Jonah Philion, Amlan Kar, Sanja Fidler
NVIDIA, Vector Institute, University of Toronto
CVPR 2020
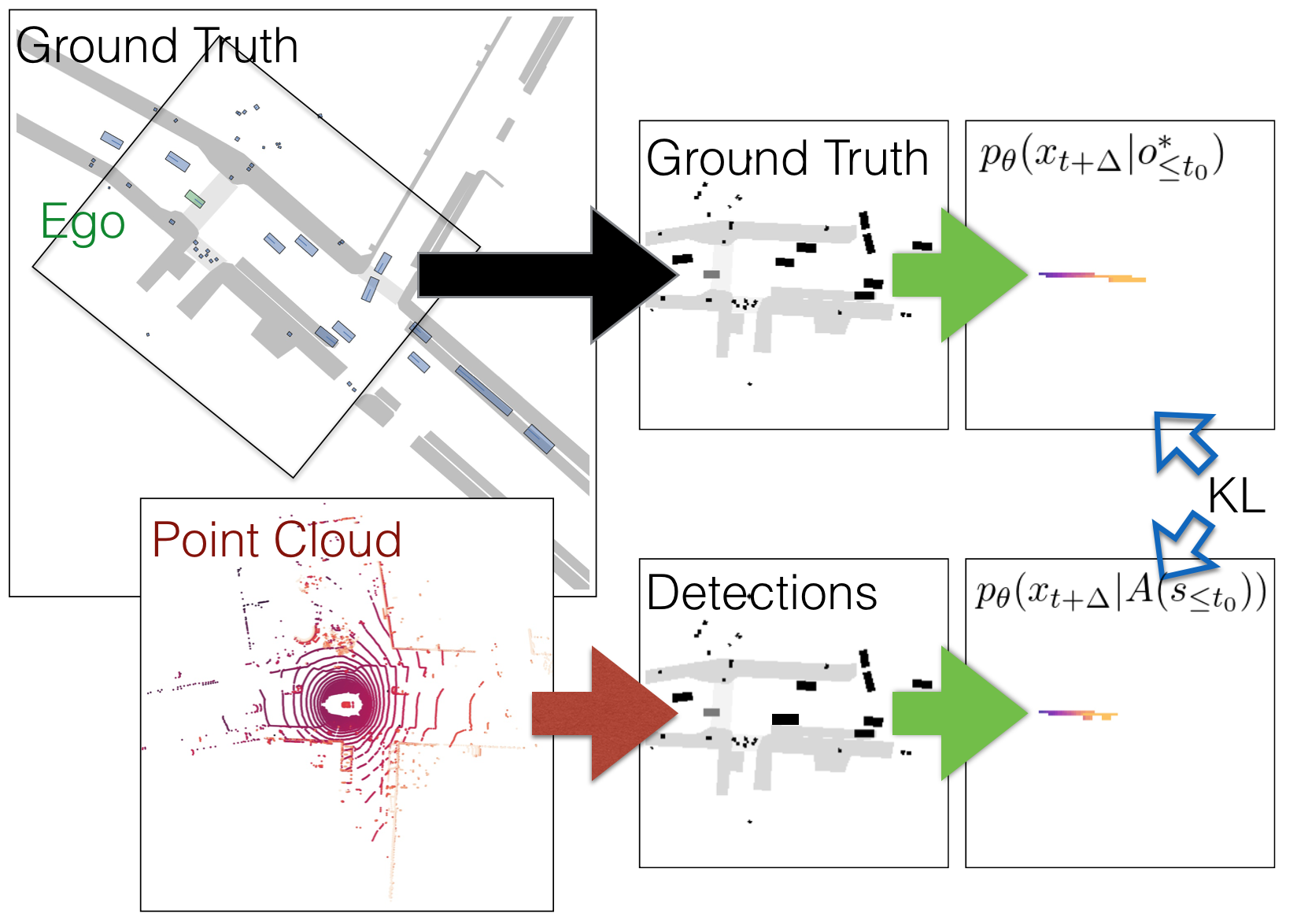
Variants of accuracy and precision are the gold-standard by which the computer vision community measures progress of perception algorithms. One reason for the ubiquity of these metrics is that they are largely task-agnostic; we in general seek to detect zero false negatives or positives. The downside of these metrics is that, at worst, they penalize all incorrect detections equally without conditioning on the task or scene, and at best, heuristics need to be chosen to ensure that different mistakes count differently. In this paper, we propose a principled metric for 3D object detection specifically for the task of self-driving. The core idea behind our metric is to isolate the task of object detection and measure the impact the produced detections would induce on the downstream task of driving. Without hand-designing it to, we find that our metric penalizes many of the mistakes that other metrics penalize by design. In addition, our metric downweighs detections based on additional factors such as distance from a detection to the ego car and the speed of the detection in intuitive ways that other detection metrics do not. For human evaluation, we generate scenes in which standard metrics and our metric disagree and find that humans side with our metric 79% of the time.
