NVIDIA OmniDreams
Real-Time Generative World Model for Closed-Loop Autonomous Vehicle Simulation
 Technical Report
Technical Report
 Model
Model
 Code
Code
Right: Reasoning VLA driving policy, the Alpamayo 1 model, driving closed-loop inside OmniDreams – the Cosmos-generated world. This photorealistic scene is entirely synthesized by NVIDIA Cosmos in real time. Left: Human driver steering in OmniDreams.
Autonomous vehicle (AV) research is entering a new phase. Reasoning-capable vision–language–action (VLA) models can “think through” complex situations, producing interpretable reasoning traces alongside planned trajectories. Yet, the core challenge that remains is how to test these policies in safety-critical, long-tail scenarios before they are deployed in the real world.
Meeting this challenge requires simulation that is both interactive and scalable. In closed-loop evaluation, the policy actively drives within the simulator: it produces an action, the environment updates accordingly, and the policy receives the next sensor observations rendered from the updated state. This is essential because the policy actions influence how a scenario unfolds over time.
Recent progress in reconstruction-based neural simulation has advanced AV development: by reconstructing real-world scenes from captured data, these systems enable photorealistic what-if testing in environments grounded in reality, letting developers modify agent behaviors or trajectories and evaluate how policies respond.
However, reconstruction-based workflows remain anchored to the originally observed data. They struggle to scale beyond the captured corridor, introduce new scene content, or stay photorealistic under substantially new conditions.
In contrast, generative world models trained on massive amounts of visual data learn rich priors about how the world behaves and visually evolves. These priors allow such models to synthesize very challenging phenomena such as highly dynamic weather conditions (e.g., rain, storm, snow, and wind) or deformable objects (such as a mattress on top of a car). They can also generate complex agent behaviors, including pedestrian behaviour and articulated motion that rapidly change in response to the vehicle’s proximity or stopping behavior.
Visualizing the premise of generative world models, from left to right: 1) generating a windy drive, 2) mattress on top of a car on the highway, 3) scene editing capabilities
Generative world models can also synthesize completely new camera views—for example, taking a right turn at an intersection where the recorded vehicle originally drove straight—and outcomes of novel driving actions without being constrained to a fixed reconstruction envelope. This enables systematic exploration of unobserved scenario variations and expands coverage of long-tail events.
Comparison of generative and reconstruction-based closed-loop simulation. Clockwise from the upper left: World Scenario, OmniDreams, Neural Reconstruction, and Policy
This blog introduces the latest research on generative closed-loop simulation for autonomous driving. At the core of this research is NVIDIA OmniDreams, an action-conditioned generative world model post-trained from the NVIDIA Cosmos world foundation model. OmniDreams generates photorealistic sensor observations while remaining interactive and responsive to the driving policy.
We’ll walk through the key design concepts behind the workflow, including:
- Achieving real-time rendering
- Conditioning sensor generation on simulator state and driving actions
- Operating in a closed loop using the recently open-sourced NVIDIA Alpamayo 1 (part of the NVIDIA Alpamayo open model family) as the policy model and NVIDIA AlpaSim as simulation orchestrator
What is generative closed-loop simulation?
Closed-loop autonomous driving systems involve the interaction of three core components: a driver, a simulation runtime, and a world model that produces sensor observations. In the closed-loop workflow presented in this blog post, NVIDIA Alpamayo 1 (or a human driver) consumes sensor observations and outputs driving actions. These actions are sent to the simulation runtime, NVIDIA AlpaSim, which tracks the ego vehicle’s state and packages the action together with the scenario context into the conditioning inputs required by the world model.
The world model, OmniDreams, then generates the next camera frames based on the updated state and returns them via a gRPC API. These synthesized observations are fed back to the driver for the next decision, forming a closed feedback loop.

Figure 1. Block diagram of the closed-loop simulation workflow. A policy model (here, Alpamayo 1) or user sends an action to the AlpaSim simulation runtime. AlpaSim updates the simulation state and forwards the context to OmniDreams, which synthesizes the next camera frames and returns them to the policy, completing the loop.
The same interface also supports human-in-the-loop operation, which is useful for interactive debugging, expert demonstration collection, and qualitative evaluation, where a human driver intentionally exercises challenging scenarios and observes how the system responds.
Video 2. Human driving in generative closed-loop simulation
How does OmniDreams work?
