
Align your Latents:
High-Resolution Video Synthesis with Latent Diffusion Models
High-Resolution Video Synthesis with Latent Diffusion Models
Latent Diffusion Models (LDMs) enable high-quality image synthesis while avoiding excessive compute demands by training a diffusion model in a compressed lower-dimensional latent space. Here, we apply the LDM paradigm to high-resolution video generation, a particularly resource-intensive task. We first pre-train an LDM on images only; then, we turn the image generator into a video generator by introducing a temporal dimension to the latent space diffusion model and fine-tuning on encoded image sequences, i.e., videos. Similarly, we temporally align diffusion model upsamplers, turning them into temporally consistent video super resolution models. We focus on two relevant real-world applications: Simulation of in-the-wild driving data and creative content creation with text-to-video modeling. In particular, we validate our Video LDM on real driving videos of resolution 512 x 1024, achieving state-of-the-art performance. Furthermore, our approach can easily leverage off-the-shelf pre-trained image LDMs, as we only need to train a temporal alignment model in that case. Doing so, we turn the publicly available, state-of-the-art text-to-image LDM Stable Diffusion into an efficient and expressive text-to-video model with resolution up to 1280 x 2048. We show that the temporal layers trained in this way generalize to different fine-tuned text-to-image LDMs. Utilizing this property, we show the first results for personalized text-to-video generation, opening exciting directions for future content creation.
Animation of temporal video fine-tuning in our Video Latent Diffusion Models (Video LDMs). We turn pre-trained image diffusion models into temporally consistent video generators.
Initially, different samples of a batch synthesized by the model are independent. After temporal video fine-tuning, the samples are temporally aligned and form coherent videos.
