
Figure 1: Preview of our 3D video conferencing experience, rendering NeRFs from a single RGB webcam and streaming to a Looking Glass light field display.
Abstract
We present an AI-mediated 3D video conferencing system that can reconstruct and autostereoscopically display a life-sized talking head using consumer-grade compute resources and minimal capture equipment. Our 3D capture uses a novel 3D lifting method that encodes a given 2D input into an efficient triplanar neural representation of the user, which can be rendered from novel viewpoints in real-time. Our AI-based techniques drastically reduce the cost for 3D capture, while providing a high-fidelity 3D representation on the receiver's end at the cost of traditional 2D video streaming. Additional advantages of our AI-based approach include the ability to accommodate both photorealistic and stylized avatars, and the ability to enable mutual eye contact in multi-directional video conferencing. We demonstrate our system using a tracked stereo display for a personal viewing experience as well as a light field display for a multi-viewer experience.
Links

Experiences
Figure 2: Overview of our Emerging Technologies demo. Slides are displayed in 3D on a Looking Glass 3D Display.

Figure 3: Preview of our SIGGRAPH Emerging Technologies demo booth.
AI 3D Selfie
We use a one-shot method to infer and render a photorealistic 3D representation from a single unposed image in real time. We generate 45-view light field images on an NVIDIA RTX A5000 laptop, using instant AI super-resolution, and participants view their 3D selfies on a Looking Glass Portrait display.
Figure 4: Preview of our AI 3D Selfie experience. A user takes a selfie and views the rendered 3D selfie on the Looking Glass Portrait display.
Live 3D Portrait
We show 2D avatar animation and real-time 3D lifting from a single webcam. In real time, participants can see their 2D webcam capture lifted into a head-tracked stereo 3D view. They can also swap their appearance with an animated avatar that tracks their expressions. To achieve this, we use cloud-based AI inference on an NVIDIA RTX 6000 Ada Generation GPU to generate the 3D portrait, and we display the portrait with head-tracked stereo rendering on Acer SpatialLabs 3D laptops.
Figure 5: Preview of our Live Portrait 3D experience. A user watches themselves lifted into 3D from the monocular webcam, and they swap their rendered appearance with animated avatars.
3D Video Conferencing
We show 3D video conferencing for two or three users, lifting 3D video from monocular RGB input. We capture video from a commodity webcam, lift the 2D faces into NeRFs and stream in real time with NVIDIA RTX 6000 GPUs, and render the NeRFs as light fields for a Looking Glass 3D display on an NVIDIA RTX 4090. We enable eye contact through pose redirection and use NVIDIA Maxine Audio Effects SDKs with spatial audio.
Figure 6: Preview of our 3D video conferencing experience.
