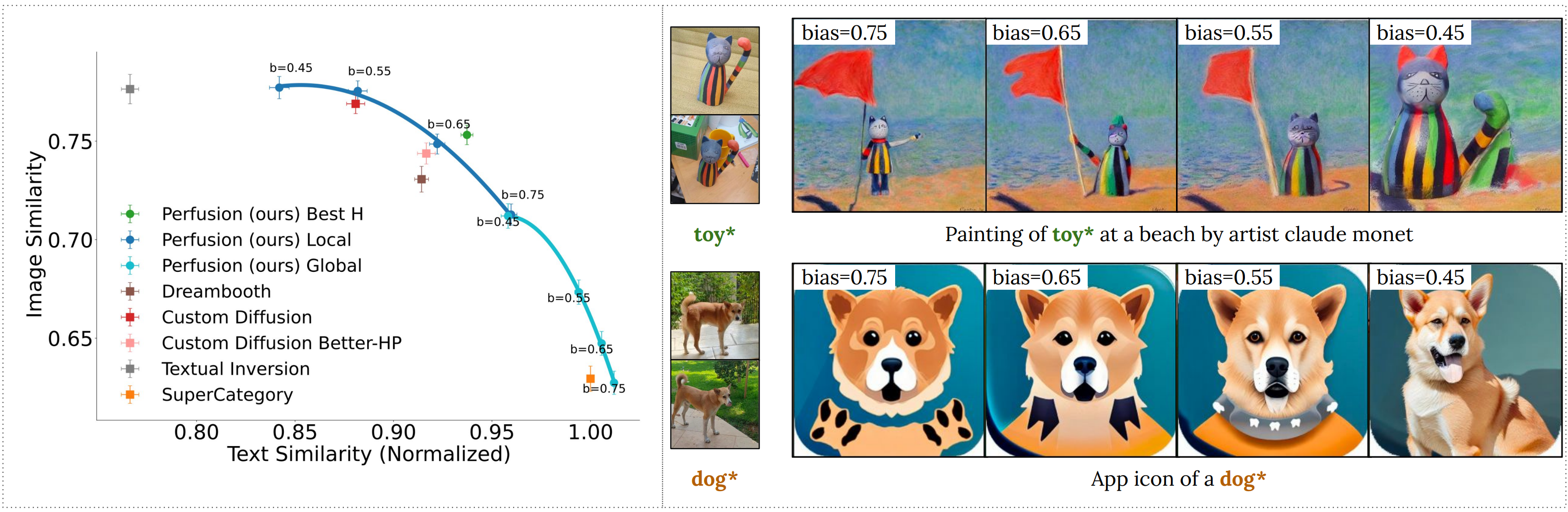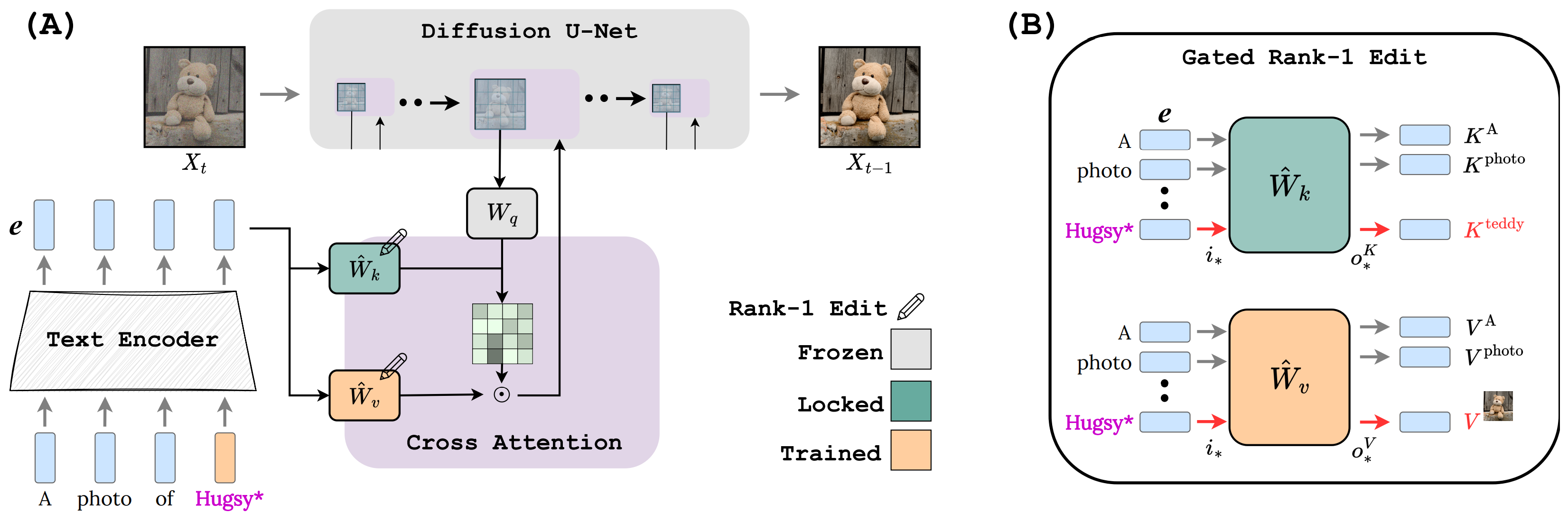
Perfusion can enable more animate results, with better prompt-matching and less susceptibility to background traits from the original image.
For each concept, we show exemplars from our training set, along with generated images,
their conditioning texts and comparisons to Custom-Diffusion and Dreambooth baselines.