NVIDIA Research
Toronto AI Lab
NVIDIA Research
Toronto AI Lab
40-second fast-forward video.
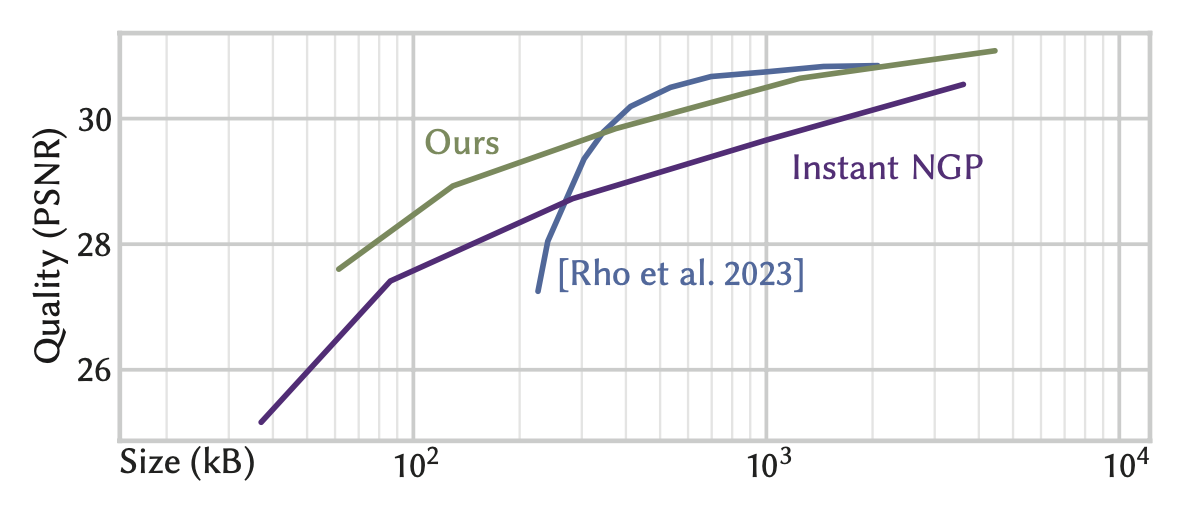
Neural graphics primitives are faster and achieve higher quality when their neural networks are augmented by spatial data structures that hold trainable features arranged in a grid. However, existing feature grids either come with a large memory footprint (dense or factorized grids, trees, and hash tables) or slow performance (index learning and vector quantization). In this paper, we show that a hash table with learned probes has neither disadvantage, resulting in a favorable combination of size and speed. Inference is faster than unprobed hash tables at equal quality while training is only 1.2-2.6x slower, significantly outperforming prior index learning approaches. We arrive at this formulation by casting all feature grids into a common framework: they each correspond to a lookup function that indexes into a table of feature vectors. In this framework, the lookup functions of existing data structures can be combined by simple arithmetic combinations of their indices, resulting in Pareto optimal compression and speed.
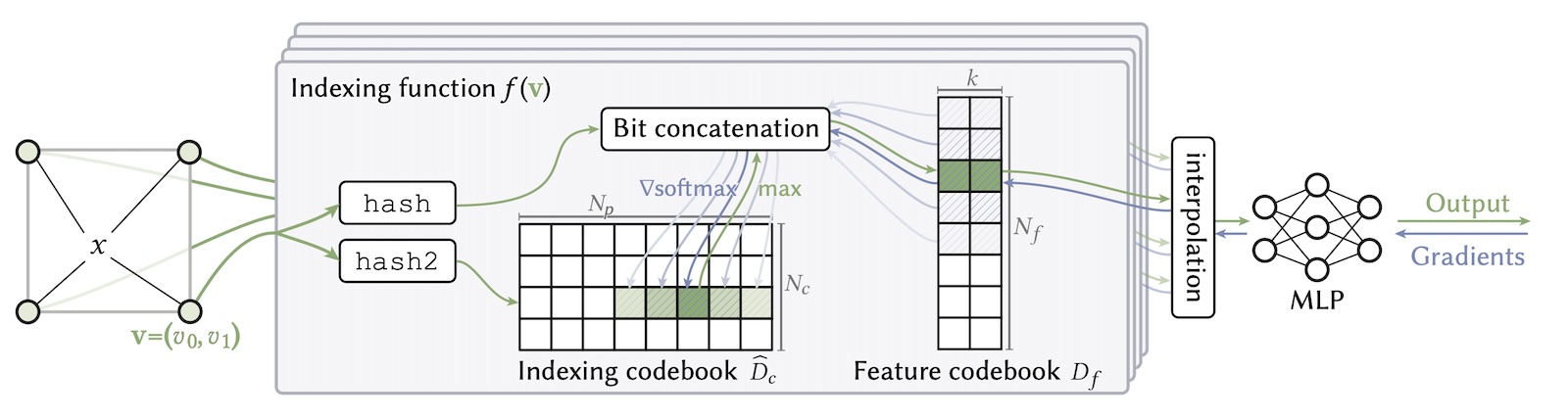
Overview of Compact NGP.