The stochastic generation processes before and after fine-tuning are visualised for a diffusion model of a one-dimensional toy distribution. For clarity, the figure corresponds to alignment in pixel space.
In practice, we perform alignment in LDM's latent space and obtain videos after applying LDM's decoder.
We present Video Latent Diffusion Models (Video LDMs) for computationally efficient high-resolution video generation. To alleviate the intensive compute and memory demands of high-resolution video synthesis, we leverage the LDM paradigm and extend it to video generation. Our Video LDMs map videos into a compressed latent space and model sequences of latent variables corresponding to the video frames (see animation above). We initialize the models from image LDMs and insert temporal layers into the LDMs' denoising neural networks to temporally model encoded video frame sequences. The temporal layers are based on temporal attention as well as 3D convolutions. We also fine-tune the model's decoder for video generation (see figure below).
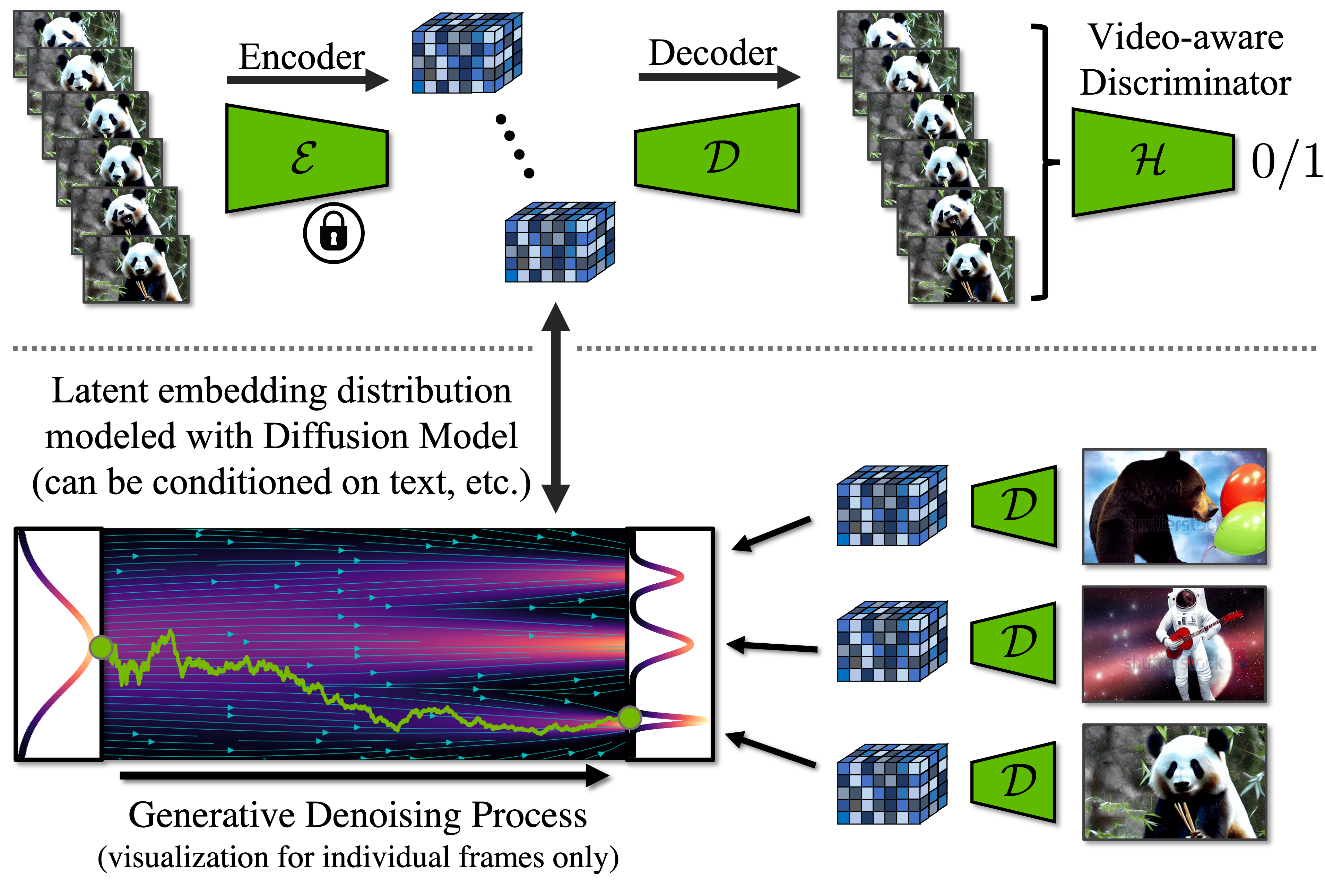
Latent diffusion model framework and video fine-tuning of decoder. Top: During temporal decoder fine-tuning, we process video sequences with a frozen per-frame encoder and enforce temporally coherent reconstructions across frames. We additionally employ a video-aware discriminator. Bottom: in LDMs, a diffusion model is trained in latent space. It synthesizes latent features, which are then transformed through the decoder into images. Note that in practice we model entire videos and video fine-tune the latent diffusion model to generate temporally consistent frame sequences.
Our Video LDM initially generates sparse keyframes at low frame rates, which are then temporally upsampled twice by another interpolation latent diffusion model. Moreover, optionally training Video LDMs for video prediction by conditioning on starting frames allows us to generate long videos in an autoregressive manner. To achieve high-resolution generation, we further leverage spatial diffusion model upsamplers and temporally align them for video upsampling. The entire generation stack is shown below.
