 Toronto AI Lab
NVIDIA Research
Berkeley AI Research
Toronto AI Lab
NVIDIA Research
Berkeley AI Research
TL;DR Our principled multi-GPU distributed training algorithm enables scaling up NeRFs to arbitrarily-large scale.
We present NeRF-XL,a principled method for distributing Neural Radiance Fields (NeRFs) across multiple GPUs, thus enabling training and rendering NeRFs of arbitrarily large capacity. We begin by revisiting existing multi-GPU approaches which decompose large scenes into multiple independently trained NeRFs and identify several fundamental issues with these methods that hinder improvements in reconstruction quality as additional computational resources (GPUs) are used in training. NeRF-XL remedies these issues and enables training and rendering NeRFs with an arbitrary number of parameters by simply using more hardware. At the core of our method lies a novel distributed training and rendering formulation which is mathematically equivalent to the classic single-GPU case and minimizes communication between GPUs. By unlocking NeRFs with arbitrarily-large parameter counts, our approach is the first to reveal multi-GPU scaling laws for NeRFs, showing reconstruction quality improvements with larger parameter counts and speed improvements with more GPUs. We show the effectiveness of NeRF-XL on a wide variety of datasets, including the largest open-source dataset to date, MatrixCity, containing 258K images covering a 25km^2 city area.
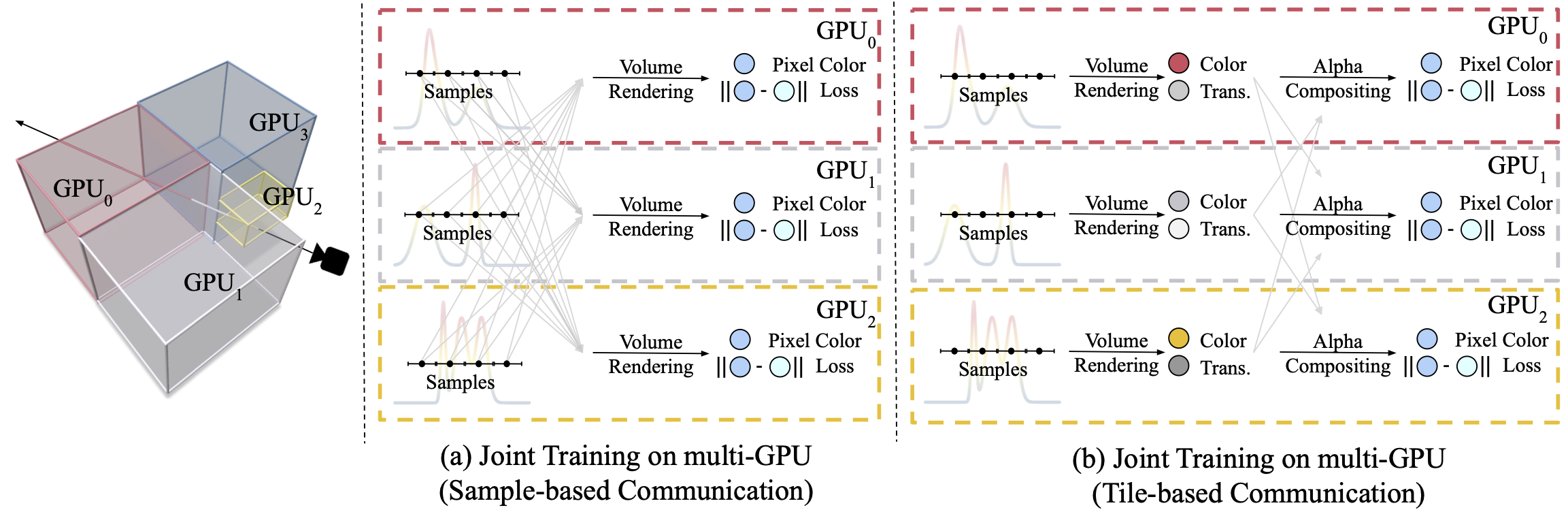
Our method jointly trains multiple NeRFs across all GPUs, each of which covers a non-overlapped spatial region. The communication across GPUs only happens in the forward pass but not the backward pass (shown in gray arrows), which significantly reducing the communication overhead. (a) We can train this system by evaluating each NeRF to get the sample color and density, then broadcast these values to all other GPUs for a global volume rendering. (b) By rewriting volume rendering equation (and other losses) into a distributed form we can dramatically reduce the data transfer to one value per-ray, thus improving efficiency. Mathematically, our approach is identical to training and rendering a NeRF represented by multiple small NeRFs (e.g. Kilo-NeRF) on a single large GPU.
