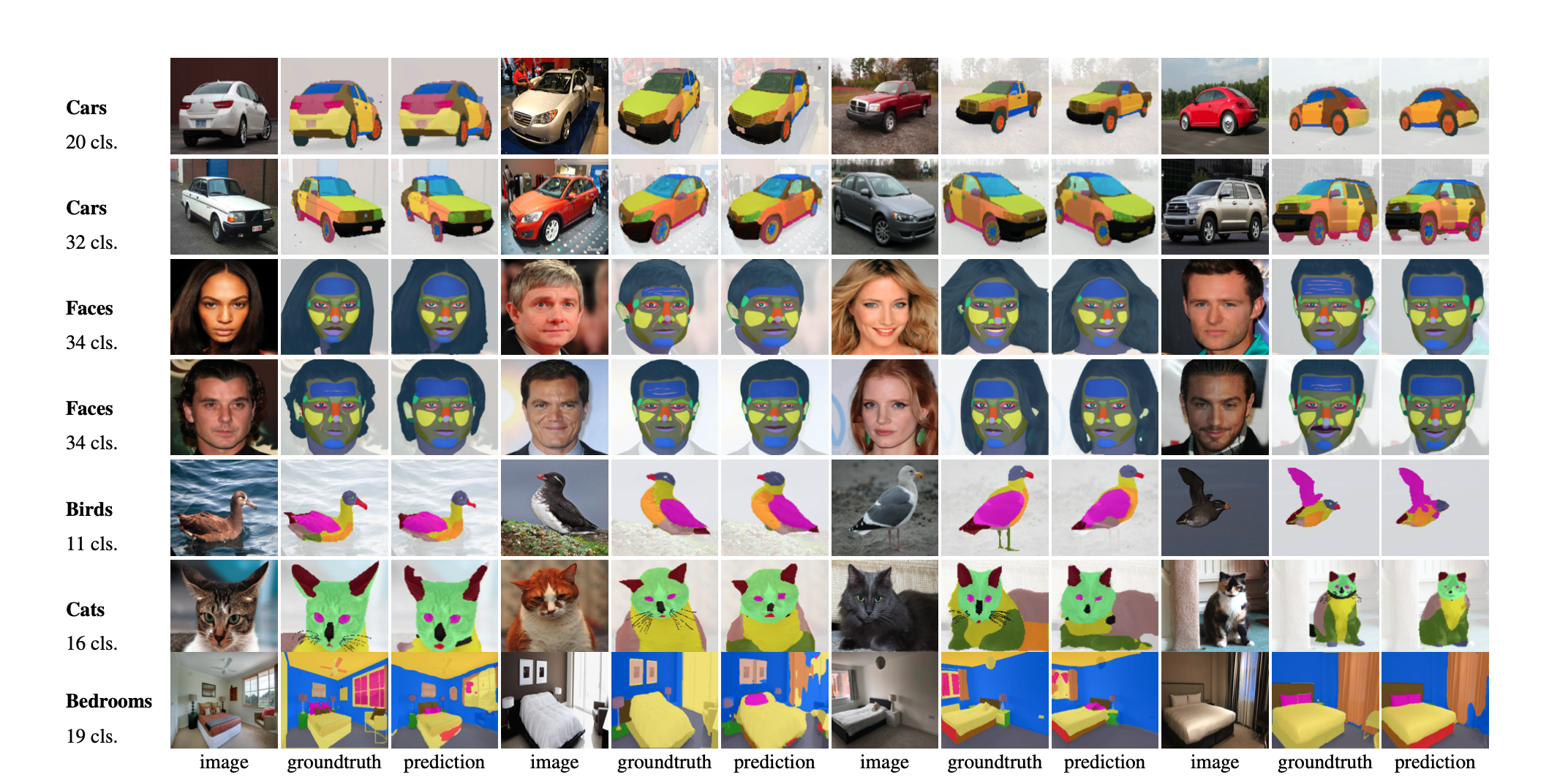
We introduce DatasetGAN: an automatic procedure to generate massive datasets of high-quality semantically segmented images requiring minimal human effort. Current deep networks are extremely data-hungry, benefiting from training on large-scale datasets, which are time consuming to annotate. Our method relies on the power of recent GANs to generate realistic images. We show how the GAN latent code can be decoded to produce a semantic segmentation of the image. Training the decoder only needs a few labeled examples to generalize to the rest of the latent space, resulting in an infinite annotated dataset generator! These generated datasets can then be used for training any computer vision architecture just as real datasets are. As only a few images need to be manually segmented, it becomes possible to annotate images in extreme detail and generate datasets with rich object and part segmentations. To showcase the power of our approach, we generated datasets for 7 image segmentation tasks which include pixel-level labels for 34 human face parts, and 32 car parts. Our approach outperforms all semi-supervised baselines significantly and is on par with fully supervised methods using labor intensive annotations.