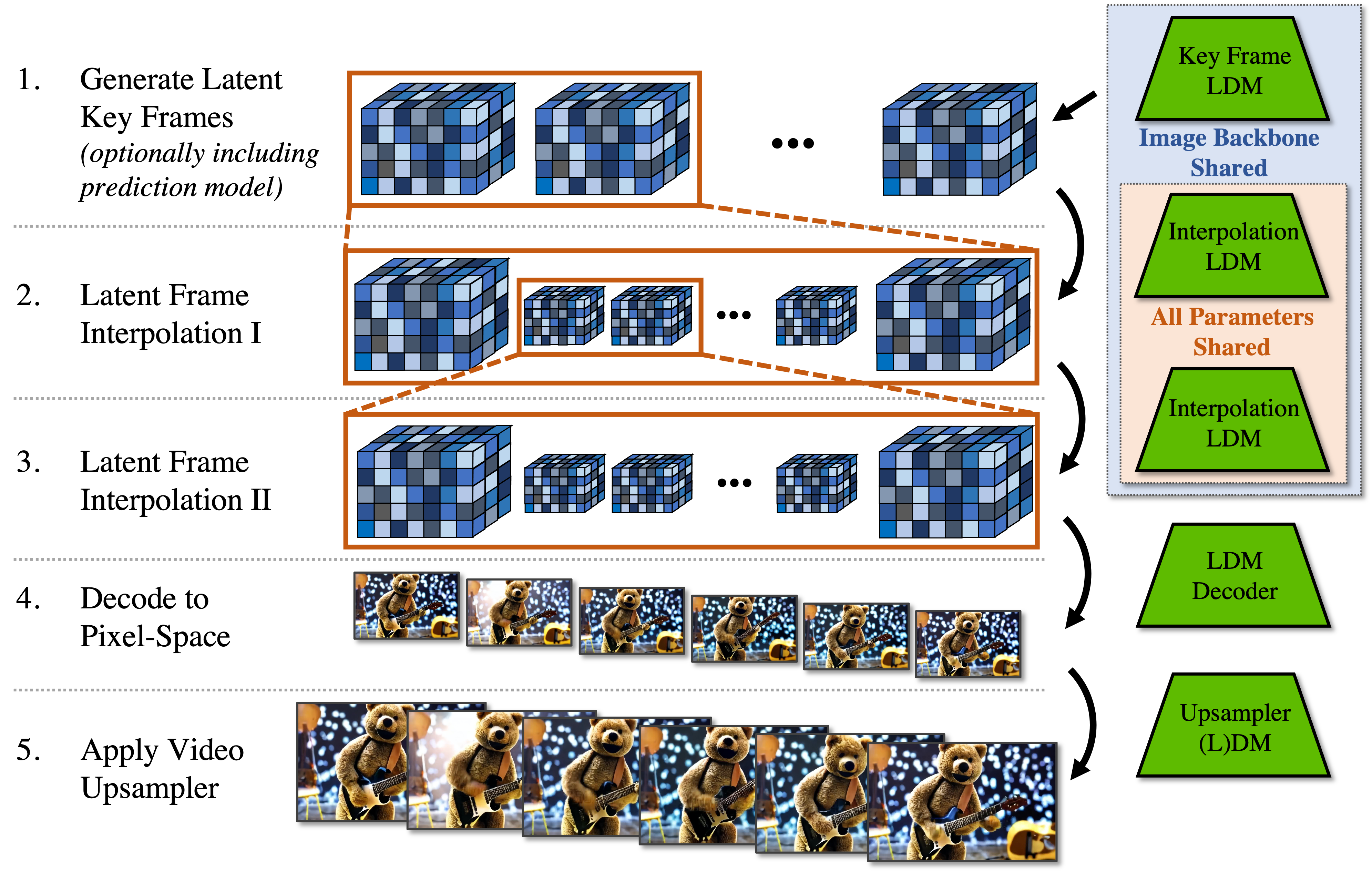
Video LDM Stack. We first generate sparse key frames. Then we temporally interpolate in two steps with the same interpolation model to achieve high frame rates. These operations use latent diffusion models (LDMs) that share the same image backbone. Finally, the latent video is decoded to pixel space and optionally a video upsampler diffusion model is applied.
Applications. We validate our approach on two relevant but distinct applications: Generation of in-the-wild driving scene videos and creative content creation with text-to-video modeling. For driving video synthesis, our Video LDM enables generation of temporally coherent, multiple minute long videos at resolution 512 x 1024, achieving state-of-the-art performance. For text-to-video, we demonstrate synthesis of short videos of several seconds lengths with resolution up to 1280 x 2048, leveraging Stable Diffusion as backbone image LDM as well as the Stable Diffusion upscaler. We also explore the convolutional-in-time application of our models as an alternative approach to extend the length of videos. Our main keyframe models only train the newly inserted temporal layers, but do not touch the layers of the backbone image LDM. Because of that the learnt temporal layers can be transferred to other image LDM backbones, for instance to ones that have been fine-tuned with DreamBooth. Leveraging this property, we additionally show initial results for personalized text-to-video generation.