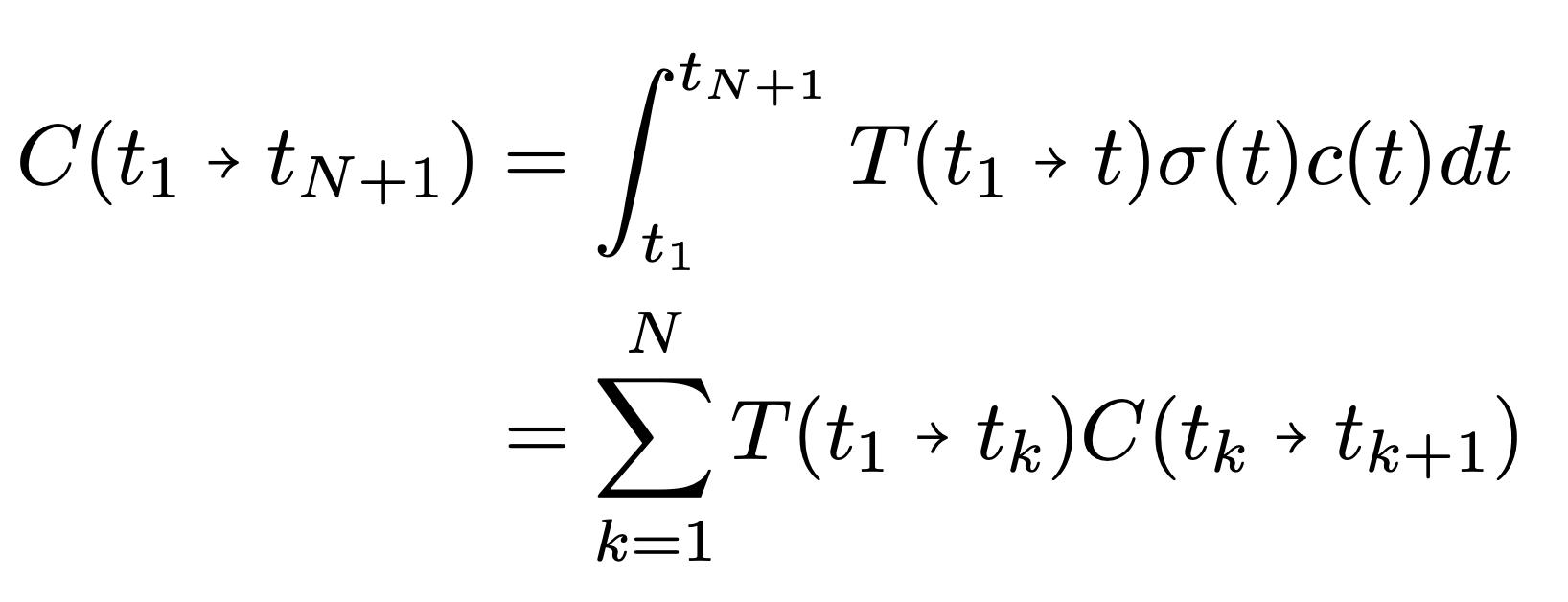
Distributed Volume Rendering
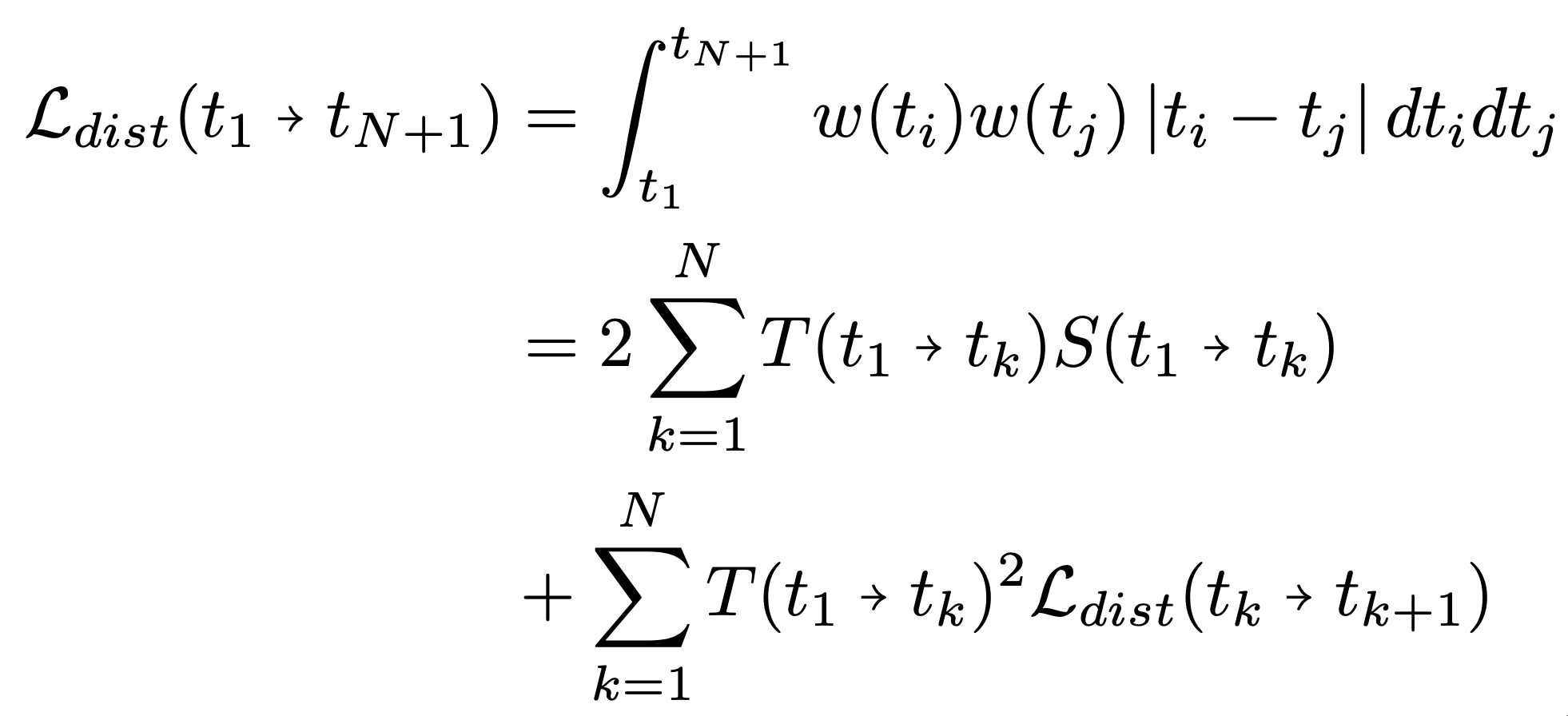
Distributed Distortion Loss

Zero Model Capacity Redundancy. Prior works (e.g., Block-NeRF, Mega-NeRF) typically involve training multiple NeRFs independently, with each NeRF being trained on a separate GPU. This setup necessitates each NeRF to handle both the focal region and its surroundings, resulting in redundant modeling within the capacity of the model. In contrast, our joint training methodology employs non-overlapping NeRFs, eliminating redundancy altogether.
