
1. Addressability
Temporal RoPE offsets exceed the training range, so cached memories become unreadable even when they are physically present. Past the trained window, attention queries see phases the model never learned to address.
 Spatial Intelligence Lab
Spatial Intelligence Lab
TL;DR. WorldTrace keeps compressed memory addressable with fixed in-distribution slot positions, then uses canonical-key writers for two goals: WorldTrace-Field for smoother long rollouts and WorldTrace-Landmark for recalling previously visited scenes, all without retraining the generator.
We study visual persistence in autoregressive video world models, where Key–Value (KV) caches store growing visual memory but become hard to retrieve from beyond the training horizon. We identify out-of-distribution temporal RoPE offsets as the root cause: past observations may remain cached, yet become unaddressable to attention. WorldTrace is a training-free framework that keeps compressed memory addressable by assigning each slot a fixed, in-distribution position relative to the current frame. Built on this addressable cache, WorldTrace-Field improves coherent long rollouts with rotation-invariant history aggregation, while WorldTrace-Landmark preserves verbatim scene traces for long-range recall.
Autoregressive video world models promise interactive worlds, but visual persistence collapses once generation exceeds the training horizon.
Can an autoregressive video world model reliably remember where it has been, at any generation length?
Two coupled bottlenecks arise once generation crosses the training context window:
Temporal RoPE offsets exceed the training range, so cached memories become unreadable even when they are physically present. Past the trained window, attention queries see phases the model never learned to address.
Naive key averaging in RoPE-rotated space mixes incompatible phases. The resulting phase cancellation destroys the signal that compressed summaries are supposed to carry.
A two-tier KV cache: a verbatim recent window plus $N_s$ summary slots, with positions assigned by slot rank alone (independent of horizon) so every summary stays in-distribution at any generation length. Two complementary writers fill the slots:

Virtual position for summary slot $s$:
$q$ is the current query position, $L_{\mathrm{train}}$ is the training context length, and $F$ is the number of frames per autoregressive block. Slot positions depend on rank, not rollout length.
Keys are first aligned into a shared canonical phase, averaged, then re-rotated to the summary slot position. This avoids phase cancellation and preserves mean attention logits. WT-Field targets temporal coherence under compression; not a recall mechanism.
Scene-entry frames are detected from the canonical-key signal, stored verbatim into summary slots, and frozen on insertion to avoid bfloat16 drift from repeated unrotate→rerotate shifts. WT-Landmark keeps slot-rank positions unchanged and targets episodic recall over long rollouts.
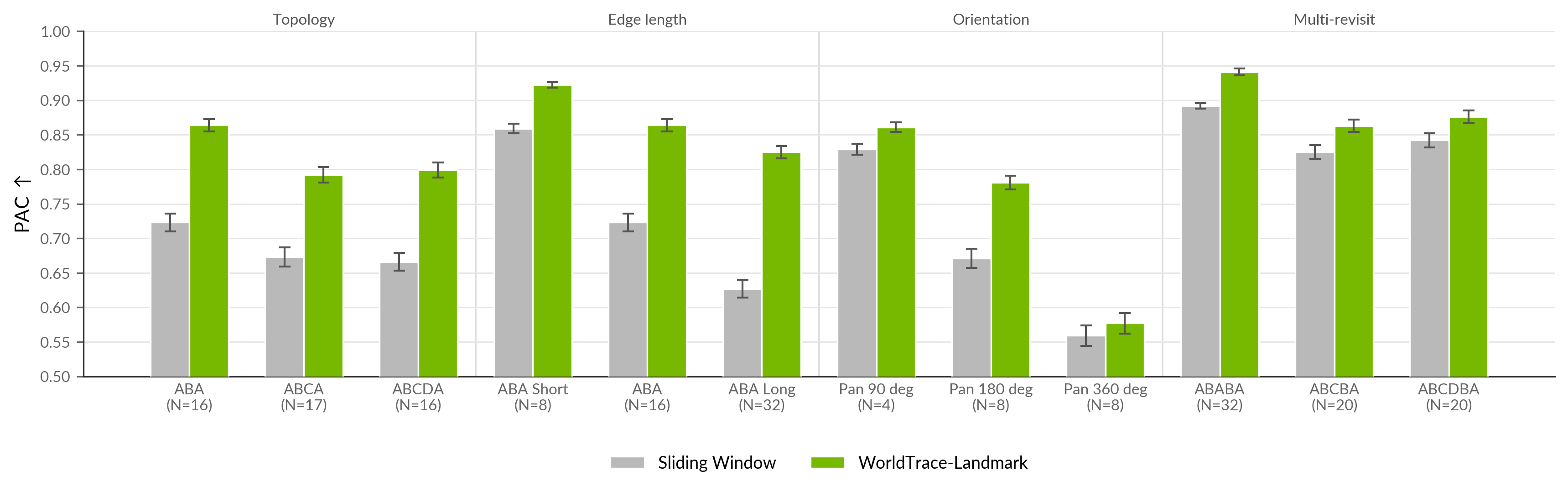
LoopMem tests episodic recall by asking the model to return to previously visited scenes and scoring the regenerated view with Position-Aligned CLIP (PAC). Across topology, path length, camera orientation, and multi-revisit settings, WT-Landmark consistently improves over sliding-window recall: 0.825 vs. 0.627 PAC on the long ABA path, 0.864 vs. 0.723 on standard ABA, and 0.941 vs. 0.892 on ABABA. The hardest $360^\circ$ pan shows the smallest gain (0.577 vs. 0.559), making the limitation visible rather than hidden by the aggregate.
