
Front-Loading Reasoning: The Synergy between Pretraining and Post-Training Data
Published:
[Paper]
Author: Syeda Nahida Akter, Shrimai Prabhumoye, Eric Nyberg, Mostofa Patwary, Mohammad Shoeybi, Yejin Choi, Bryan Catanzaro
📌 Summary:
- Front-loading reasoning data into pretraining creates a durable, compounding advantage.
- The optimal data strategy is asymmetric: prioritize diversity in pretraining and quality in SFT.
- Naive scaling of SFT data is ineffective and harmful.
- High-quality pretraining data can have a latent effect unlocked by SFT
Overview
Figure 1: Introducing reasoning data early provides a significant reasoning boost after reinforcement learning.
Large Language Models (LLMs) have become remarkably capable, yet teaching them to reason effectively remains a central challenge. The standard approach is to fine-tune a generalist model on high-quality reasoning data during post-training. But this raises a fundamental, unsettled question: is reasoning a skill best layered on at the end, or a foundational capability that should be built from the very beginning? Could we build far more powerful models by rethinking when we teach them to reason?
We introduce Front-Loading Reasoning, a strategic approach that challenges the conventional separation of training stages. Instead of reserving complex reasoning data for later, we systematically inject it directly into the pretraining phase. We pre-trained a series of 8B parameter models from scratch on 1 trillion tokens, creating controlled variants with reasoning data of differing scale, diversity, and quality. Our goal was to determine if this early exposure builds a more robust cognitive foundation that later-stage fine-tuning (SFT) and reinforcement learning (RL) can amplify.
Key Insights from Front-Loading Reasoning:
📊 Front-Loading Advantage. Reasoning data in pretraining yields durable gains that compound across later stages, with up to +19% improvement on expert-level benchmarks. This proves that SFT cannot compensate for a weak foundation and that pretraining choices dictate the final accuracy ceiling.
🌐 Asymmetric Data Strategy. - Pretraining → Diversity matters most (+11% gain from broad, mixed reasoning patterns) - SFT → Quality matters most (+15% gain from high-quality reasoning data)
⚠️ Scaling Pitfalls. Naively doubling mixed-quality SFT data hurt math performance by –5%, proving that more data is not always better.
🔓 Latent Effects. High-quality data in pretraining shows little immediate benefit but “unlocks” hidden gains during SFT (+4% boost) over model pretrained with diverse data after SFT—revealing a deeper synergy where pretraining can instill a latent potential in the model that is only activated during the alignment phase.
How we designed the Synergy experiments
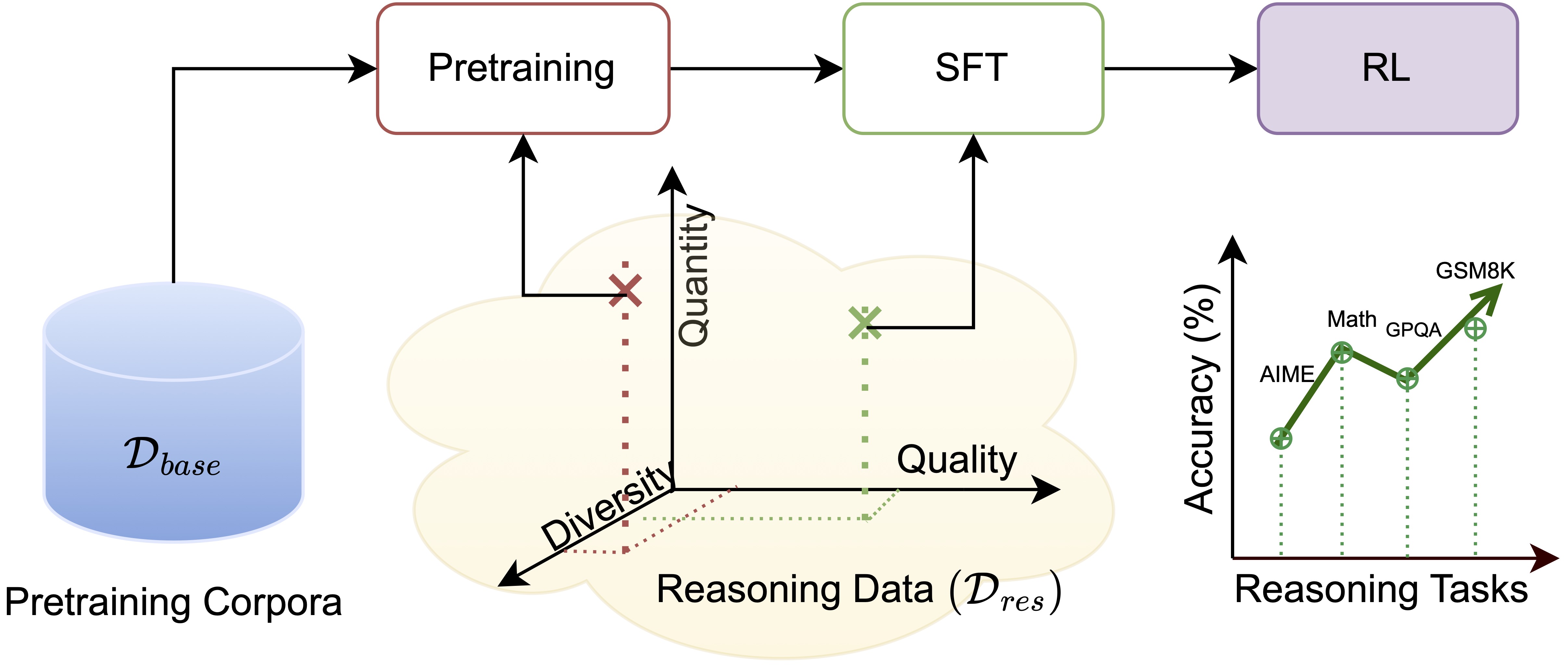
Figure 2: We systematically inject reasoning-style data at different phases of training—pretraining versus SFT—while varying its diversity, quantity, and quality.
