 Toronto AI Lab
Toronto AI Lab
In this work, we address the problem of jointly estimating albedo, normals, depth and 3D spatially-varying lighting from a single image. Most existing methods formulate the task as image-to-image translation, ignoring the 3D properties of the scene. However, indoor scenes contain complex 3D light transport where a 2D representation is insufficient. In this paper, we propose a unified, learning-based inverse rendering framework that formulates 3D spatially-varying lighting. Inspired by classic volume rendering techniques, we propose a novel Volumetric Spherical Gaussian representation for lighting, which parameterizes the exitant radiance of the 3D scene surfaces on a voxel grid. We design a physics-based differentiable renderer that utilizes our 3D lighting representation, and formulates the energy-conserving image formation process that enables joint training of all intrinsic properties with the re-rendering constraint. Our model ensures physically correct predictions and avoids the need for ground-truth HDR lighting which is not easily accessible. Experiments show that our method outperforms prior works both quantitatively and qualitatively, and is capable of producing photorealistic results for AR applications such as virtual object insertion even for highly specular objects.
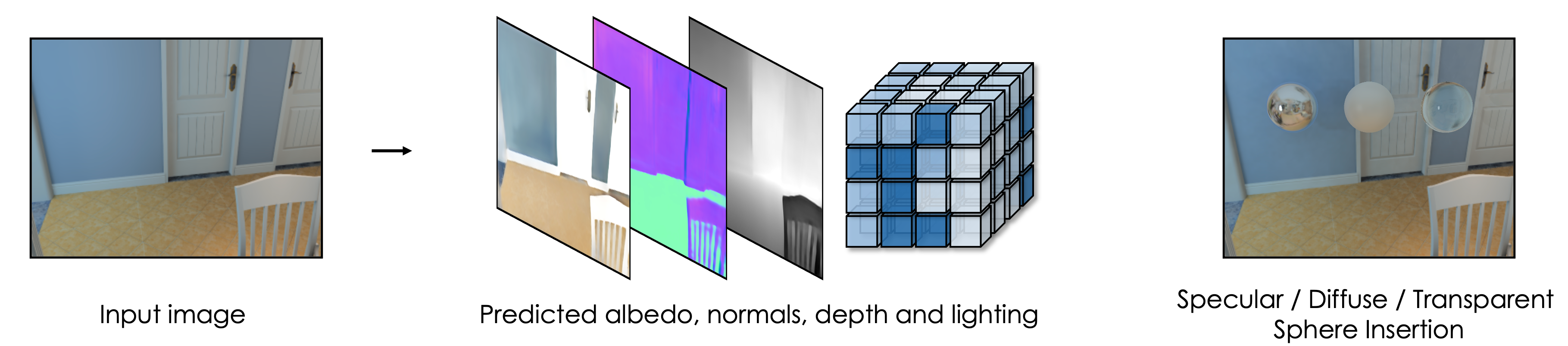
From a single image, our model jointly estimates albedo, normals, depth, and the HDR lighting volume. Our method predicts continuous HDR 3D spatially-varying lighting, which is critical in producing high quality object insertion with realistic cast shadows and high-frequency details.
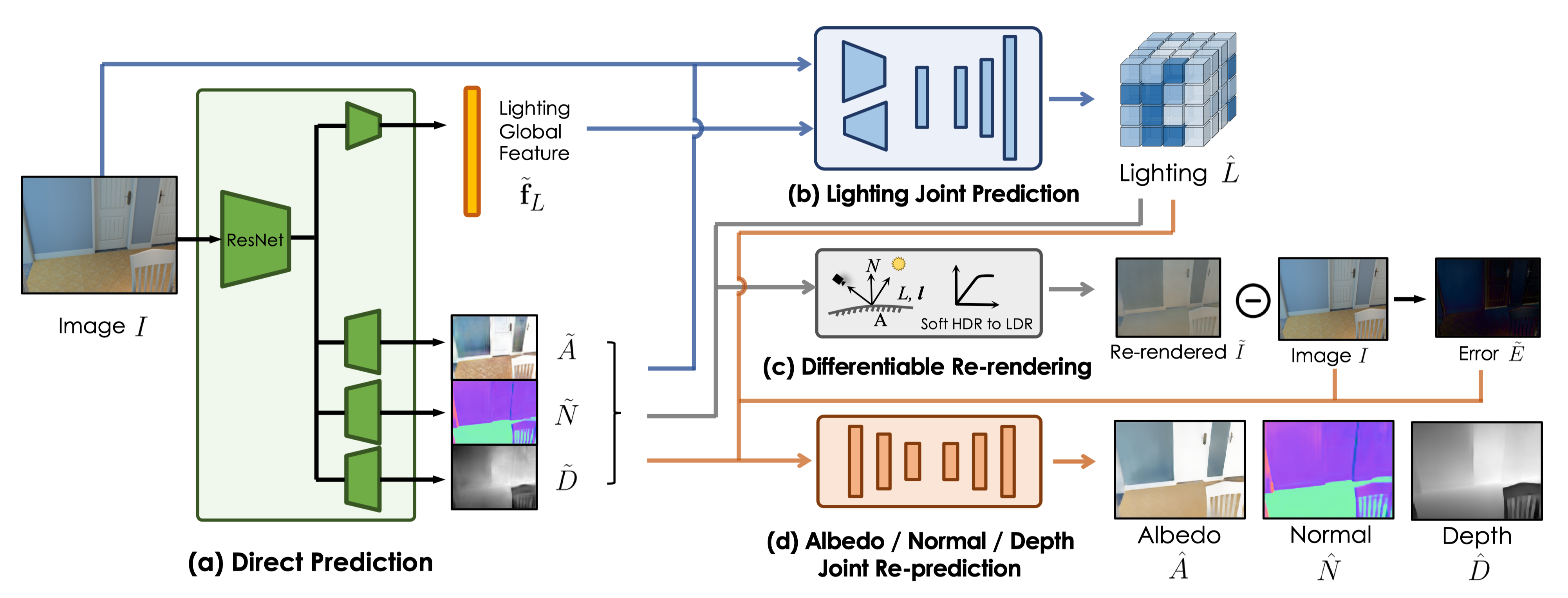