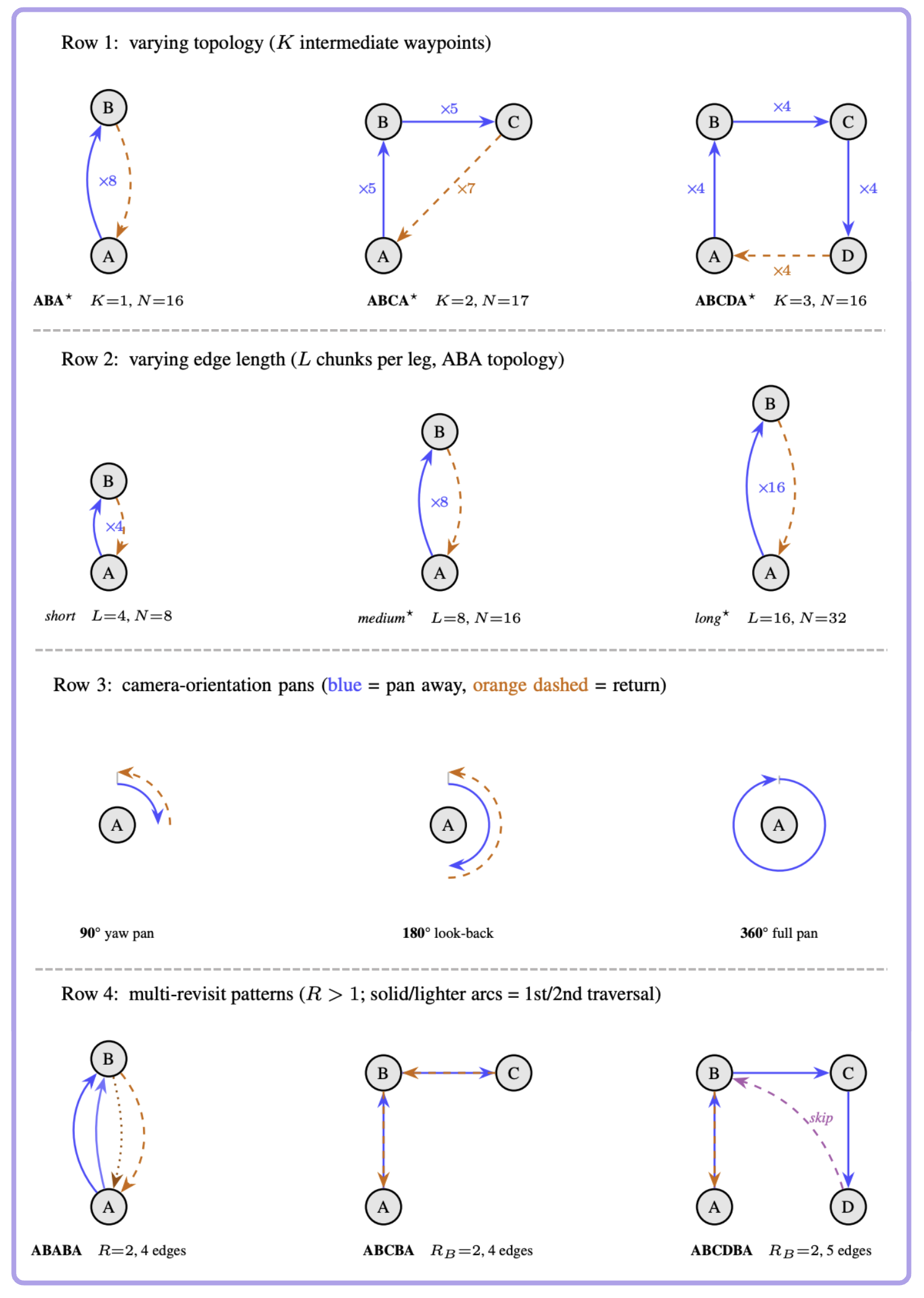
Vary the number of intermediate waypoints before returning to the starting scene.
Increase the number of generated chunks per leg to stretch context distance.
Stress recall under camera-orientation changes, including wide pans.
Revisit the same place multiple times to test repeated episodic recall.





Holding the content operator fixed (canonical averaging) and varying only the position assignment, slot-rank positions lead Block-Rel by +5.9% TempSSIM at 8× horizon and +2.8% at 16×. At 24× (N=48), WT-Field improves +15.5% TempSSIM over sliding-window while also lowering Local Scene Drift, where every $N$-dependent position formula degrades non-monotonically.
@inproceedings{wu2026worldtrace,
title={Addressable Memory for Video World Models},
author={Xindi Wu and Sven Elflein and James Lucas and Olga Russakovsky and Laura Leal-Taix\'{e} and Despoina Paschalidou and Jonathan Lorraine and Aljo\v{s}a O\v{s}ep},
booktitle={ICML 2026 Workshop: From Frames to Stories (F2S)},
note={Oral presentation},
year={2026},
}