Key Features
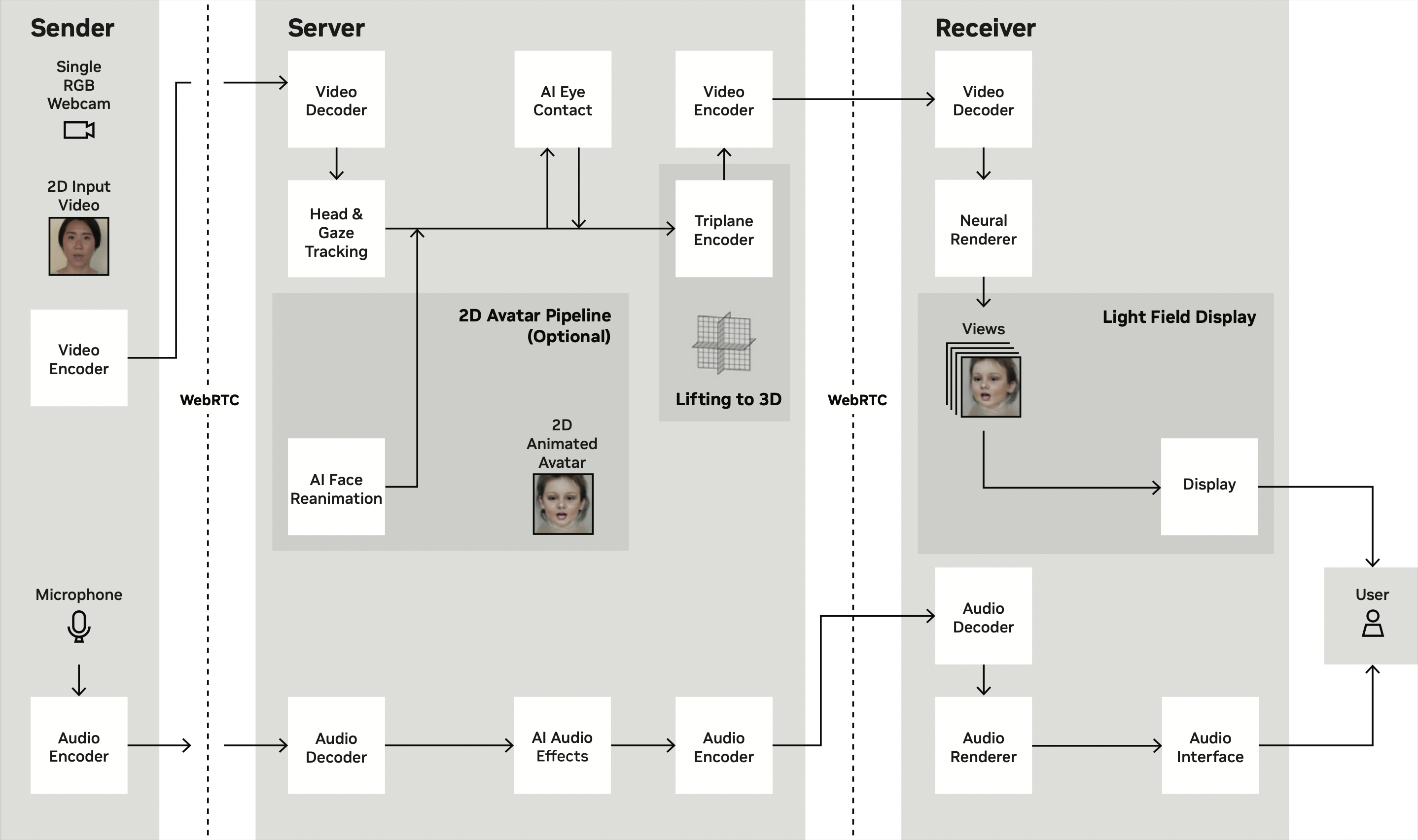
Figure 7: Overview of our encoder architecture and training pipeline for our proposed method.
System Overview
Our system captures 2D video, lifts the 2D representation to 3D using a triplane encoder, and streams the triplane representation to be rendered at the 3D display. A neural renderer generates multiple views for the 3D display. Our 3D lifting technology can be offloaded to the cloud for efficient processing.
Single-shot 3D Lifting
We achieve real-time single-shot 3D lifting using a triplane encoder. Our triplane encoder is trained entirely on synthetic data generated from a pretrained 3D-aware image generator (EG3D). The EG3D model we use was trained on FFHQ and other proprietary face datasets. Please refer to the the technical paper for more details.
We made several improvements to the SIGGRAPH technical paper version to improve performance and stability for our demo. These improvements include foreground-aware 3D lifting, wider cropping to reconstruct the whole head, increased training data to support challenging side-profile view inputs, and adaptive camera pose estimation to correct for possible misalignments.
The example videos below compare our previous model used for the paper release to our current model. The first row shows the input image and output produced by our previous model. The second row shows the input image and results from our current model: output with a synthetic background, output without a background, and the alpha mask.
We also show comparison results of the previous and current model running frame-by-frame on input video sequences. The first row shows the input video and output video from running our previous model. The second row shows the input video, output video with and without a synthetic background, and the alpha mask, all produced by our current triplane encoder model.
Real-Time Pipeline
We optimized our encoder's performance using NVIDIA TensorRT for real-time inference on NVIDIA A6000 Ada Generation GPUs. The system pipeline runs in less than 100 milliseconds end-to-end, including capture, streaming, and rendering. The different client endpoints in our system communicate via Ethernet. We render to 3D displays using the NVIDIA CUDA SDK and OpenGL shaders.
3D Display Compatibility
Our system supports multiple off-the-shelf 3D displays. The AI 3D Selfie demo is shown on a Looking Glass Portrait, and the Live 3D Portrait demo uses Acer SpatialLabs laptops. The 3D video conferencing demo uses Looking Glass 32" 3D displays inside each booth.
Citation
@inproceedings{stengel2023,
author = {Michael Stengel and Koki Nagano and Chao Liu and Matthew Chan and Alex Trevithick and Shalini De Mello and Jonghyun Kim and David Luebke},
title = {AI-Mediated 3D Video Conferencing},
booktitle = {ACM SIGGRAPH Emerging Technologies},
year = {2023}
}Acknowledgments
We base this website off of the StyleGAN3 website template.