🧩 Stage 1 — Pretraining
- Train 8B models from scratch on 1T tokens.
- Mix 80% general corpus + 20% reasoning data.
- Variants:
- Large-scale/diverse (336B tokens)
- Small/high-quality (4B examples)
- Mixed (combined)
- None (baseline)
🎯 Stage 2 — Supervised Fine-Tuning (SFT)
- Finetune each model on reasoning datasets of varying quality, diversity, and complexity.
- Test three hypotheses:
- Can SFT-stage more high-quality data “catch up”?
- Does broad/diverse pretraining create stronger foundations?
- Do longer, complex answers help more at SFT?
⚖️ Stage 3 — Reinforcement Learning (RLVR)
- Apply GRPO with verifiable rewards.
- Measure if early reasoning advantages persist after alignment.
🔍 Key Dimension Tested
- Synergy between pretraining & SFT.
- Marginal gains of scaling SFT data.
- Impact of quality, diversity & complexity across stages.
Potential of Front-Loading
To understand the real value of Front-Loading Reasoning, we tracked the performance of our models at every stage of the training pipeline. We compared our baseline model, pretrained with no reasoning data (No-Reason Base), against our reasoning-pretrained models (Reason-Base).
Figure 3: (Left) Pretraining with diverse reasoning data yields immediate gains. (Right) SFT amplifies the pretraining advantage—models with reasoning-rich pretraining significantly outperform baseline.
🔥 Key Takeaways:
- Immediate Gains After Pretraining: Right out of the gate, the Reason-Base models showed a +16% average improvement over the No-Reason Base. The biggest gains were in math (+28.4%) and code (+9%), proving that front-loading builds a stronger foundation immediately.
- Advantage Amplified After SFT: After all models underwent the same SFT process, the advantage didn’t shrink—it grew. The Reason-Base models were +9.3% better on average, with massive gains in science, a domain where post-training alone often struggles. This proves that a strong SFT phase cannot compensate for a weak, reasoning-deficient start.
- Dominant Performance After RL: After reinforcement learning, the Reason-Base model finished with a stunning +19% average lead. On the most difficult competition math problems (AIME), this advantage ballooned to a +39.3% gain.
Why Does Front-Loading Work So Well? Unlike traditional approaches that treat reasoning as a skill to be added on later, Front-Loading Reasoning integrates logical structures into the model’s core understanding from the very beginning. This does two critical things:
- It builds a durable foundation. Instead of just memorizing facts, the model learns the patterns of reasoning alongside its general knowledge.
- It enhances the model’s capacity to learn from later stages. SFT and RL become far more effective because they are refining an already-capable foundation, not trying to build one from scratch.
Ultimately, Front-Loading shows that when you teach a model to reason is just as important as what you teach it.
➣ Scale and Diversity in Pretraining Pay Off
💡 Broad exposure builds the strongest reasoning foundations.
Figure 4: Pretraining gains improve with scale and diversity, driving math and code improvements. (SHQ: Small-Scale, High Quality Data; LDQ: Large-Scale, Diverse Data; LMQ: Large-Scale, Mixed Quality Data)
Models pretrained on large, diverse reasoning data outperform those trained on smaller, high-quality but narrow corpora by +9.09% on average—especially in math, science, and code. Simply mixing in additional high-quality data provides minimal extra benefit, underscoring that scale and diversity dominate at the pretraining stage.
➣ Pretraining Advantage Persists Beyond SFT
💡 You can’t “catch up” later by throwing more data at SFT.
Figure 5: Doubling SFT for the baseline fails to “catch up” to reasoning-pretrained model. (SHQ: Small-Scale, High Quality Data)
Doubling SFT data for the baseline improves performance by +4.09%, but it still falls short of even the weakest reasoning-pretrained model (+3.32%). This shows that early reasoning exposure builds irreplaceable foundations that SFT alone cannot replicate.
➣ Latent Value of High-Quality Data
💡 Quality data in pretraining can “unlock” hidden gains during SFT.
Figure 6: The latent advantage of the mixed-quality pretraining emerges after SFT.
While scaling with high-quality but narrow data shows muted benefits at pretraining, after SFT it delivers an additional +4.25% boost over diverse-only pretraining. This reveals that high-quality data acts as a latent amplifier, whose effects emerge only after alignment.
Conclusion
We propose Front-Loading Reasoning that shows reasoning belongs in pretraining, not just post-training. Early, diverse exposure builds durable foundations, while high-quality data pays off most during SFT. The key is an asymmetric strategy: scale and diversity first, quality later. Done right, reasoning-aware pretraining creates models that are stronger, more generalizable, and more efficient.
Citation
@misc{akter2025frontloadingreasoningsynergypretraining,
title={Front-Loading Reasoning: The Synergy between Pretraining and Post-Training Data},
author={Syeda Nahida Akter and Shrimai Prabhumoye and Eric Nyberg and Mostofa Patwary and Mohammad Shoeybi and Yejin Choi and Bryan Catanzaro},
year={2025},
eprint={2510.03264},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2510.03264},
}