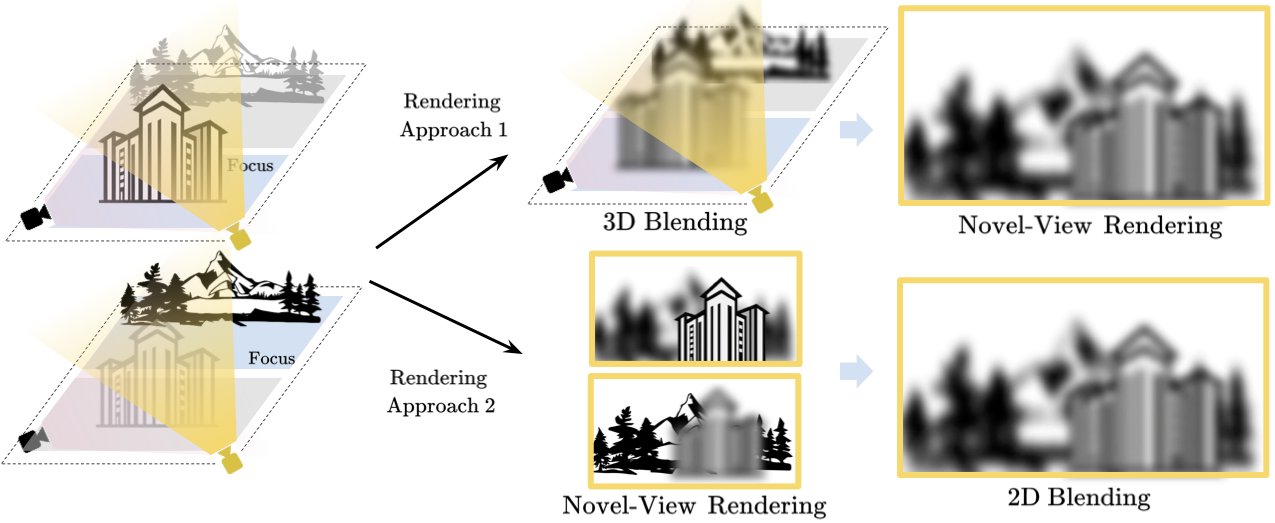
No Blending Any More. Prior works with independent Training relies on blending for novel-view synthesis at inference time. Either blending in 2D (e.g., Block-NeRF) or 3D (e.g., Mega-NeRF) could be harmful for the rendering quality. In contrast, our joint training approach does not rely on any blending for rendering. thereby eliminating the train-test discrepancy introduced by independent training in prior works.
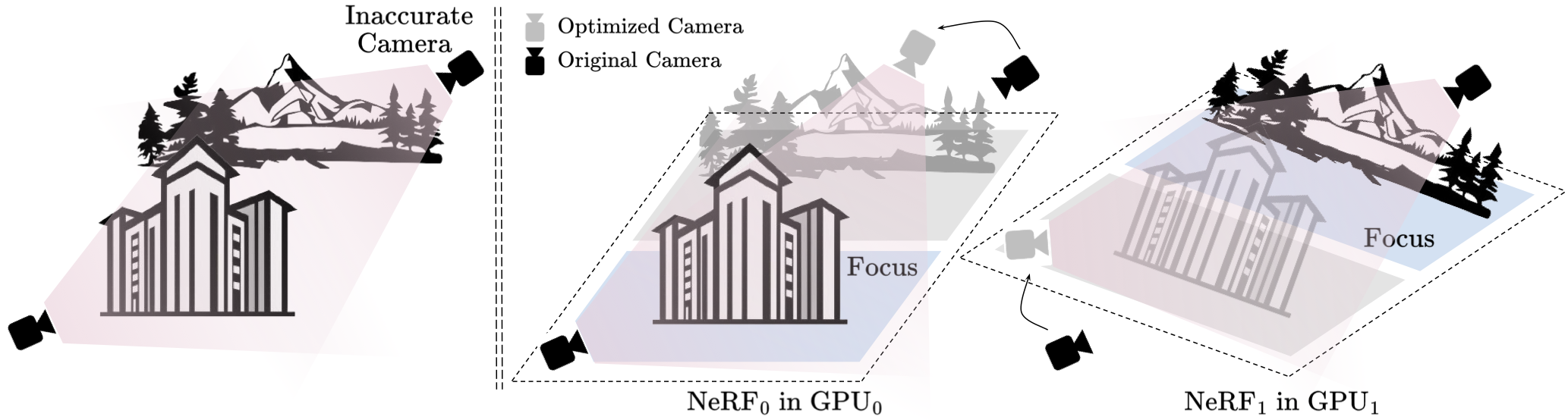
Shared Per-camera Embedding. Camera optimization in NeRF can be achieved by either transform the inaccurate camera itself or all other cameras along with the underlying 3D scene. Thus, training multiple NeRFs independently with camera optimization may lead to inconsistencies in camera corrections and scene geometry, causing more difficulties for blended rendering. Conversely, our joint training approach allows optimizing a single set of per-camera embedding (through multi-GPU synchronization) thus ensuring consistent camera optimization across the entire scene.
