Abstract
There is a growing demand for the accessible creation of high-quality 3D avatars that are animatable and customizable. Although 3D morphable models provide intuitive control for editing and animation, and robustness for single-view face reconstruction, they cannot easily capture geometric and appearance details. Methods based on neural implicit representations, such as signed distance functions (SDF) or neural radiance fields, approach photo-realism, but are difficult to animate and do not generalize well to unseen data. To tackle this problem, we propose a novel method for constructing implicit 3D morphable face models that are both generalizable and intuitive for editing. Trained from a collection of high-quality 3D scans, our face model is parameterized by geometry, expression, and texture latent codes with a learned SDF and explicit UV texture parameterization. Once trained, we can reconstruct an avatar from a single in-the-wild image by leveraging the learned prior to project the image into the latent space of our model. Our implicit morphable face models can be used to render an avatar from novel views, animate facial expressions by modifying expression codes, and edit textures by directly painting on the learned UV-texture maps. We demonstrate quantitatively and qualitatively that our method improves upon photo-realism, geometry, and expression accuracy compared to state-of-the-art methods.
Links

Videos
Qualitative Results
The following videos demonstrate single-shot avatar reconstruction with our method, which produces high-quality renderings, detailed geometry, and textured 3D assets.
Texture Editing
Compared to previous implicit representations, our hybrid implicit-explicit representation combines SDFs with UV-texture maps to allow easy texture editing.
Hybrid Representation
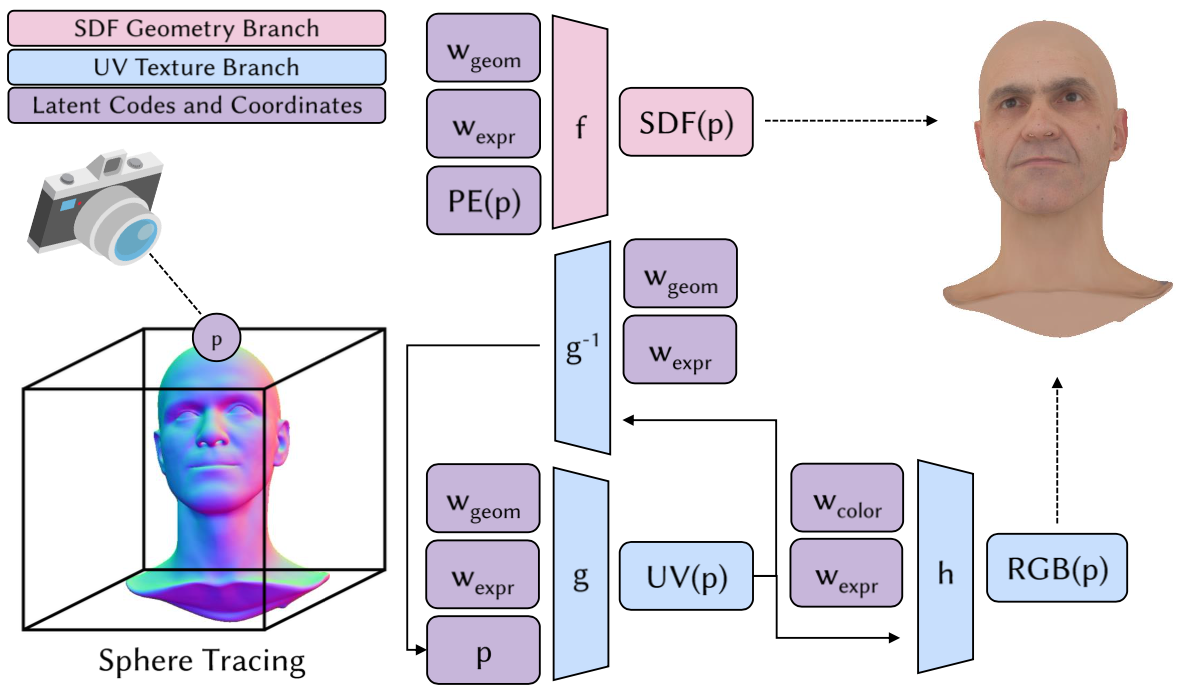
Avatars are represented by geometry, expression, and color latent codes. At each 3D coordinate p during sphere tracing, the SDF network f and UV parameterization network g predict the signed distance SDF(p) and UV coordinates UV(p), respectively. The inverse UV parameterization network g-1 regularizes the learned mapping to be a surface parameterization, while the color network h predicts the associated RGB texture RGB(p).
Inversion Pipeline

We de-light the input image [Yeh et al. 2022] and initialize the latent codes using a pre-trained encoder (top row). We then perform PTI [Roich et al. 2022] to obtain the final reconstruction (bottom row).
Interpolation
Our model learns a disentangled geometry, texture, and expression latent space, allowing for shape and facial appearance transfer.
Results on Stylized Portrait Images
Our method also extrapolates to reconstruct an avatar from a stylized portrait image.
3D Asset Extraction
Reconstructed avatars are easily extractable as 3D textured assets for downstream applications.
Citation
@inproceedings{lin2023ssif,
author = {Connor Z. Lin and Koki Nagano and Jan Kautz and Eric R. Chan and Umar Iqbal and Leonidas Guibas and Gordon Wetzstein and Sameh Khamis},
title = {Single-shot Implicit Morphable Faces with Consistent Texture Parameterization},
booktitle = {ACM SIGGRAPH 2023 Conference Proceedings},
year = {2023}
}Acknowledgments
We thank Simon Yuen and Miguel Guerrero for helping with preparing the 3D scan dataset and assets, and Ting-Chun Wang for providing the Lumos code. We also thank Nicholas Sharp, Sanja Fidler and David Luebke for helpful discussions and supports. This project was supported in part by a David Cheriton Stanford Graduate Fellowship, ARL grant W911NF-21-2-0104, a Vannevar Bush Faculty Fellowship, a gift from the Adobe corporation, Samsung, and Stanford HAI. We base this website off of the StyleGAN3 website template.