NVIDIA OmniDreams is an action-conditioned generative world model that produces camera observations in response to simulator state and driving actions. At each step, the model receives the ego trajectory, scenario context, and recent visual history as conditioning inputs. Using a transformer architecture derived from the NVIDIA Cosmos world foundation model, OmniDreams maintains temporal context via a KV cache and autoregressively generates subsequent sensor frames. These frames are returned to the simulation runtime and consumed by the driving policy, enabling interactive closed-loop simulation.
Inputs and outputs
OmniDreams takes three control inputs:
- World scenario: A structured representation of the next simulator state, described as lane lines and bounding boxes. This is a similar control representation used with Cosmos Transfer 2.5 multiview checkpoints.
- Text prompt: A description of the environment to help generate variations of the scenes, such as lighting, weather, and time of day changes.
- Memory cache: A history context used to preserve temporal consistency across consecutive frames in a closed loop.
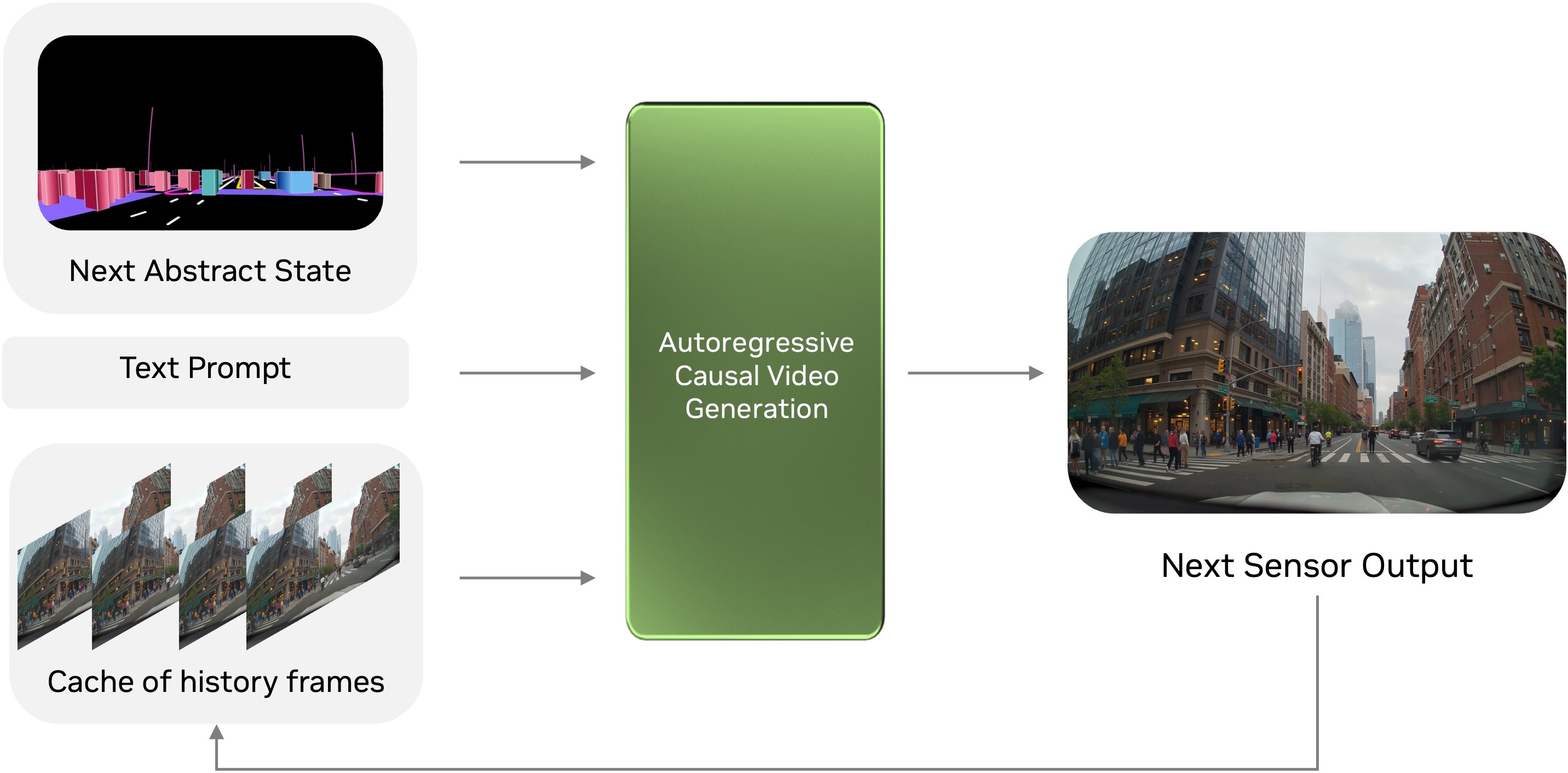
Figure 2. OmniDreams conditions on three inputs—a text prompt, the next abstract state from the simulator, and a history-frame cache—to generate next-step sensor frames that are returned to the policy in a closed loop
The output is a small set of next-step sensor frames (RGB in closed loop) returned to the runtime and policy via gRPC, rather than a long precomputed video clip.
