Federated Learning with Heterogeneous Architectures using Graph HyperNetworks
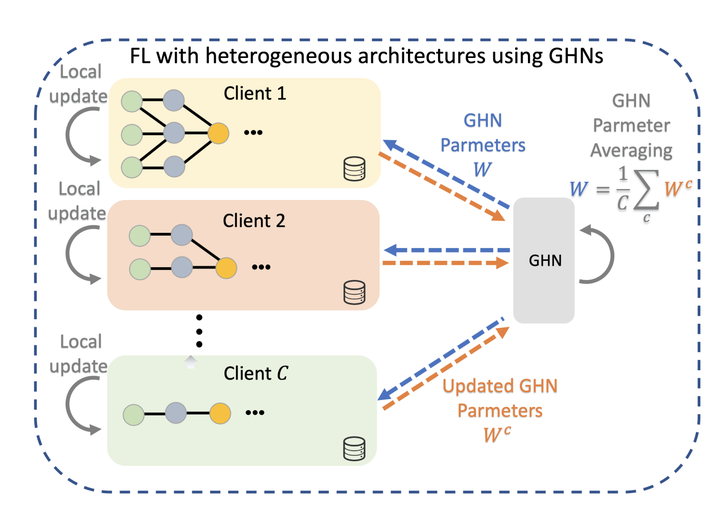
Standard Federated Learning (FL) techniques are limited to clients with identical network architectures. This restricts potential use-cases like cross-platform training or inter-organizational collaboration when both data privacy and architectural proprietary are required. We propose a new FL framework that accommodates heterogeneous client architecture by adopting a graph hypernetwork for parameter sharing. A property of the graph hyper network is that it can adapt to various computational graphs, thereby allowing meaningful parameter sharing across models. Unlike existing solutions, our framework does not limit the clients to share the same architecture type, makes no use of external data and does not require clients to disclose their model architecture. Compared with distillation-based and non-graph hypernetwork baselines, our method performs notably better on standard benchmarks. We additionally show encouraging generalization performance to unseen architectures.