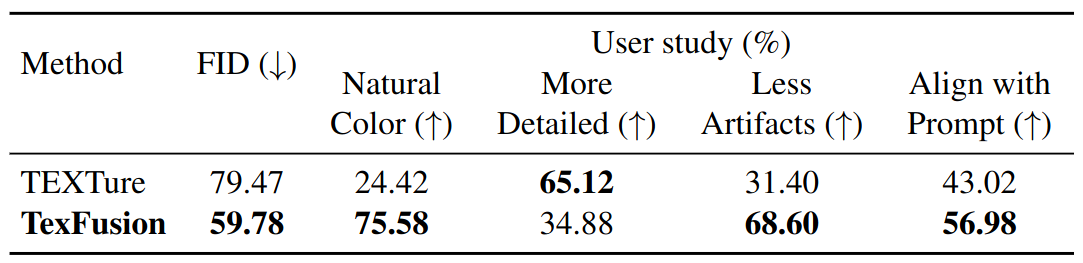
Method
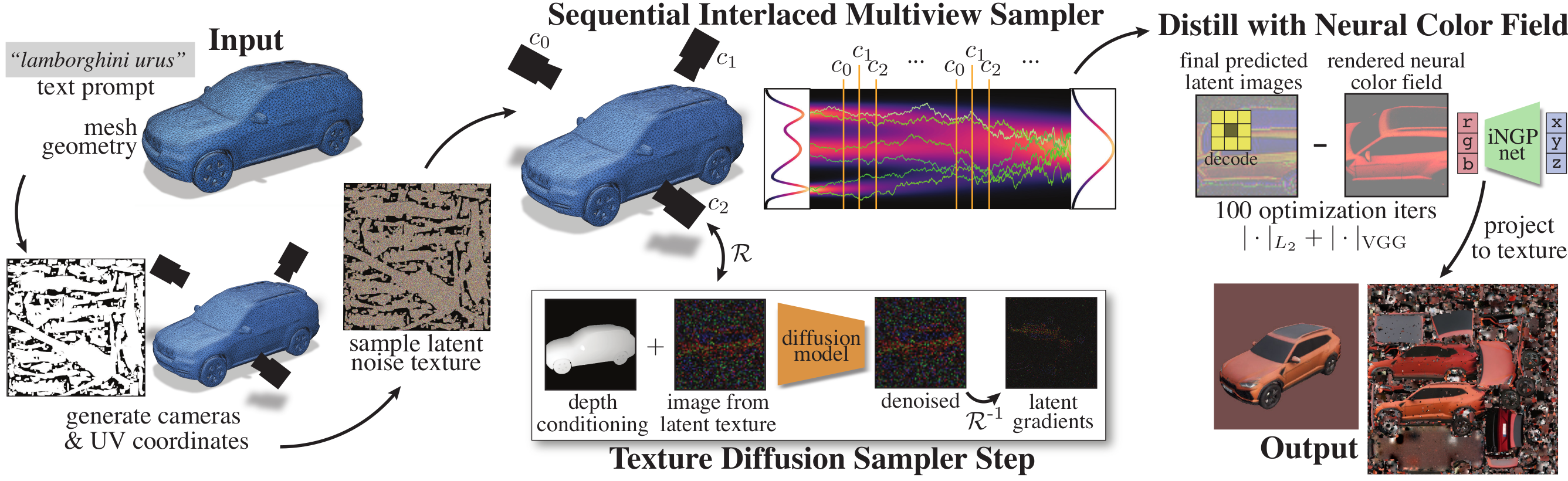
TexFusion takes a text prompt and mesh geometry as input and produces a UV parameterized texture image matching the prompt and mesh using Stable Diffusion as the text-to-image diffusion backbone.
Key to TexFusion is our Sequential Interlaced Multiview Sampler (SIMS) - SIMS performs denoising diffusion iterations in multiple camera views, yet the trajectories are aggregated through a latent texture map after every denoising step. The output of SIMS is a set of 3D consistent latent images.
The latent images are decoded by the Stable Diffusion decoder into RGB images, and fused into a texture map via optimizing an intermediate neural color field.