Compact Neural Graphics Primitves with Learned Hash Probing
Towaki Takikawa, Thomas Müller, Merlin Nimier-David, Alex Evans, Sanja Fidler, Alec Jacobson, Alexander Keller
Please send feedback and questions to Towaki Takikawa
@inproceedings{takikawa2023compact,
title = {Compact Neural Graphics Primitives with Learned Hash Probing},
author = {Takikawa, Towaki and
M\\"{u}ller, Thomas and
Nimier-David, Merlin and
Evans, Alex and
Fidler, Sanja and
Jacobson, Alec and
Keller, Alexander},
booktitle = {SIGGRAPH Asia 2023 Conference Papers},
year = {2023},
}
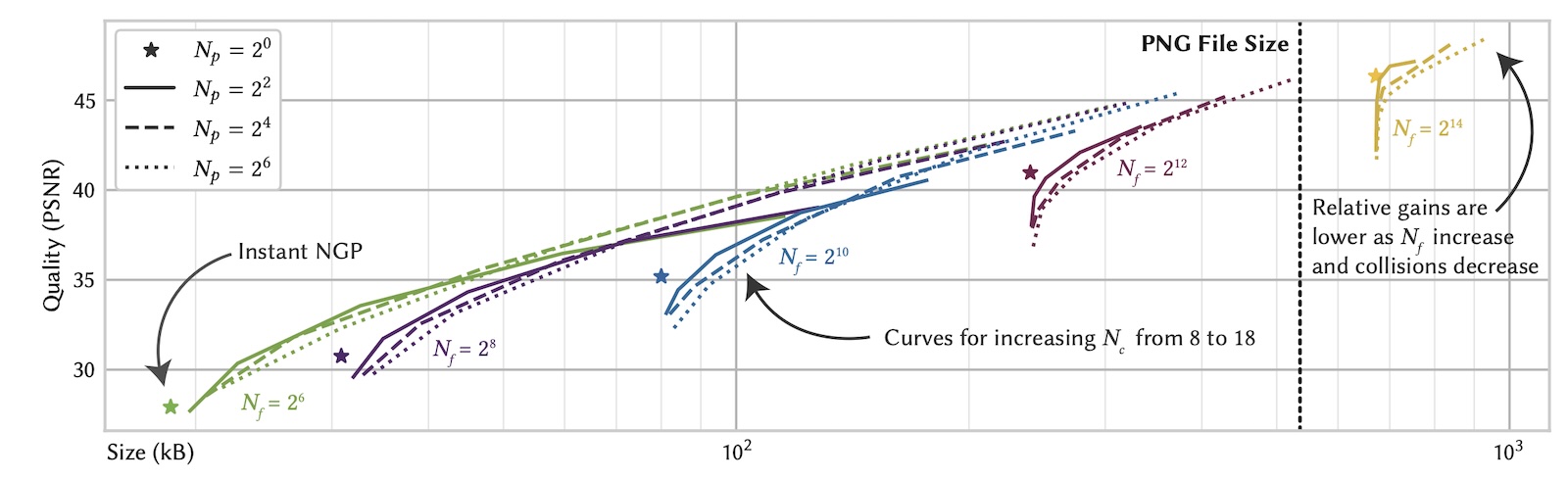
PSNR vs. file size for varying hyperparameters in compressing the Kodak image dataset. We sweep three parameters: the feature codebook size N_f, the index codebook size N_c (curves ranging from 2^12 to 2^20), and the probing range N_p (dashing and dotting). A value of N_p = 1 corresponds to Instant NGP (shown as *) and has no curve because it is invariant under N_c. We see that the optimal curve at a given file size N has a feature codebook size (same-colored *) of roughly N_f = 1/3 N and index codebook size N_c = 2/3 N. Small probing ranges (solid curves) are sufficient for good compression—in-fact optimal for small values of N_c (left side of curves)—but larger probing ranges (dashed and dotted curves) yield further small improvements for large values of N_c (right side of curves) at the cost of increased training time.