Autoregressive, step-wise generation
Unlike offline video generation, a closed-loop world model must be interactive—able to change course the moment the policy (or human driver) changes its actions. So at each step OmniDreams generates only a small set of frames, updates the world-scenario input for the new estimated pose and orientation, and then generates the next frames.
To maintain coherent rollouts over time, OmniDreams performs video generation in an autoregressive manner and relies on its memory cache, ensuring that newly generated video frames remain consistent with the past throughout long rollouts.
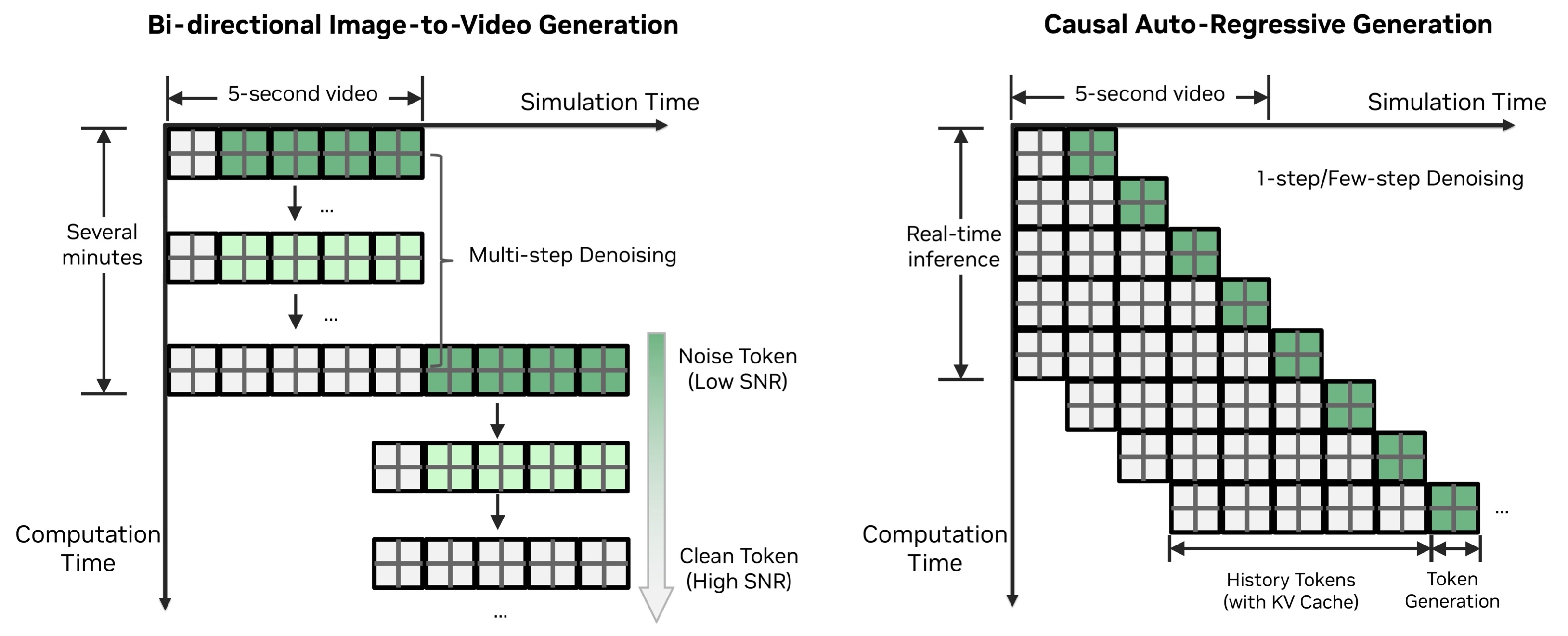
Figure 3. Autoregressive video generation diagram (right) comparing bidirectional image-to-video denoising (left) and causal KV-cache based generation for consistent long video rollouts.