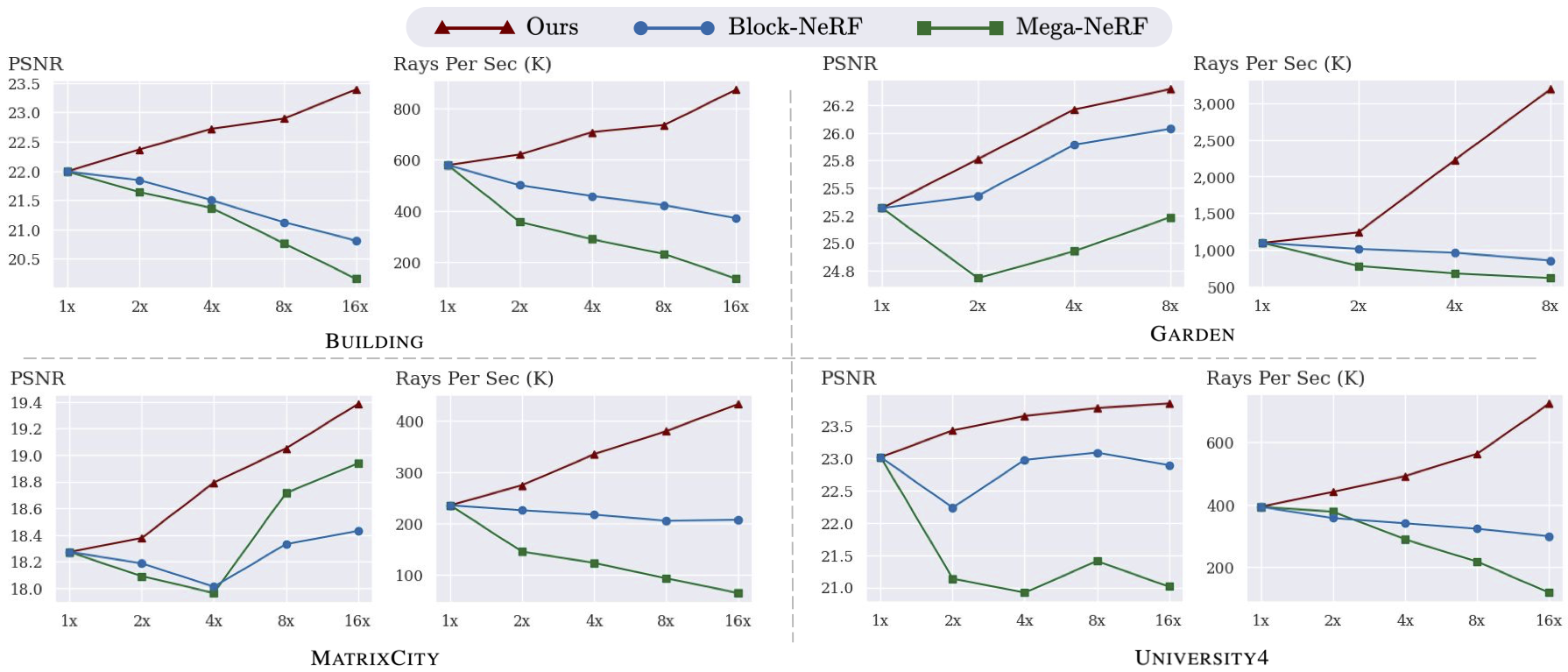
Prior works based on independent training fails to realize performance improvement with additional GPUs, which contradicts the fundamental objective of leveraging multi-GPU setups to enhance large-scale NeRF performance. Without any heuristics, our approach gracefully reveals scaling laws for NeRFs in the multi-GPU setting across various types of data and scales.

Laguna Seca Raceway (In-house Capture) on 8 GPUs.
Mexico Beach after Hurricane Michael 2018 (Source) on 32 GPUs.
MatrixCity (Source) on 64 GPUs.
@inproceedings{li2024nerfxl,
title={{NeRF-XL}: Scaling NeRFs with Multiple {GPUs}},
author={Ruilong Li and Sanja Fidler and Angjoo Kanazawa and Francis Williams},
year={2024},
booktitle={European Conference on Computer Vision (ECCV)},
}This project is supported in part by IARPA DOI/IBC 140D0423C0035. We would like to thank Brent Bartlett and Tim Woodard for providing and helping with processing the Mexico Beach data. We would also like to thank Yixuan Li for the help and discussion around the MatrixCity data.