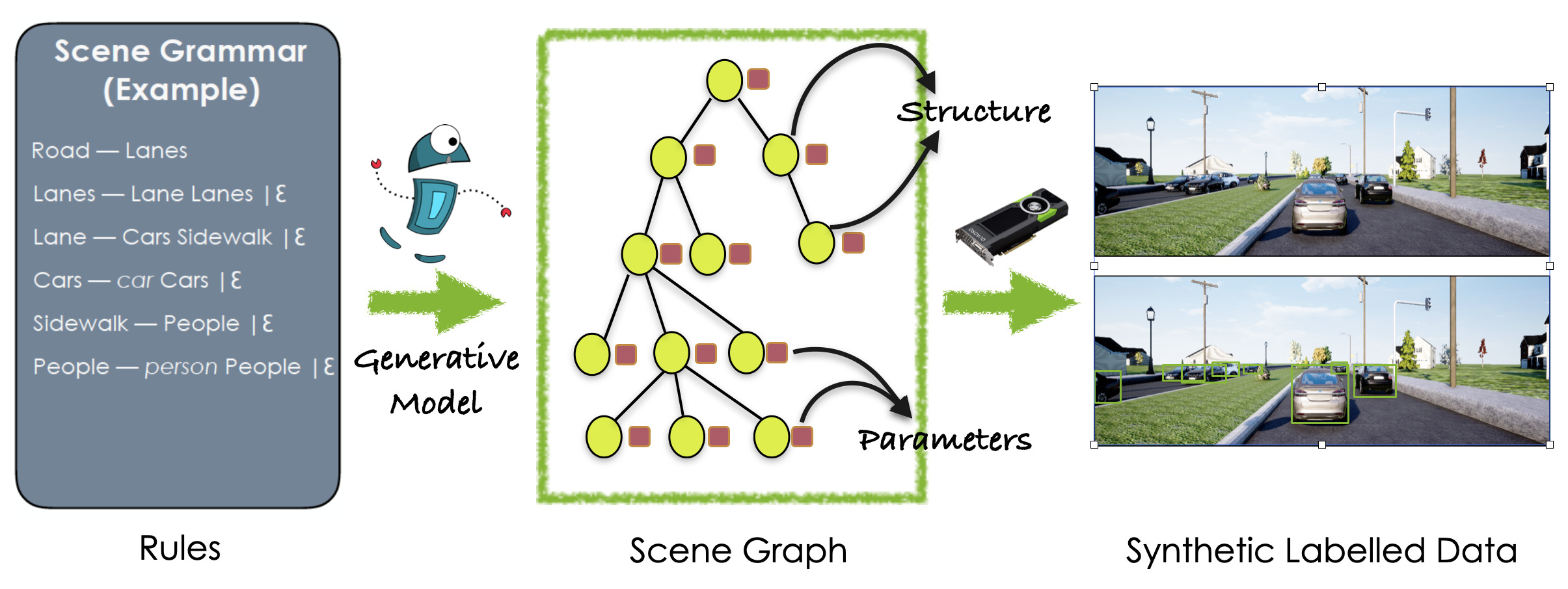
Procedural models are being widely used to synthesize scenes for graphics, gaming, and to create (labeled) synthetic datasets for ML. In order to produce realistic and diverse scenes, a number of parameters governing the procedural models have to be carefully tuned by experts. These parameters control both the structure of scenes being generated (e.g. how many cars in the scene), as well as parameters which place objects in valid configurations. Meta-Sim aimed at automatically tuning parameters given a target collection of real images in an unsupervised way. In Meta-Sim2, we aim to learn the scene structure in addition to parameters, which is a challenging problem due to its discrete nature. Meta-Sim2 proceeds by learning to sequentially sample rule expansions from a given probabilistic scene grammar. Due to the discrete nature of the problem, we use Reinforcement Learning to train our model, and design a feature space divergence between our synthesized and target images that is key to successful training. Experiments on a real driving dataset show that, without any supervision, we can successfully learn to generate data that captures discrete structural statistics of objects, such as their frequency, in real images. We also show that this leads to downstream improvement in the performance of an object detector trained on our generated dataset as opposed to other baseline simulation methods.
* denotes equal contribution. Work done during JD's internship at NVIDIA
|