We scale neural volume rendering to high resolution by rendering every pixel to ensure that
"what you see in 2D, is what you get in 3D"
Drag cursor to change the split
Teaser Video
Abstract
3D-aware Generative Adversarial Networks (GANs) have shown remarkable progress in learning to generate multi-view-consistent images and 3D geometries of scenes from collections of 2D images via neural volume rendering. Yet, the significant memory and computational costs of dense sampling in volume rendering have forced 3D GANs to adopt patch-based training or employ low-resolution rendering with post-processing 2D super resolution, which sacrifices multiview consistency and the quality of resolved geometry. Consequently, 3D GANs have not yet been able to fully resolve the rich 3D geometry present in 2D images. In this work, we propose techniques to scale neural volume rendering to the much higher resolution of native 2D images, thereby resolving fine-grained 3D geometry with unprecedented detail. Our approach employs learning-based samplers for accelerating neural rendering for 3D GAN training using up to 5 times fewer depth samples. This enables us to explicitly render every pixel of the full-resolution image during training and inference without post-processing superresolution in 2D. Together with our strategy to learn high-quality surface geometry, our method synthesizes high-resolution 3D geometry and strictly view-consistent images while maintaining image quality on par with baselines relying on post-processing super resolution. We demonstrate state-of-the-art 3D gemetric quality on FFHQ and AFHQ, setting a new standard for unsupervised learning of 3D shapes in 3D GANs.
Links

Results
By volume rendering every pixel, our method can generate strict multi-view-consistent images and resolves the fine-grained 3D geometry at the full-resolution of 2D images. The video below visualizes a neural rendering output as well as renderings of surface normal and extracted 3D geometry of a sample generated by our method.
Qualitative results on FFHQ and AFHQ
The split view shows high degree of alignment between the 3D rendering and corresponding geometry.
Interpolation
Our method can generated geometrically-aligned fine-grained details while smoothly interpolating samples in the latent space. The video below demonstrates interpolations between latent vectors with FFHQ.
Single-view 3D Reconstruction
We utilize our learned prior over 3D faces for single-image 3D reconstruction, using Pivotal Tuning Inversion to invert real images and recover 3D shapes and novel views. Our method reconstructs highly detailed 3D geometry from a single input image.
Flexible FOVs during Inference
Volume rendering every pixel allows for flexible FOVs during inference.
Methodology
Learning High-Resolution 3D Geometry by Rendering Every Pixel
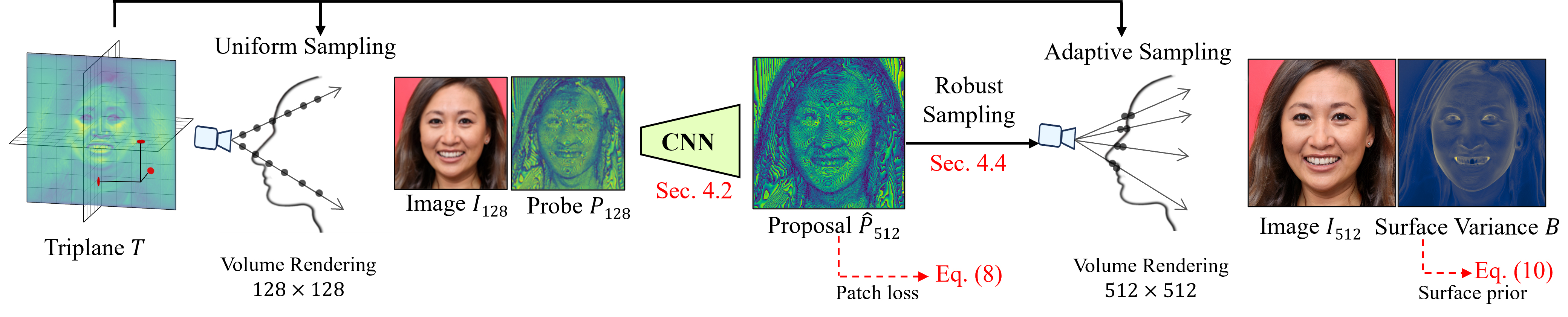
Training a 3D generative model with neural volume rendering requires sigificant time and memory since the model needs to densely sample and evaluate the scene volume. We propose a set of techniques to scale neural volume rendering to the full-resolution image by significantly reducing required sample counts. We (1) propose a generalizable learned sampler conditioned on cheap low-resolution information, that guides where to place depth samples while the 3D scenes evolve during training; and (2) introduce an SDF-based 3D GAN to represent high-frequency geometry with spatially-varying surface tightness that increases throught training, in turn facilitating low sample rendering.
Ablations on NeRF Sampling

We show sampling ablations in comparison to our full method (right). Without any proposal network (left), naive two-pass sampling results in severe undersampling and significantly degraded renderings. Standard unstratified inverse transform sampling of the proposals (middle) results in collapsed geometry.
Ablations on Beta Regularization

Here we show the effects of regularizing the beta field learned during GAN training. Our method (right) results in sharper renderings and significantly smoother geometry than the baseline without beta regularization (left).
Comparisons
We compare our method to the state-of-the-art 3D-aware generative models. Our method produces significantly higher fidelity 3D geometry (e.g., well-defined ears and isolated clothing collar).
Citation
@inproceedings{Trevithick2023,
author = {Alex Trevithick and Matthew Chan and Towaki Takikawa and Umar Iqbal and Shalini De Mello and Manmohan Chandraker and Ravi Ramamoorthi and Koki Nagano and},
title = {Rendering Every Pixel for High-Fidelity Geometry in 3D GANs},
booktitle = {arXiv},
year = {2023}
}Acknowledgments
We thank David Luebke, Tero Karras, Michael Stengel, Amrita Mazumdar, Yash Belhe, and Nithin Raghavan for feedback on drafts and early discussions. Koki Nagano was partially supported by DARPA's Semantic Forensics (SemaFor) contract (HR0011-20-3-0005). The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the U.S. Government. This work was funded in part by an NSF Graduate Fellowship, ONR Grant N00014-23-1-2526, and the Ronald L. Graham Chair. Manmohan Chandraker acknowledges support of of NSF IIS 2110409. Distribution Statement "A" (Approved for Public Release, Distribution Unlimited). We base this website off of the EG3D website template and DreamFusion split view demo template.