| NDS | PKL | Scenes | Responses |
| 21% | 79% | 75 | 730 |
|---|
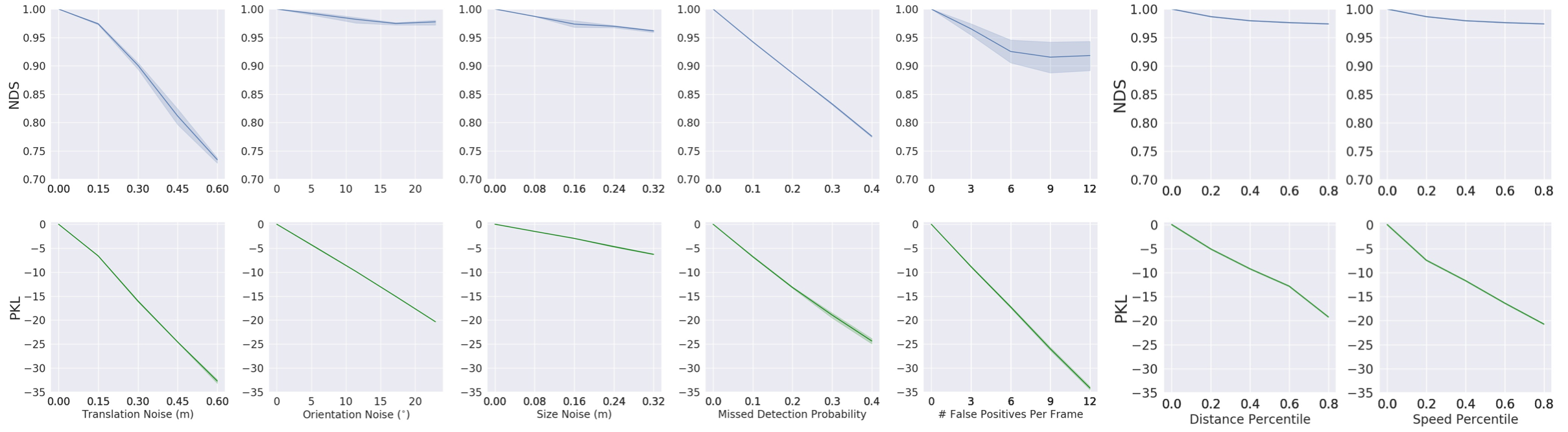
Comparison to hand-designed metrics On the left, we show that PKL largely agrees with NDS under canonical noise models such as translation error. On the right, we show that while NDS penalizes false negatives equally independent of context, PKL penalizes false negatives more strongly if the missed detection is close to the ego vehicle or moving at high speeds.