Accurately modeling real-world behaviour and appearance
A generative closed-loop simulator is only useful when it accurately models real-world behaviour and appearance throughout the rollout. This section focuses on two practical requirements: preserving physically important scene details that affect policy behavior, and sustaining stable rollouts over extended horizons.
Faithfully simulating behaviour
Building on the Cosmos foundation model, OmniDreams generates physically realistic scene dynamics and traffic cues that directly affect AV decision-making. This includes the articulated motion of vulnerable road users (VRUs) and windshield wipers—phenomena that are challenging for neural reconstruction approaches.
It also preserves key semantics and control cues in the scene, including traffic lights, lane markings, traffic signs, and roadway structure that policies rely on. This is critical, as errors in these details can propagate into downstream driving behavior.
Video 3. High-quality generation of challenging pedestrian and cyclist scenarios
Maintaining quality in long rollouts
To support long rollouts, OmniDreams repeatedly reconditions generation on updated state and recent history, rather than attempting to generate a long video sequence in one shot. This is critical to allow real-time adjustments to ego trajectory while avoiding appearance drift. In the current research prototype, this design supports stable multi-minute rollouts without obvious visual collapse.
Video 4. OmniDreams generating long video sequence (4x speed)
Controllable scenario generation
Beyond fidelity, a generative simulator should enable developers to systematically vary what the policy sees. This section highlights two capabilities that broaden scenario coverage in practice: coherent multicamera generation and promptable counterfactual variation.
Multicamera view generation
OmniDreams can generate views of multiple mounted cameras simultaneously, producing coherent surround-view observations rather than independent per-camera renders. To improve 3D consistency across views, cross-view attention is applied between camera streams so that dynamic actors, lighting, and geometry remain aligned across perspectives. Depending on the desired configuration, users can adapt the model by post-training for the relevant camera count and type. While each camera increases inference compute, real-time performance is observable on up to four cameras on NVIDIA GB300 NVL72.
Video 5. Four-camera view generation with synchronized surround-view outputs across cameras
Long-tail coverage and counterfactual variations
OmniDreams can synthesize rare and safety-critical situations (such as extreme weather or unusual interactions) and generate controllable what-if variants. This enables developers to access more data, beyond recorded logs and reconstructed assets, with a single prompt. At scale, this also becomes a data engine that enables balanced training and evaluation sets with broad scenario coverage.
Video 6. Counterfactual variations: original scene (top), night scene (middle), snowy scene (bottom)
Real-time design and performance
An important goal of OmniDreams is real-time, interactive closed-loop simulation. To reach this goal, the pipeline was optimized end-to-end, from state rendering, to model inference, to runtime execution.
First, the world scenario renderer was optimized to render each frame in under 1ms. Within the model itself, a few-step denoising strategy is used to significantly reducing latency. Finally, inference-level optimizations, including CUDA Graphs and context parallelism across multiple GPUs, were applied to minimize overhead and improve throughput. With these optimizations, OmniDreams generates four camera views at 105 FPS each with 704×1280 resolution on 16 NVIDIA GB300 NVL72 GPUs.
How well does OmniDreams simulate?
A generative simulator is only useful if it is faithful in two senses: the frames must look real, and they must preserve the driving-relevant content a policy depends on—lane geometry, traffic participants, and signage. We measure both on 1,000 held-out clips from the RDS-HQ-1M evaluation split.
Generation quality and perception fidelity
We compare three stages of the single-view model: an offline bidirectional model, the causal Diffusion-Forcing model, and the final distilled real-time causal model (Self Forcing). Beyond FVD (raw realism) and the Temporal Sampson score (cross-frame consistency), we check how faithfully each model follows its conditioning by running off-the-shelf perception models—a BEVFormer 3D detector and a LATR lane detector—directly on the generated frames.
| Training stage | Generation quality | 3D vehicle detection (BEVFormer) | Lane line (LATR) | |||||
|---|---|---|---|---|---|---|---|---|
| FVD ↓ | Temp. Sampson ↓ | LET-AP ↑ | LET-APL ↑ | LET-APH ↑ | F1 ↑ | x-err. (far) ↓ | Cat. Acc. ↑ | |
| Bidirectional (offline) | 26.8 | 1.83 | 0.378 | 0.240 | 0.366 | 0.823 | 0.337 | 0.957 |
| Causal (Diffusion Forcing) | 31.7 | 1.87 | 0.221 | 0.136 | 0.214 | 0.775 | 0.418 | 0.941 |
| Distilled, real-time (Self Forcing) | 24.8 | 1.90 | 0.400 | 0.255 | 0.388 | 0.828 | 0.313 | 0.961 |
Table 1. Training-stage comparison for the single-view model (adapted from Table 4 of the technical report). Generation quality is measured on the synthesized frames; 3D-detection and lane metrics are produced by running off-the-shelf BEVFormer and LATR models on those frames. Best value in each column is highlighted.