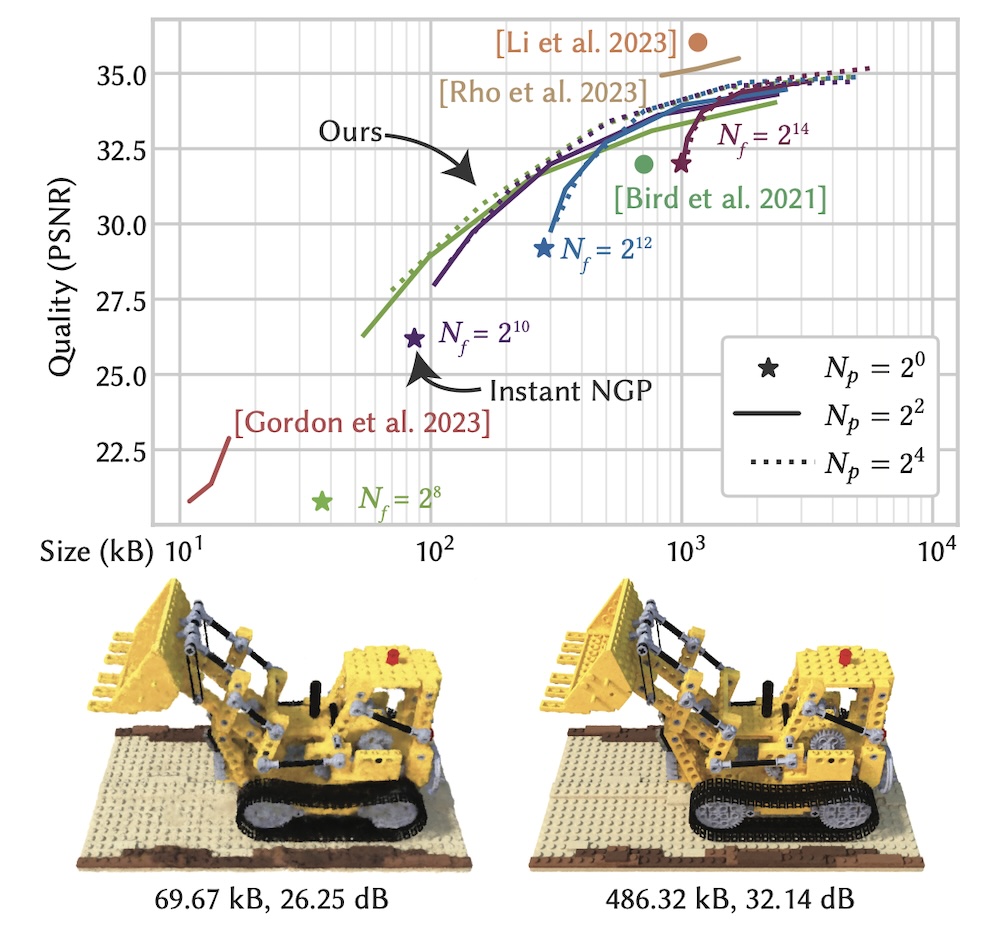
PSNR vs. file size for varying hyperparameters in compressing the NeRF Lego digger.
