 Toronto AI Lab
Toronto AI Lab
The task of shape space learning involves mapping a train set of shapes to and from a latent representation space with good generalization properties. Often, real-world collections of shapes have symmetries, which can be defined as transformations that do not change the essence of the shape. A natural way to incorporate symmetries in shape space learning is to ask that the mapping to the shape space (encoder) and mapping from the shape space (decoder) are equivariant to the relevant symmetries. In this paper, we present a framework for incorporating equivariance in encoders and decoders by introducing two contributions: (i) adapting the recent Frame Averaging (FA) framework for building generic, efficient, and maximally expressive Equivariant autoencoders; and (ii) constructing autoencoders equivariant to piecewise Euclidean motions applied to different parts of the shape. To the best of our knowledge, this is the first fully piecewise Euclidean equivariant autoencoder construction. Training our framework is simple: it uses standard reconstruction losses, and does not require the introduction of new losses. Our architectures are built of standard (backbone) architectures with the appropriate frame averaging to make them equivariant. Testing our framework on both rigid shapes dataset using implicit neural representations, and articulated shape datasets using mesh-based neural networks show state of the art generalization to unseen test shapes, improving relevant baselines by a large margin. In particular, our method demonstrates significant improvement in generalizing to unseen articulated poses.
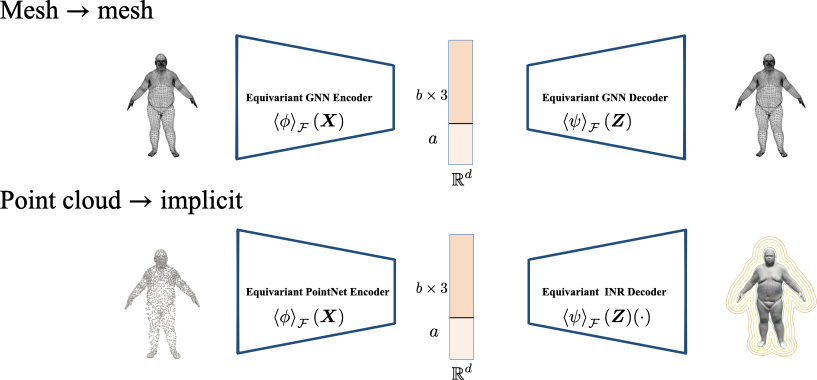
Built on the recent Frame Averaging approach, we present a unified framework for the construction of equivariant autoencoders with different 3D representations.
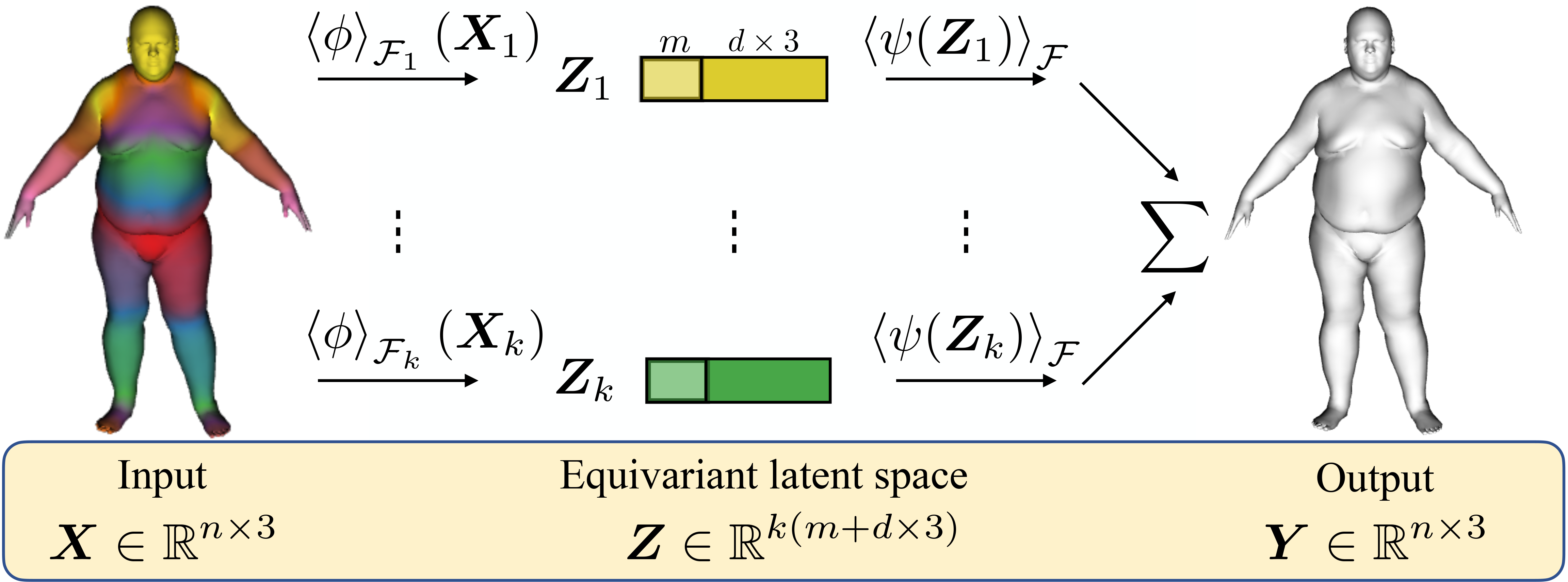
Novel construction of Piecewise Euclidean equivariant autoencoders. The suggested architecture consist of the same \(\phi\) backbone, where it is used for the equivariant encoding of each part. Similarly, the same \(\psi\) backbone is used for the equivariant decoding of each part’s latent code. Lastly, the final prediction is a weighted sum of each part’s equivariant output mesh.
Reconstruction of unseen poses using the equivariant mesh autoencoder.

CommonObject3D dataset: Global Euclidean equivariant point cloud \(\rightarrow\) implicit.

DFaust dataset: Piecewise Euclidean equivariant mesh \(\rightarrow\) mesh. Testing on poses that are unseen during training.

Interpolation in equivariant latent space between two test examples.
Ours
SNARF
Comparison with an implicit pose-conditioned method (SNARF).
@misc{atzmon2021equivariant,
title = {Frame Averaging for Equivariant Shape Space Learning},
author = {Matan Atzmon and Koki Nagano and Sanja Fidler and Sameh Khamis and Yaron Lipman},
eprint = {2112.01741},
archivePrefix={arXiv},
primaryClass={cs.CV},
year = {2021}
}