The takeaway is that making the model real-time did not cost quality. The final distilled causal model achieves the best FVD and the strongest fidelity to conditioning signals across nearly every perception metric, matching or surpassing the offline bidirectional model while generating frame-by-frame in real time.
From world model to driving policy: the World-Action Model
If the OmniDreams backbone has learned a good internal model of how driving scenes evolve, those representations should be useful not just for rendering, but for driving. We test this by fine-tuning the single-view OmniDreams checkpoint (~2B parameters) into an end-to-end policy.
The causal transformer backbone is kept structurally identical to the generative model. We add two things per frame: image features from a DINOv2 encoder plus a front-telescope view as extra conditioning, and a “history” token that embeds the previous 1.6 s of ego motion. A lightweight U-Net–shaped MLP head then turns the backbone’s output into the trajectory via flow matching. At inference no video pixels need to be denoised: the heavy backbone runs only once and the few denoising steps are confined to the small trajectory head, so the policy stays cheap.
We show some early promising research results in this direction. In the same AlpaSim closed-loop stack and under the Alpamayo 1.5 evaluation protocol (20-second rollouts on a 574-scene subset of the Physical AI Autonomous Vehicles NuRec dataset), the OmniDreams WAM reduces the collision rate from 6.9% to 4.2% relative to Alpamayo 1.5, despite using roughly 5× fewer parameters (~2B vs. ~10B). By incident type, collisions drop across the board:
- Front: 1.0% → 0.9%
- Lateral: 0.6% → 0.4%
- Rear: 5.3% → 3.0%
Faithful closed-loop policy evaluation
The ultimate test of a simulator is whether it ranks policies the way the real world would. To check this, we swap only the sensor simulator between reconstruction-based NuRec versus OmniDreams while holding the orchestrator, traffic and physics, and the per-scene initial state fixed. We run 20-second closed-loop rollouts on a 501-scene subset of the Physical AI Autonomous Vehicles NuRec dataset, across four policy classes: the OmniDreams WAM and Alpamayo 1.5 with four, two, and one camera(s).
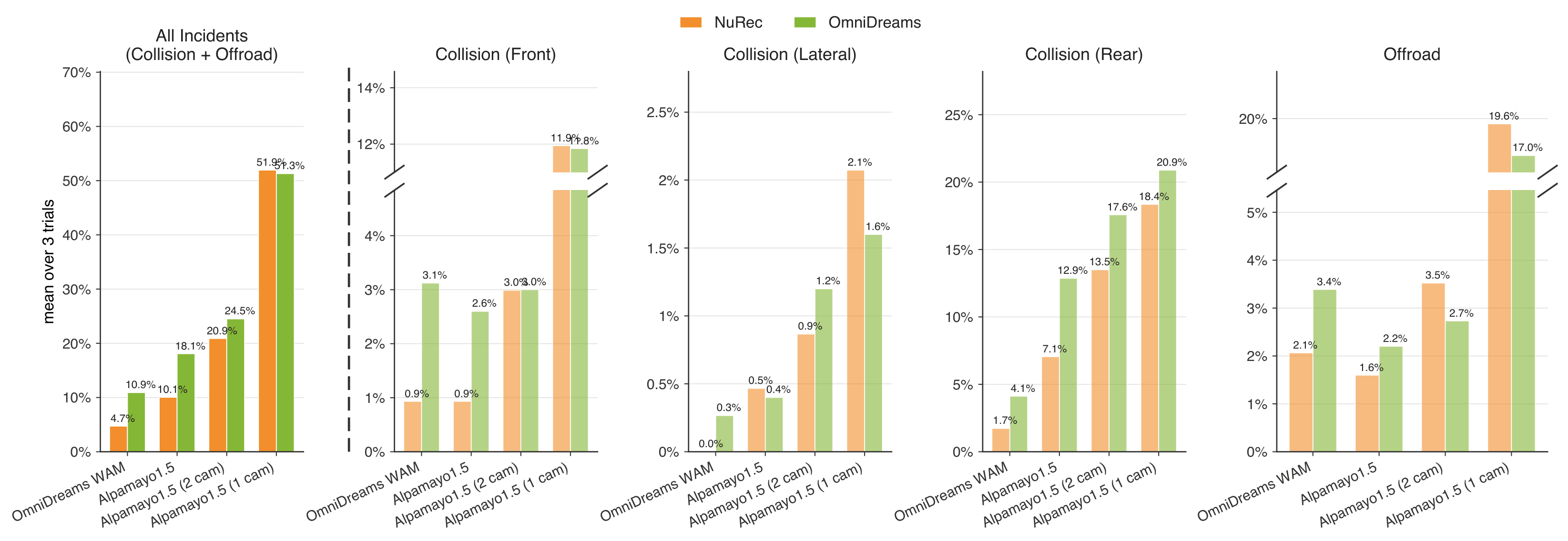
Figure 13. Closed-loop comparison between NuRec (orange) and OmniDreams (green) across policy classes, averaged over the 501-scene subset; lower is better. The headline All Incidents panel (left) preserves the policy ranking when switching from NuRec to OmniDreams; the remaining panels break this down by incident type.