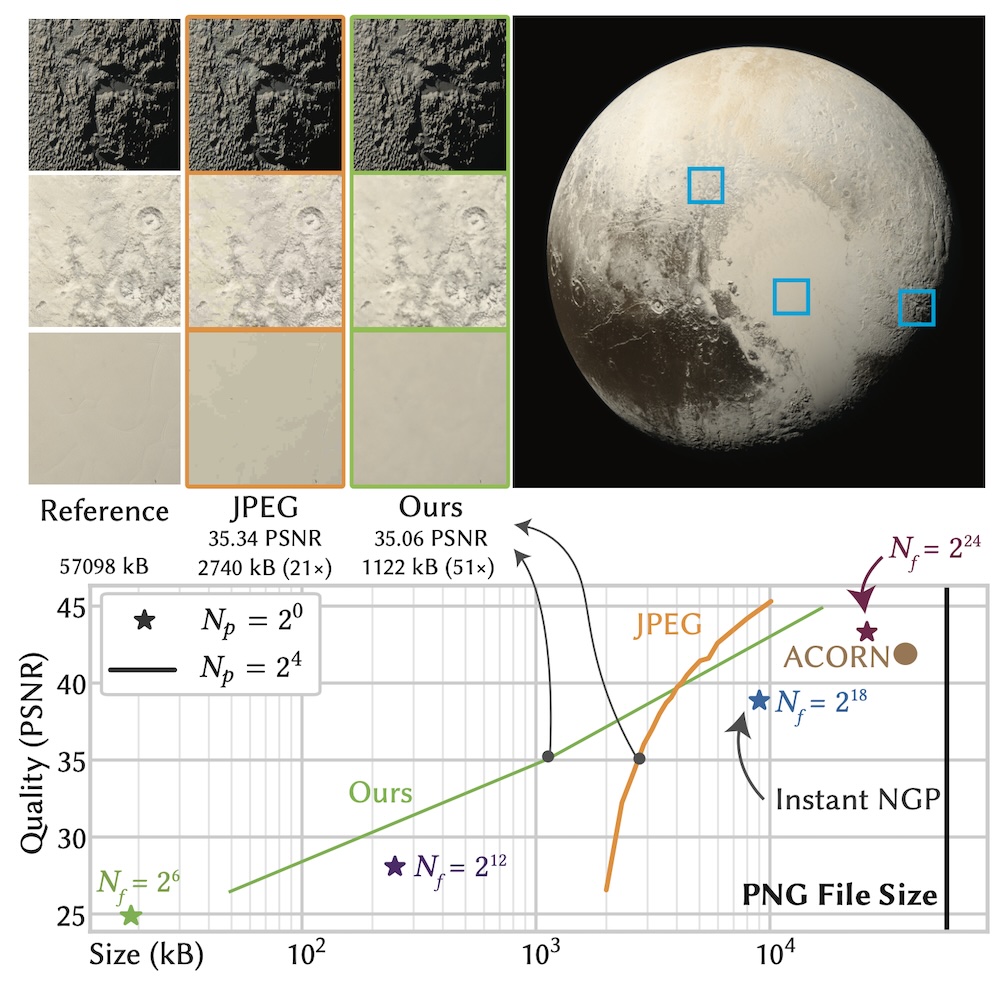
We fit Compact NGP to the 8000x8000px Pluto image. We show that we are able to outperform JPEG on a wide range of quality levels. The qualitative comparisons at equal size (insets) show the visual artifacts exhibited by different methods: while JPEG has color quantization arfitacts, ours appears slightly blurred.
