|
|
|
|
|
|
|
|
|
|
|
SIGGRAPH 2022
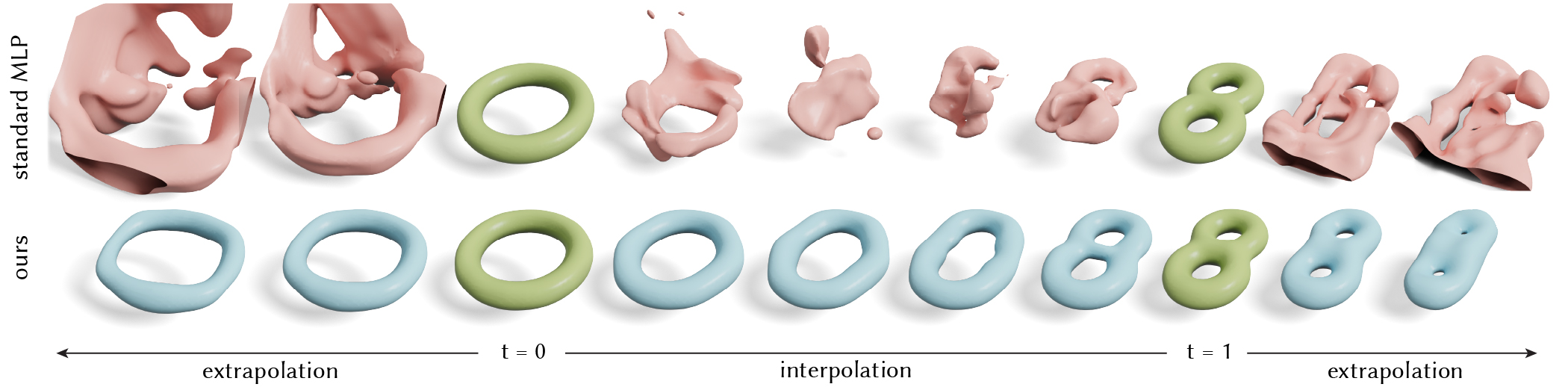 We fit neural networks to the signed distance field of a torus when the latent code t = 0 and a double torus when t = 1 (green). Our Lipschitz multilayer perceptron (MLP) achieves smooth interpolation and extrapolation results (blue) when changing t, while the standard MLP fails (red).
We fit neural networks to the signed distance field of a torus when the latent code t = 0 and a double torus when t = 1 (green). Our Lipschitz multilayer perceptron (MLP) achieves smooth interpolation and extrapolation results (blue) when changing t, while the standard MLP fails (red).
|
Neural implicit fields have recently emerged as a useful representation for 3D shapes. These fields are commonly represented as neural networks which map latent descriptors and 3D coordinates to implicit function values. The latent descriptor of a neural field acts as a deformation handle for the 3D shape it represents. Thus, smoothness with respect to this descriptor is paramount for performing shape-editing operations. In this work, we introduce a novel regularization designed to encourage smooth latent spaces in neural fields by penalizing the upper bound on the field's Lipschitz constant. Compared with prior Lipschitz regularized networks, ours is computationally fast, can be implemented in four lines of code, and requires minimal hyperparameter tuning for geometric applications. We demonstrate the effectiveness of our approach on shape interpolation and extrapolation as well as partial shape reconstruction from 3D point clouds, showing both qualitative and quantitative improvements over existing state-of-the-art and non-regularized baselines.
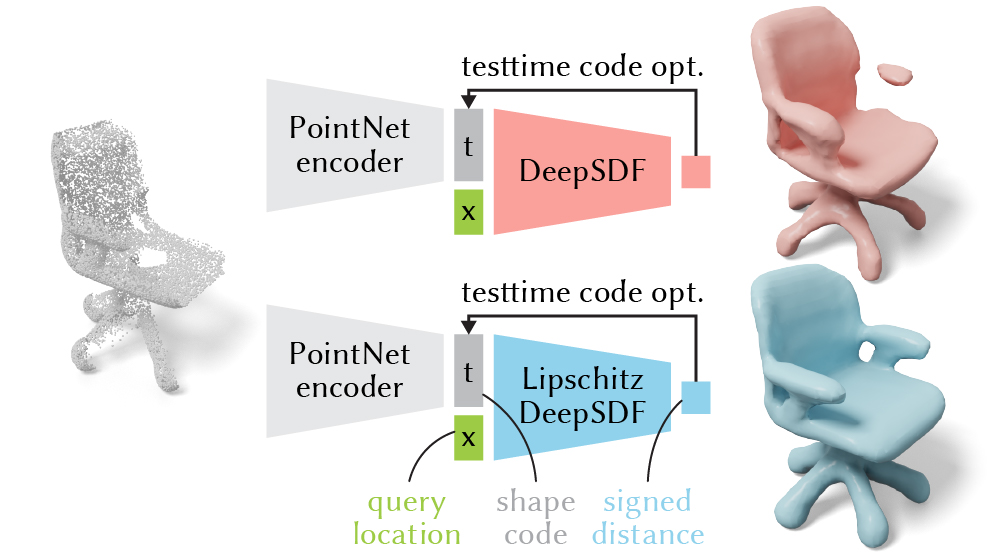
We present a method to encourage smooth solutions in a function parameterized by neural networks. This is important for geometric applications, such as reconstructing a shape from a partial point cloud. A non-smooth neural network may easily fall into bad local minima (top). A smoother neural network yields a better reconstruction (bottom).

Our key idea is to use the Lipschitz bound as a metric for smoothness of a (continuous) neural field function. Unlike traditional measures (e.g., the norm of the Jacobian) which only encourage smoothness within the training set, our notion of smoothness is defined over the entire space. Thus, it encourages smooth interpolation and extrapolation even away from the training data at t = 0 and t = 1.
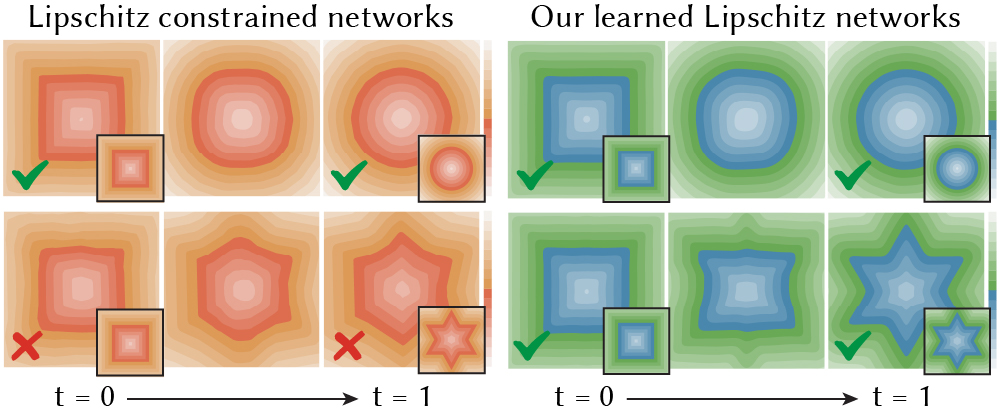
With our notion of smoothness, we can encourage smooth solutions by penalizing the Lipschitz bound of a network. This boils down to adding a Lipschitz regularization to the loss function to automatically learn the Lipschitz constant that is suitable for a given task. Compared to other methods that pre-determine the constraints on the Lipschitz bounds, our method is far less sensitive to parameter tuning.

Implementing our method is extremely simple. One only needs to make a few lines of changes to a standard MLP forward pass (see above). Jointly with the Lipschitz regularization, we can easily obtain a smooth neural network function.
|