Because NuRec is fit to each scene's original capture, it is a strong stand-in for the real recording near the logged trajectory. The key result is that OmniDreams preserves the same policy ranking NuRec produces—from the OmniDreams WAM as the strongest policy down to single-camera Alpamayo 1.5 as the weakest. A developer comparing policies inside OmniDreams would therefore reach the same conclusions as against NuRec, making it a faithful proxy for closed-loop policy evaluation—with the added benefit that it stays realistic even as a policy drives far from the recorded path, exactly where reconstruction-based renderers degrade.
Experience OmniDreams!
Please stop by the NVIDIA booth at CVPR 2026 to experience OmniDreams in action!
Also refer to the following resources:
- Explore physical AI and automotive sessions at NVIDIA GTC 2026.
- Check out Sanja Fidler’s NVIDIA GTC talk on Advancing Autonomous Vehicles with World Models.
- Visit Cosmos Cookbook for workflow walkthroughs, technical recipes, and concrete examples for building, adapting, and deploying Cosmos world foundation models.
- Explore new open Cosmos models and datasets on Hugging Face and GitHub or try models on build.nvidia.com.
- Read Building Autonomous Vehicles That Reason with NVIDIA Alpamayo for a step-by-step introduction to reasoning-based closed-loop simulation with open components.
- Explore Alpamayo and AlpaSim on GitHub and Hugging Face for open code, model weights, and runtime components used in this research project.
Contributors
The NVIDIA OmniDreams world model for closed-Loop simulation was made possible with contributions by: Aarti Basant, Amlan Kar, Despoina Paschalidou, Fangyin Wei, Francesco Ferroni, Guillermo Garcia Cobo, Haithem Turki, Huan Ling, Jaewoo Seo, James Lucas, Jay Zhangjie Wu, Jialiang Wang, Jonathan Lorraine, Jun Gao, Kai He, Katarina Tothova, Kevin Xie, Michal Tyszkiewicz, Qi Wu, Riccardo de Lutio, Ruilong Li, Sanja Fidler, Seung Wook Kim, Tianchang Shen, Tianshi Cao, Tobias Pfaff, William Lew, Xindi Wu, Xuanchi Ren, Yifan Lu, Yuxuan Zhang, Zan Gojcic, Zian Wang.
Acknowledgment
We would also like to additionally thank: Aditya Mahajan, Andras Bodis-Szomoru, Andy Ju, Arnav Khanna, Ashley Goldstein, Bartosz Stefanik, Boris Ivanovic, Bruno Costa Rendon, Cliff Woolley, Gangzheng Tong, Jeff Pei, Jesse Archer, Jonathan McCaffrey, Maciej Bala, Marco Pavone, Martin Ding Ma, Matt Cragun, Maximilian Igl, Michael Watson, Ming-Yu Liu, Nat Duca, Peter Karkus, Pyarelal Knowles, Ross Luo, Wonsik Han, Yan Wang, Yong He for their invaluable contributions in the integration of Alpamayo 1 in a closed-loop with OmniDreams, NVIDIA GTC demo, as well as open sourcing OmniDreams.