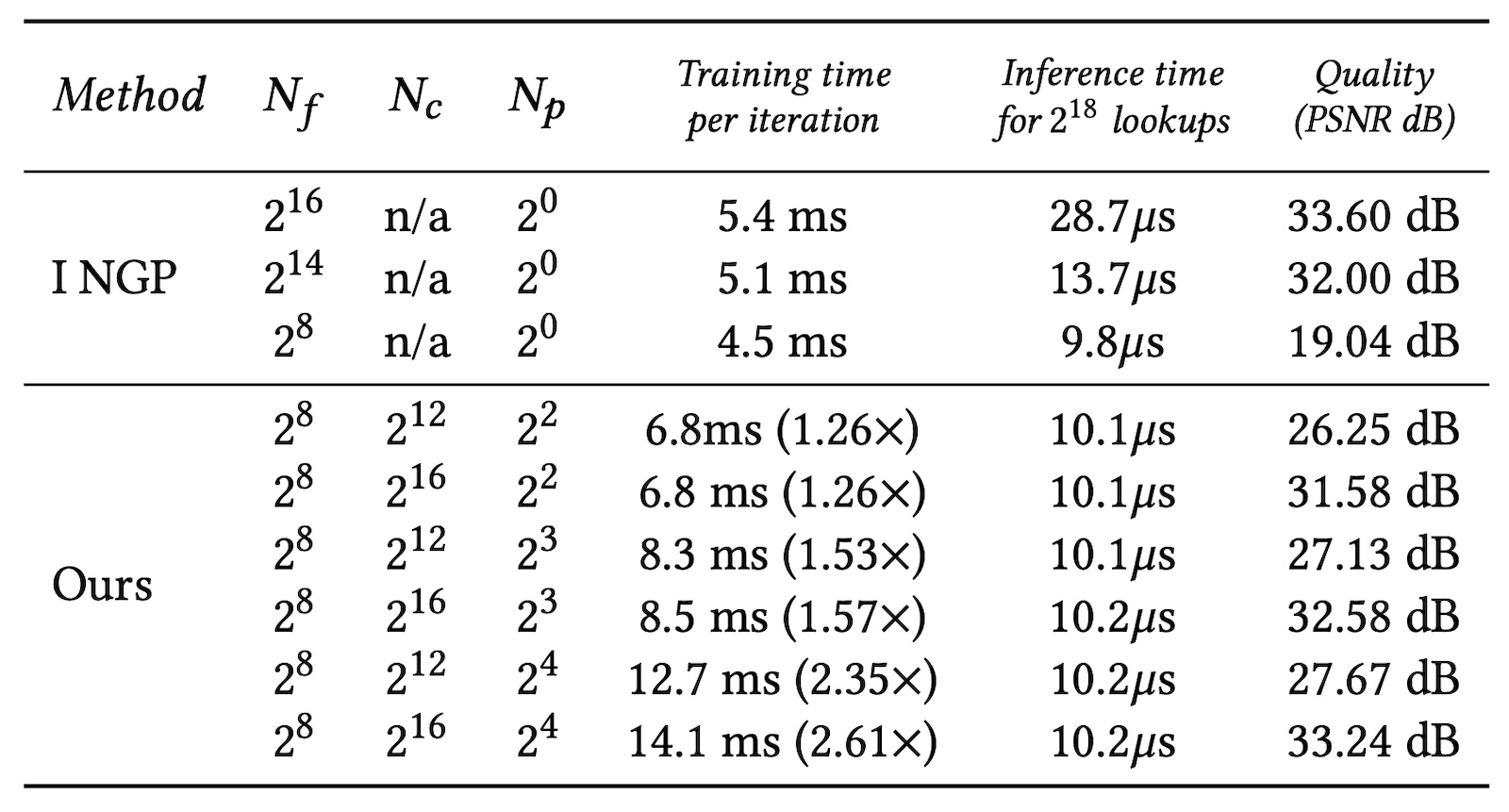
Training and inference time overheads of Compact NGP. The relative training overhead (denoted with nx) is measured with respect Instant NGP.
We would like to thank David Luebke, Karthik Vaidyanathan, and Marco Salvi for useful discussions throughout the project.
The Lego Bulldozer scene of Figure 6 was created by Blendswap user Heinzelnisse. The Pluto image of Figure 8 was created by NASA/Johns Hopkins University Applied Physics Laboratory/Southwest Research Institute/Alex Parker.