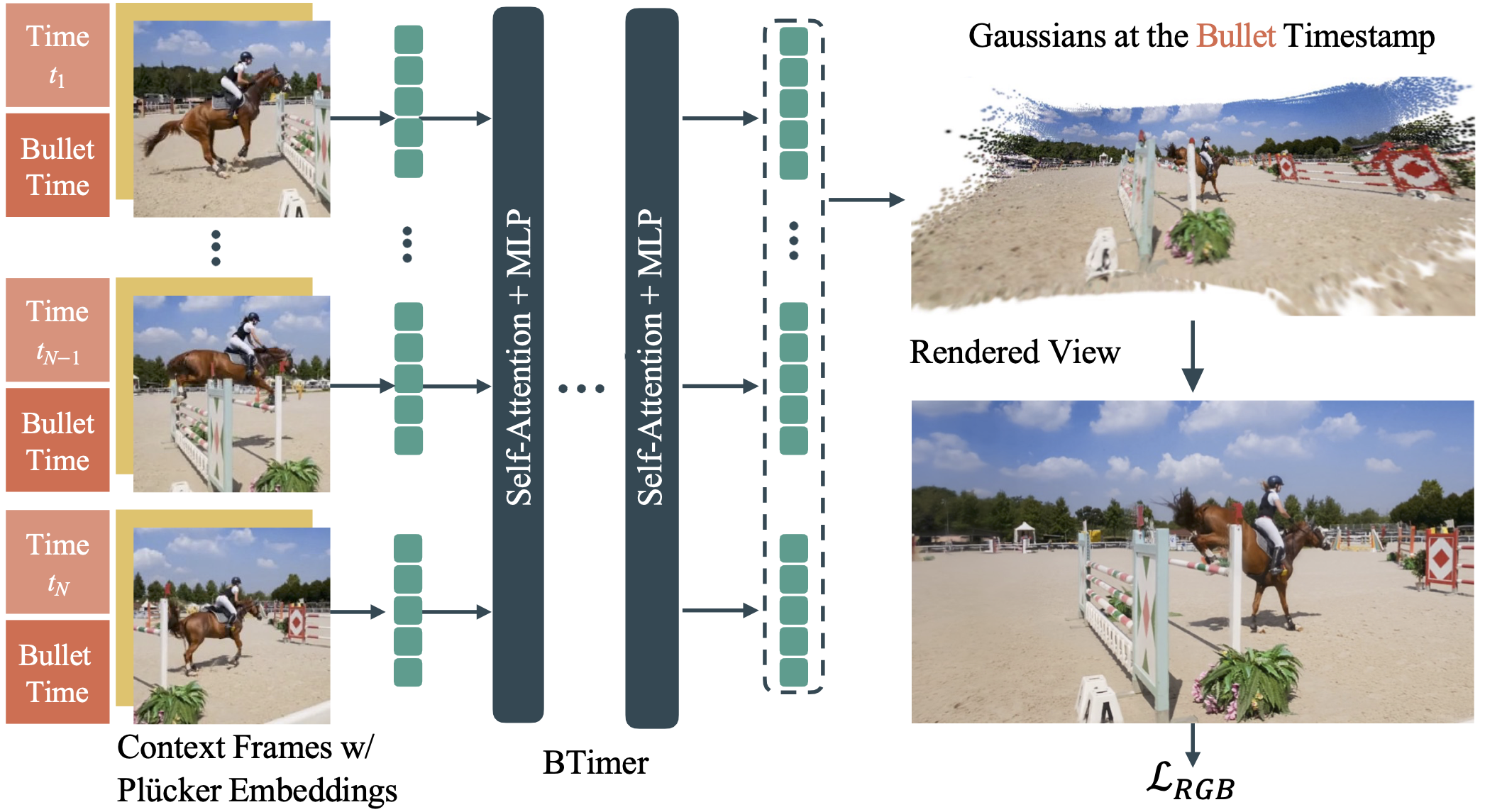
Results
Qualitative Results






















Qualitative Results on DyCheck iPhone dataset. Left is the input video, right two are the videos rendered from novel camera trajectories.
Dynamic Novel View Synthesis Benchmark Results