 Toronto AI Lab
Toronto AI Lab
We propose a method to create plausible geometric and texture style variations of 3D objects in the quest to democratize 3D content creation. Given a pair of textured source and target objects, our method predicts a part-aware affine transformation field that naturally warps the source shape to imitate the overall geometric style of the target. In addition, the texture style of the target is transferred to the warped source object with the help of a multi-view differentiable renderer. Our model, 3DStyleNet, is composed of two sub-networks trained in two stages. First, the geometric style network is trained on a large set of untextured 3D shapes. Second, we jointly optimize our geometric style network and a pre-trained image style transfer network with losses defined over both the geometry and the rendering of the result. Given a small set of high-quality textured objects, our method can create many novel stylized shapes, resulting in effortless 3D content creation and style-ware data augmentation. We showcase our approach qualitatively on 3D content stylization, and provide user studies to validate the quality of our results. In addition, our method can serve as a valuable tool to create 3D data augmentations for computer vision tasks. Extensive quantitative analysis shows that 3DStyleNet outperforms alternative data augmentation techniques for the downstream task of single-image 3D reconstruction.

Our method v.s. a strong baseline that combines NeuralCage + Linear Image Style Transfer. Notice that our method better captures the style in both geometry and texture. See for example the 5th column of the animal subset. While the baseline simply enlarges the dog's head, our method jointly stylizes both geometry and texture to achieve the cartoon look of the target object.
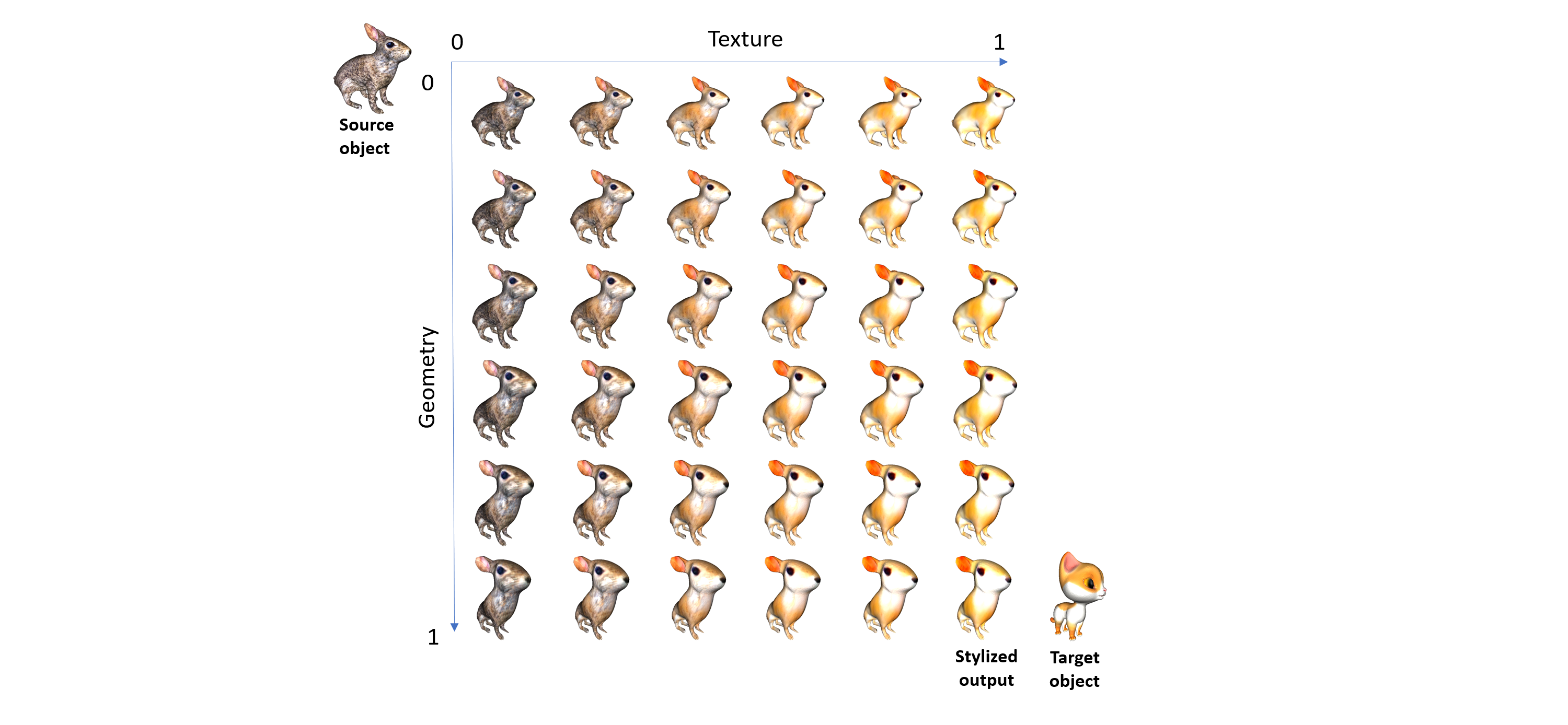
Our method supports linear shape interpolation between the source shape and the stylized output: for geometry, we linearly interpolate the vertex displacements produced by the part-ware affine transformation. For the texture, we linearly interpolate the vgg features and decode them to get the interpolated texture images. The interpolation is fast and can be done in real-time.

3DStyleNet can be used as a 3D Data Augmentation tool for downstream computer vision tasks. Here we show quantitative results on Single Image 3D reconstruction using DISN as the 3D reconstruction method and 3DStyleNet compared with baselines as a 3D data augmentation strategy.

Qualitative results on Single Image 3D reconstruction using DISN as the 3D reconstruction method and various 3D Data Augmentation strategies. While none of the results are perfect, some are clearly worse than others. Affine randomization hurts performance. No augmentation produces worst results than the remaining augmentation strategies. Ours produces the most plausible and smooth shapes.

Qualitative results on Single Image 3D reconstruction on SMAL Dataset using DISN as the 3D reconstruction method and 3DStyleNet as a 3D Data Augmentation Strategy . Note that the background is masked out with the provided segmentation in the Dataset.
@inproceedings{yin2021_3DStyleNet,
title = {3DStyleNet: Creating 3D Shapes with Geometric and Texture Style Variations},
author = {Kangxue Yin and Jun Gao and Maria Shugrina and Sameh Khamis and Sanja Fidler},
booktitle = {Proceedings of International Conference on Computer Vision (ICCV)},
year = {2021}
}

3DStyleNet: Creating 3D Shapes with Geometric and Texture Style Variations
Kangxue Yin, Jun Gao, Maria Shugrina, Sameh Khamis, Sanja Fidler