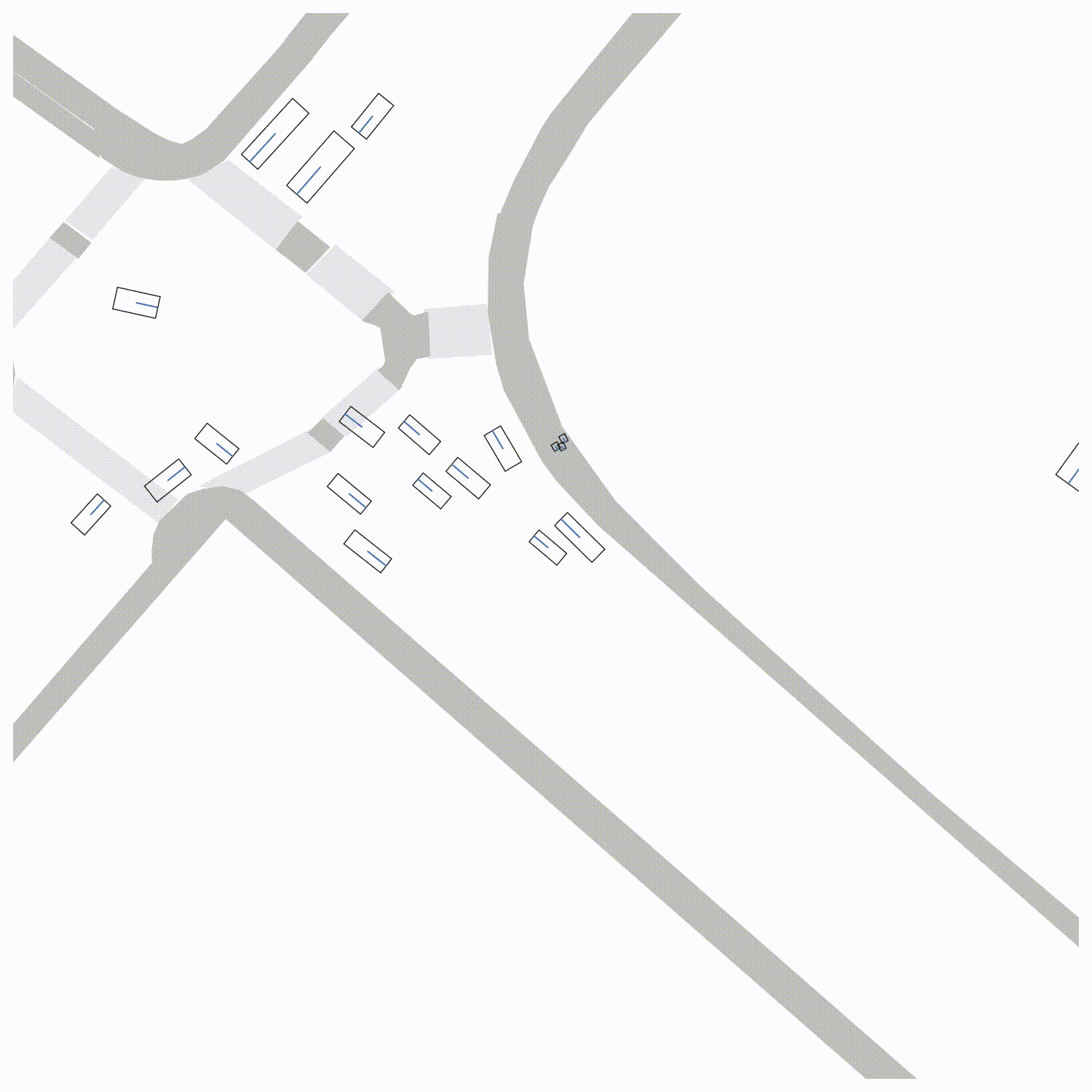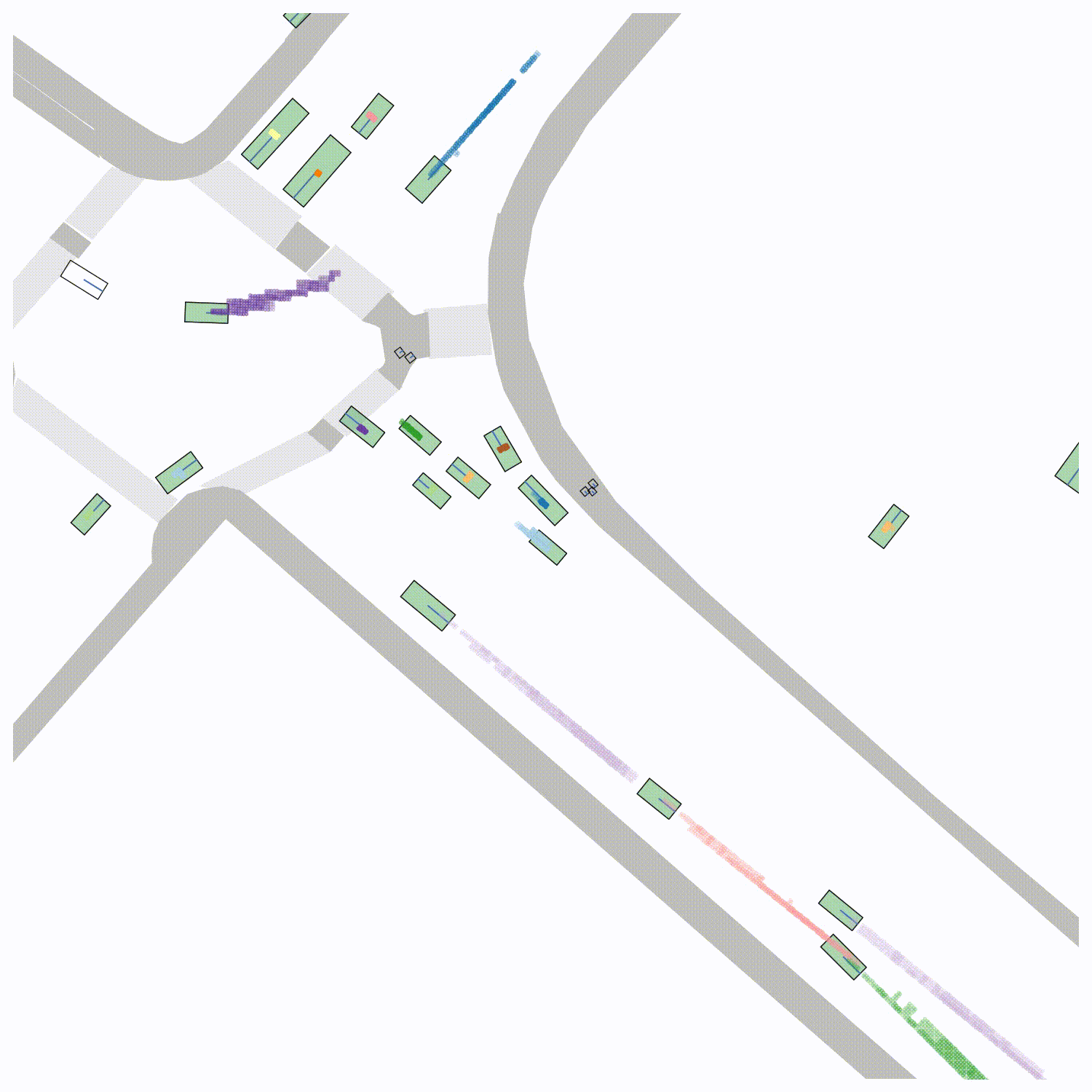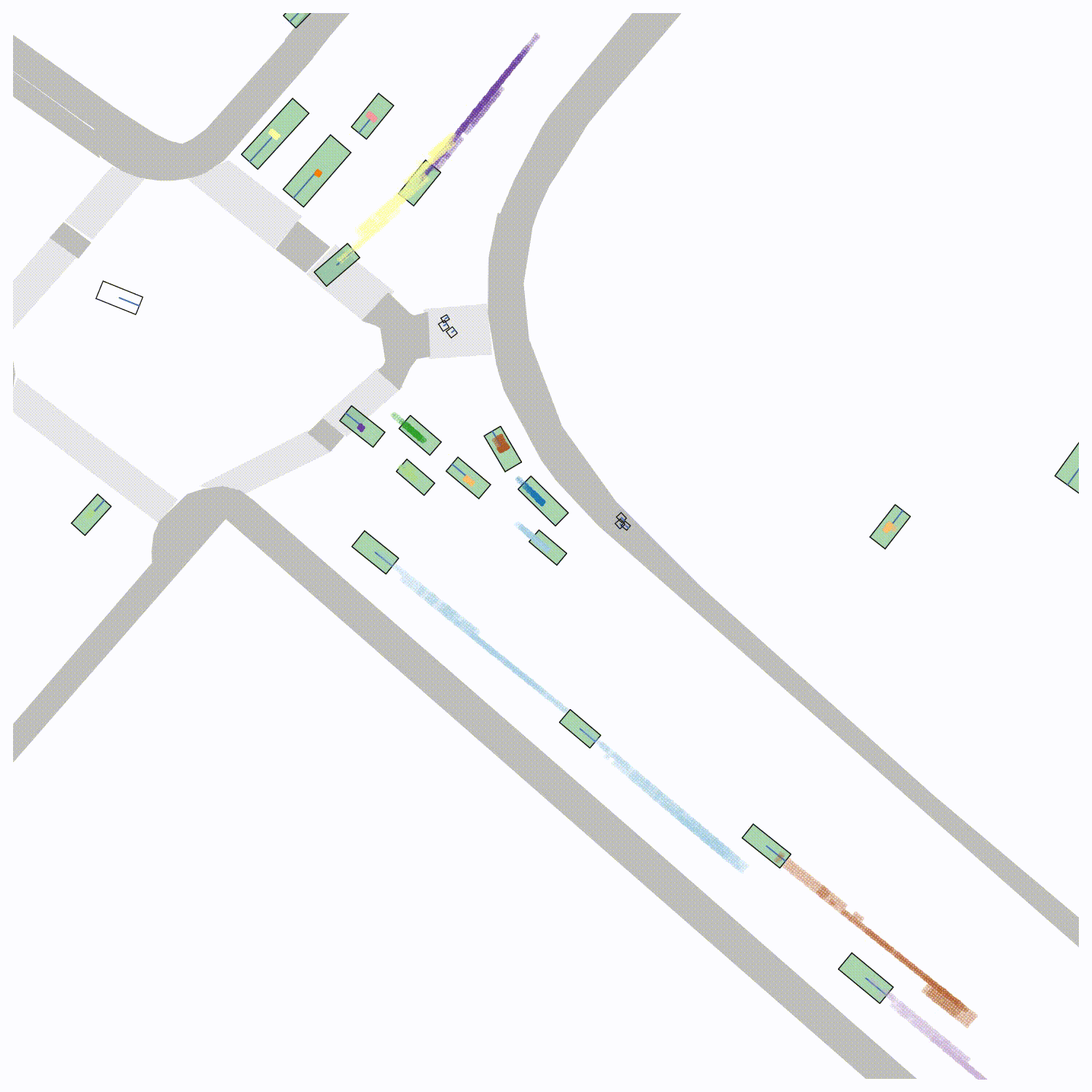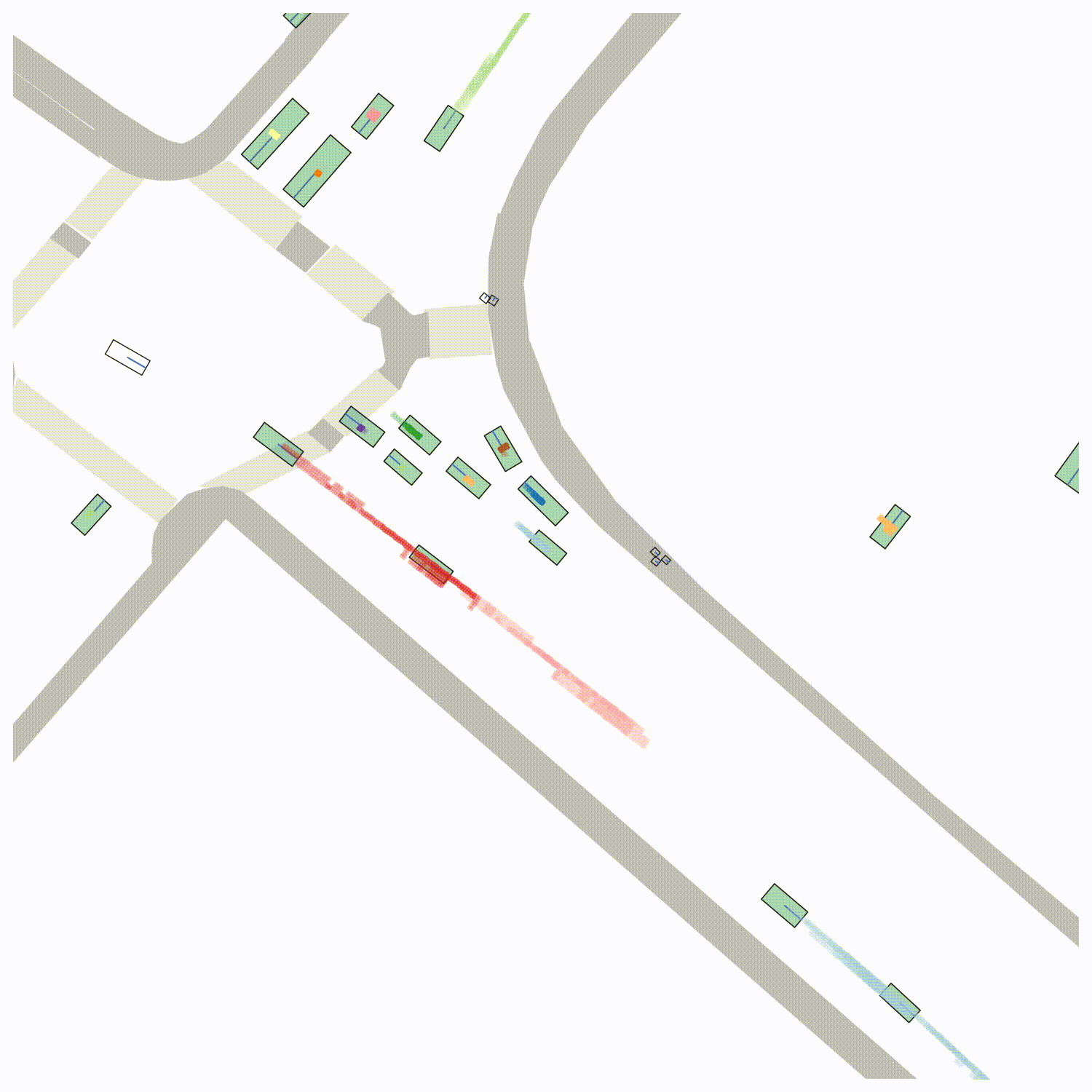
False Negative/False Positive Sensitivity We visualize the "importance" that each true object in the scene is detected correctly by removing each object from the scene and re-evaluating the PKL (left). The ego vehicle is shown in green. To visualize the sensitivity of PKL to false positives, we place false positives at each position on a grid local to the ego vehicle and evaluate the PKL (right). Qualitatively, the "worst" false negatives involve objects that are close to the ego vehicle and the "worst" false positives occur in regions where the ego vehicle is likely to travel in the future.

Human study results We submit a survey to the Amazon Mechanical Turk service in which humans are asked to vote on whether one set of detection mistakes are more dangerous than another set of detection mistakes. An example of the instructions given to the workers is shown below.

We recorded 730 responses and found that human's agreed with PKL (our metric) over NDS in 79% of scenarios. The 75 scenarios used in the survey are shown below. For each of the scenarios, the two detection sequences with different detection mistakes are shown on the left. The scene that PKL considers more dangerous is boxed in green. The comments that the workers wrote about each of the scenes are shown to the right. The comment is colored green if the commenter agreed with PKL and colored red if the commenter disagreed with PKL.