|

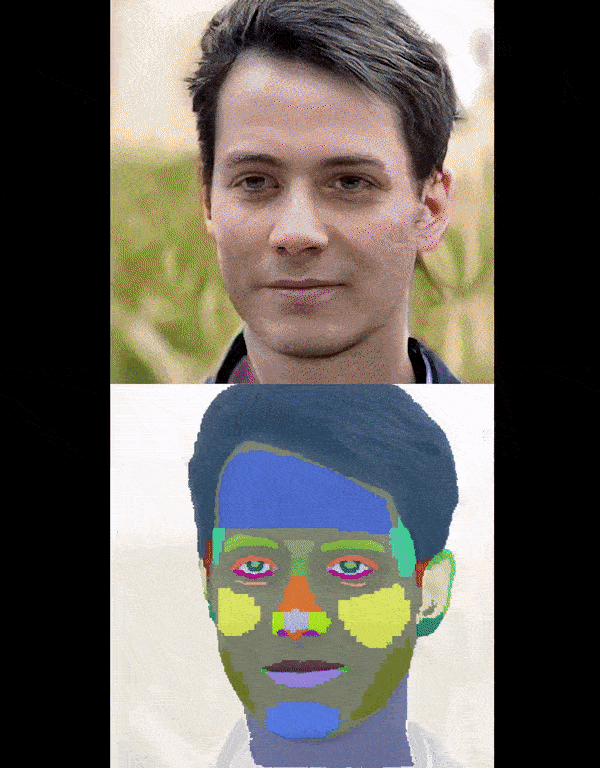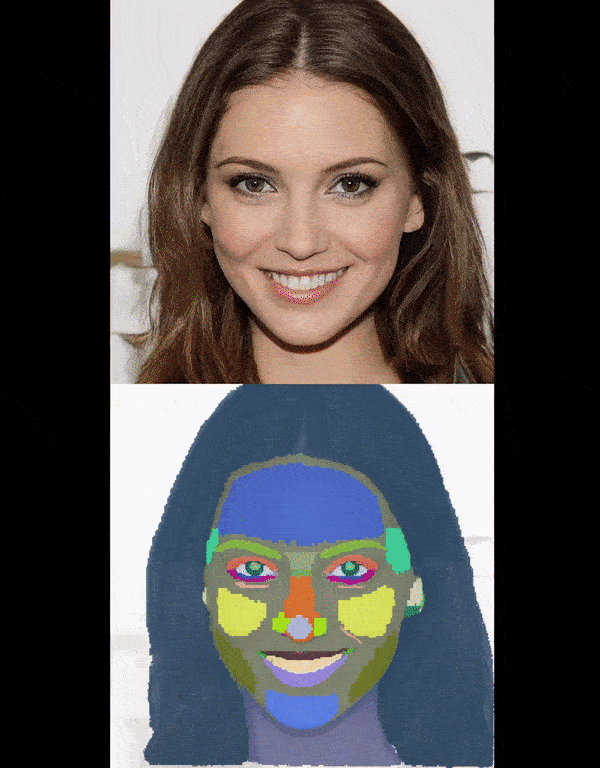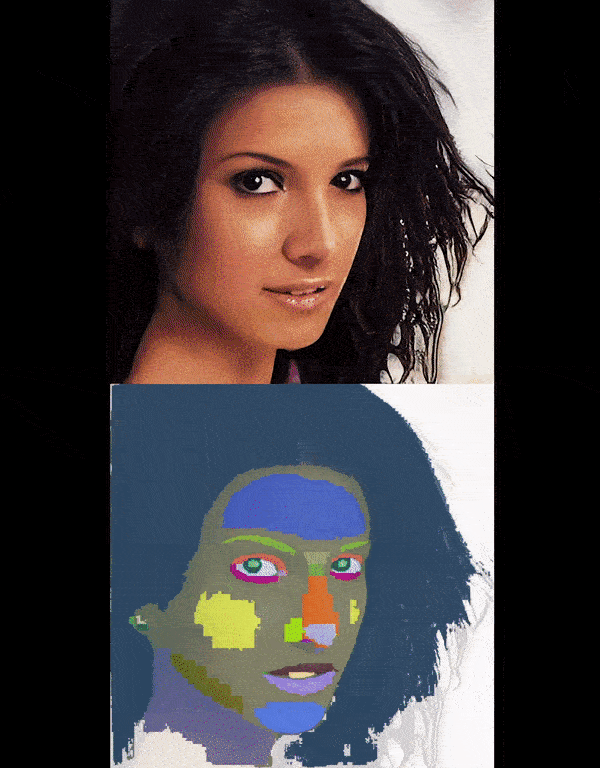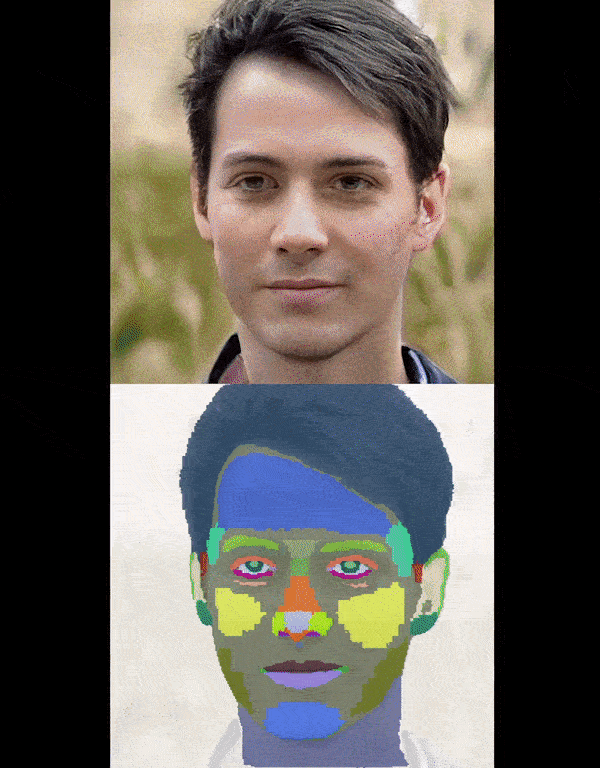
Left: The video showcases our detailed part segmentation in reconstructing animatable 3D objects from monocular
images. Right: The video shows the result of running interpolation over latent space.
|
 DATASETGAN synthesizes image-annotation pairs, and can produce large high-quality datasets with detailed pixel-wise labels. Figure illus- trates the 4 steps. (1 & 2). Leverage StyleGAN and annotate only a handful of synthesized images. Train a highly effective branch to generate labels. (3). Generate a huge synthetic dataset of annotated images authomatically. (4). Train your favorite approach with the synthetic dataset and test on real images.
DATASETGAN synthesizes image-annotation pairs, and can produce large high-quality datasets with detailed pixel-wise labels. Figure illus- trates the 4 steps. (1 & 2). Leverage StyleGAN and annotate only a handful of synthesized images. Train a highly effective branch to generate labels. (3). Generate a huge synthetic dataset of annotated images authomatically. (4). Train your favorite approach with the synthetic dataset and test on real images.