Specifically, our model consists of 4 submodules (a-d). Direct Prediction Module (a) takes a single image as input and jointly predicts initial guess of intrinsic properties. Lighting Joint Prediction Module (b) consumes the initial prediction and predicts a 3D lighting volume. Then, we employ a physics-based Differentiable Re-rendering Module (c) to re-render and enforce the consistency with the input image. Finally, Joint Re-prediction Module (d) jointly refines the initial prediction.
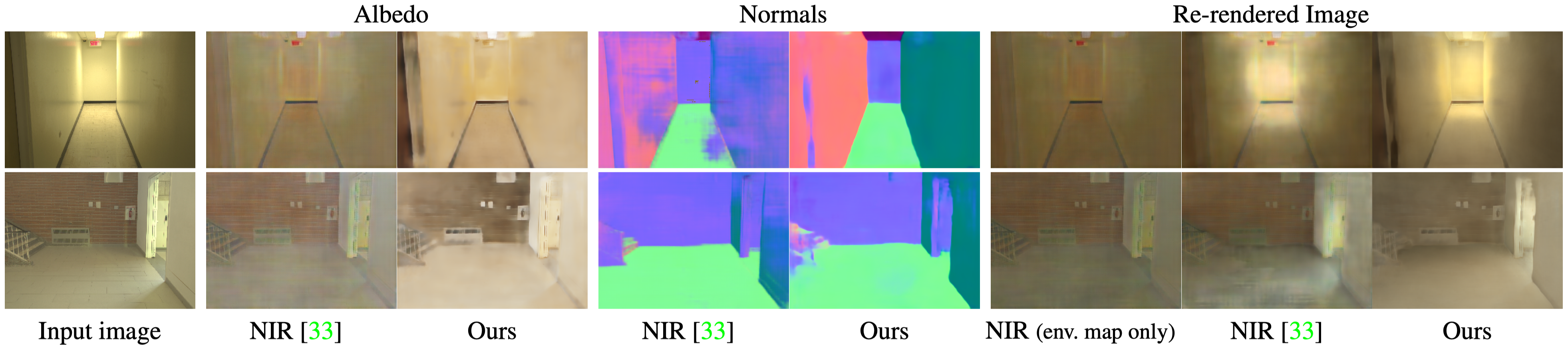
Results on predicted albedo, normals and re-rendered image. Our holistic inverse rendering framework estimates a 3D volumetic lighting representation, and use a physics-based differentiable renderer to re-render the input image. Despite tackling a more challenging task, our model can better disambiguate and reproduce complex lighting effects with less artifacts compared to prior state-of-the-art methods.

Results on lighting estimation and specular sphere insertion. We compare the insertion results of a highly specular sphere. Our method produces both angular high-frequency details and realistic cast shadows with HDR lighting, outperforming prior methods.

Results of virtual object insertion on real-world images. Our method generalizes well to real-world images and consistently produces realistic appearance and shadows.
@inproceedings{wang2021learning,
title = {Learning Indoor Inverse Rendering with 3D Spatially-Varying Lighting},
author = {Zian Wang and Jonah Philion and Sanja Fidler and Jan Kautz},
booktitle = {Proceedings of International Conference on Computer Vision (ICCV)},
year = {2021}
}

Learning Indoor Inverse Rendering with 3D Spatially-Varying Lighting
Zian Wang, Jonah Philion, Sanja Fidler, Jan Kautz