Toronto AI Lab
Toronto AI Lab
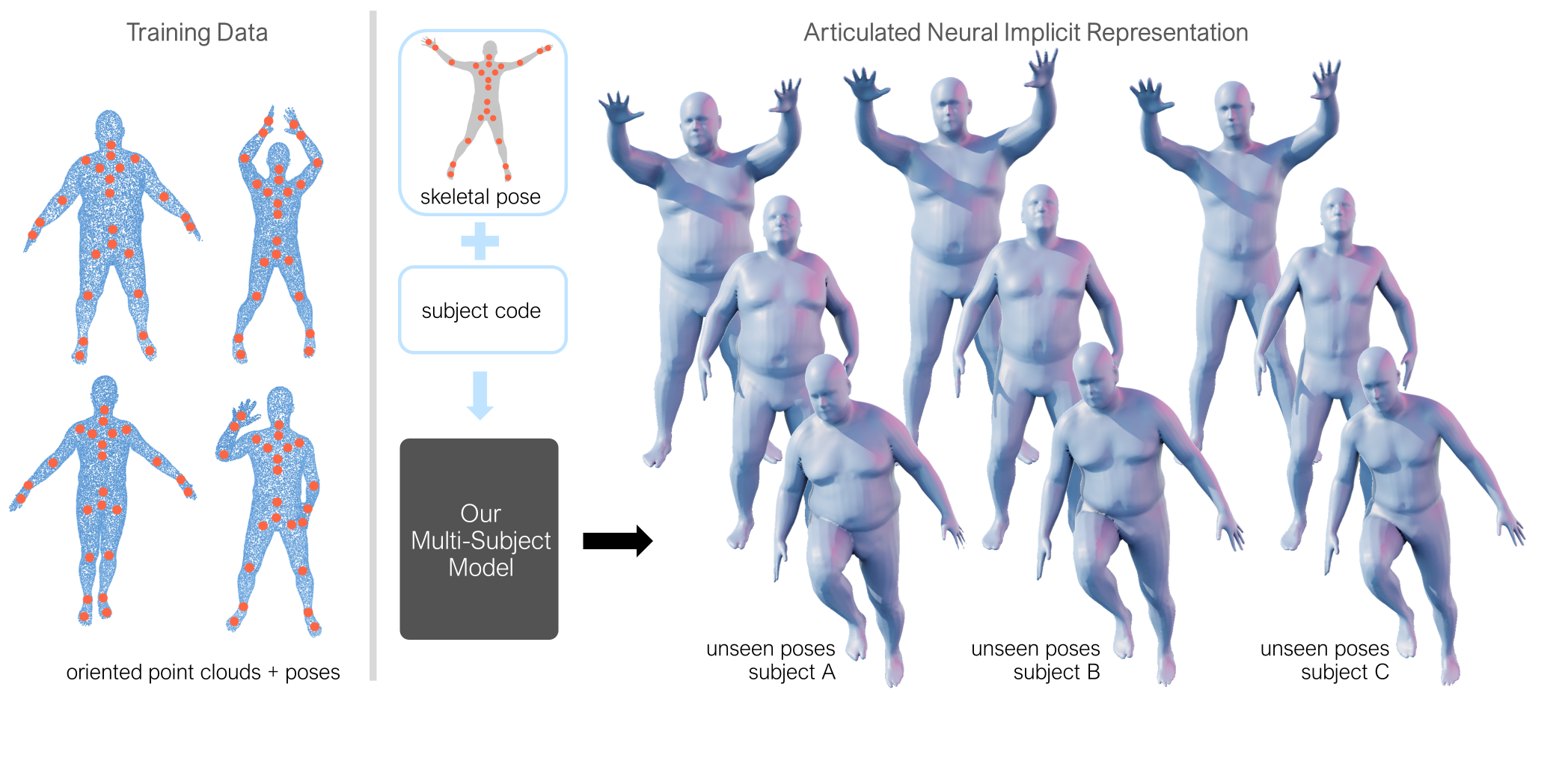
We present HIPNet, a neural implicit pose network trained on multiple subjects across many poses. HIPNet can disentangle subject-specific details from pose-specific details, effectively enabling us to retarget motion from one subject to another or to animate between keyframes through latent space interpolation. To this end, we employ a hierarchical skeleton-based representation to learn a signed distance function on a canonical unposed space. This joint-based decomposition enables us to represent subtle details that are local to the space around the body joint. Unlike previous neural implicit method that requires ground-truth SDF for training, our model we only need a posed skeleton and the point cloud for training, and we have no dependency on a traditional parametric model or traditional skinning approaches. We achieve state-of-the-art results on various single-subject and multi-subject benchmarks.
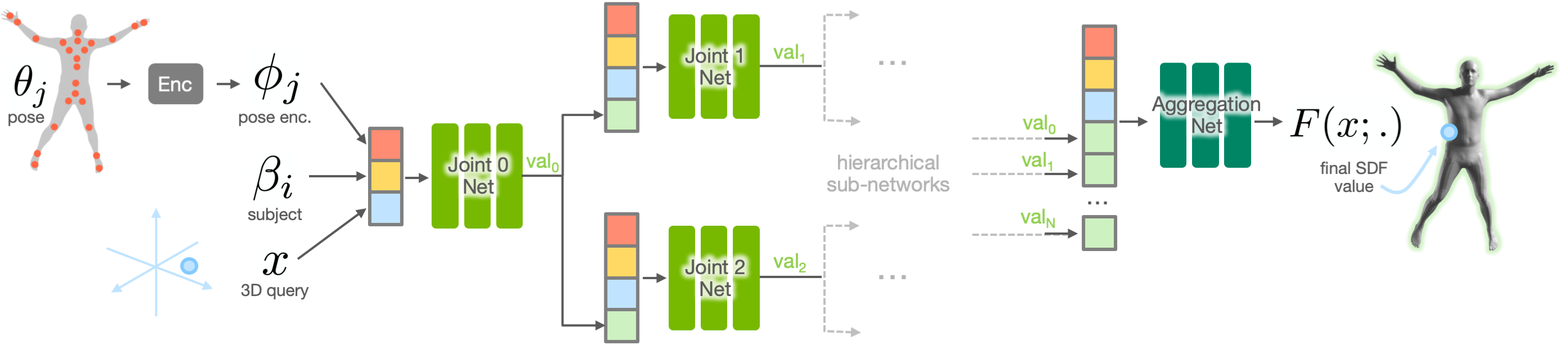
HIPNet is composed of separate sub-network MLPs arranged hierarchically according to an input skeleton. The final aggregation network is fed the results of these sub-networks an outputs the final SDF value. The subject latent codes \(\boldsymbol\beta_i\) are optimized during training, alongside the parameters of the pose encoding network \(\boldsymbol\Phi\). Refer to the text for additional details.

Unlike various prior works, our model does not require a traditional morphable model during training. Our shape space is entirely learnt from data, and our pose space is hierarchically-defined and driven by the input 3D pose, which enables us to generalize to unseen poses.

The shape space of HIPNet is entirely data-driven. We can sample new random subjects from our shape space by fitting a multivariate Gaussian to our subject embeddings.

We can fit to input point cloud data through test-time optimization. The mIoU of the reconstructed mesh is higher with a denser point cloud. More importantly, with only 1k points on the front of the mesh we are competitive with 10k points uniformly sampled everywhere. This specific setting simulates points coming from a front-facing depth sensor and is of practical importance.
@misc{biswas2021hipnet,
title = {Hierarchical Neural Implicit Pose Network for Animation and Motion Retargeting},
author = {Sourav Biswas and Kangxue Yin and Maria Shugrina and Sanja Fidler and Sameh Khamis},
eprint = {2112.00958},
archivePrefix={arXiv},
primaryClass={cs.CV},
year = {2021}
}