Many generated videos can be found at the top of the page as well as here. The generated videos have a resolution of 1280 x 2048 pixels, consist of 113 frames and are rendered at 24 fps, resulting in 4.7 second long clips. Our Video LDM for text-to-video generation is based on Stable Diffusion and has a total of 4.1B parameters, including all components except the CLIP text encoder. Only 2.7B of these parameters are trained on videos. This means that our models are significantly smaller than those of several concurrent works. Nevertheless, we can produce high-resolution, temporally consistent and diverse videos. This can be attributed to the efficient LDM approach. Below is another text-to-video sample, one of our favorites.
Text prompt: "A teddy bear is playing the electric guitar, high definition, 4k."
Personalized Video Generation. We insert the temporal layers that were trained for our Video LDM for text-to-video synthesis into image LDM backbones that we previously fine-tuned on a set of images following DreamBooth. The temporal layers generalize to the DreamBooth checkpoints, thereby enabling personalized text-to-video generation.

Training images for DreamBooth.
Text prompt: "A sks cat playing in the grass."
Text prompt: "A sks cat getting up."

Training images for DreamBooth.
Text prompt: "A sks building next to the Eiffel Tower."
Text prompt: "Waves crashing against a sks building, ominous lighting."

Training images for DreamBooth.
Text prompt: "A sks frog playing a guitar in a band."
Text prompt: "A sks frog writing a scientific research paper."

Training images for DreamBooth.
Text prompt: "A sks tea pot floating in the ocean."
Text prompt: "A sks tea pot on top of a building in New York, drone flight, 4k."
Convolutional-in-Time Synthesis. We also explored synthesizing slightly longer videos "for free" by applying our learnt temporal layers convolutionally in time. The below videos consist of 175 frames rendered at 24 fps, resulting in 7.3 second long clips. A minor degradation in quality can be observed.
Text prompt: "Teddy bear walking down 5th Avenue, front view, beautiful sunset, close up, high definition, 4k."
Text prompt: "Waves crashing against a lone lighthouse, ominous lighting."
We also train a Video LDM on in-the-wild real driving scene videos and generate videos at 512 x 1024 resolution. Here, we are additionally training prediction models to enable long video generation, allowing us to generate temporally coherent videos that are several minutes long. Below we show four short synthesized videos. Furthermore, several 5 minute long generated videos can be found here.
Specific Driving Scenario Simulation. In practice, we may be interested in simulating a specific scene. To this end, we trained a bounding box-conditioned image-only LDM. Leveraging this model, we can place bounding boxes to construct a setting of interest, synthesize a corresponding starting frame, and then generate plausible videos starting from the designed scene. Below, the image on the left hand side is the initial frame that was generated based on the shown bounding boxes. On the right hand side, a video starting from that frame is generated.

Multimodal Driving Scenario Prediction. As another potentially relevant application, we can take the same starting frame and generate multiple plausible rollouts. In the two sets of videos below, synthesis starts from the same initial frame.
This is an NVIDIA research project, and the data sources used are for research purposes only and not intended for commercial application or use.

Align your Latents:
High-Resolution Video Synthesis with Latent Diffusion Models
Andreas Blattmann*, Robin Rombach*, Huan Ling*, Tim Dockhorn*, Seung Wook Kim, Sanja Fidler, Karsten Kreis
* Equal contribution.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023
@inproceedings{blattmann2023videoldm,
title={Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models},
author={Blattmann, Andreas and Rombach, Robin and Ling, Huan and Dockhorn, Tim and Kim, Seung Wook and Fidler, Sanja and Kreis, Karsten},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition ({CVPR})},
year={2023}
}