
NVIDIA Nemotron Nano 2 and the Nemotron Pretraining Dataset v1
Published:
Models Pre-Training Dataset Tech Report Nemotron-CC-Math Paper Try it!
Models
We are excited to release the NVIDIA Nemotron Nano 2 family of accurate and efficient hybrid Mamba-Transformer reasoning models. Try it here.
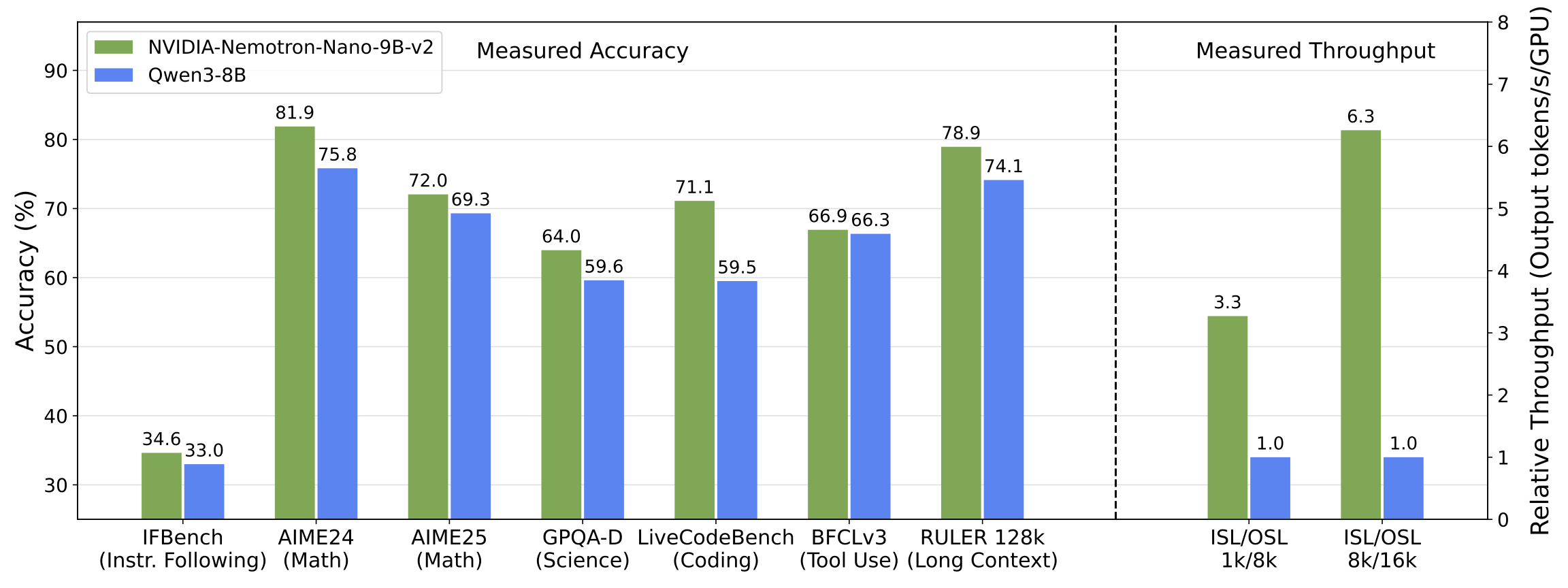
As shown in the tech report, the reasoning model NVIDIA-Nemotron-Nano-v2-9B achieves comparable or better accuracies on complex reasoning benchmarks than the leading comparably sized open model Qwen3-8B at up to 6x higher throughput. In the figure, we abbreviate input sequence length to ISL and output sequence length to OSL. Throughput was measured on a single NVIDIA A10G GPU in bfloat16 precision.
We are releasing the following three models on Hugging Face, all capable of 128K context length:
- NVIDIA-Nemotron-Nano-9B-v2: the aligned and pruned reasoning model,
- NVIDIA-Nemotron-Nano-9B-v2-Base: a pruned base model,
- NVIDIA-Nemotron-Nano-12B-v2-Base: the base model before alignment or pruning.
Datasets
What’s more, in a first for a leading open model like this, we are proud to release the majority of the data used for pre-training. The Nemotron-Pre-Training-Dataset-v1 collection comprises 6.6 trillion tokens of premium web crawl, math, code, SFT, and multilingual Q&A data, and is organized into four categories:
- Nemotron-CC-v2: Follow-up to Nemotron-CC (Su et al., 2025) with eight additional Common Crawl snapshots (2024–2025). The data has undergone global deduplication and synthetic rephrasing using Qwen3-30B-A3B. It also contains synthetic diverse QA pairs translated into 15 languages, supporting robust multilingual reasoning and general knowledge pretraining.
- Nemotron-CC-Math-v1: A 133B-token math-focused dataset derived from Common Crawl using NVIDIA’s Lynx + LLM pipeline, which preserves equations and code formatting while standardizing math content to LaTeX. This ensures critical math and code snippets remain intact, resulting in high quality pretraining data that outperforms prior math datasets on benchmark.
- Nemotron-Pretraining-Code-v1: A large-scale curated code dataset sourced from GitHub and filtered through multi-stage deduplication, license enforcement, and heuristic quality checks. It also includes LLM-generated code question–answer pairs in 11 programming languages.
- Nemotron-Pretraining-SFT-v1: A synthetically generated dataset covering STEM, academic, reasoning, and multilingual domains. This includes complex multiple-choice and analytical questions derived from high-quality math and science seeds, graduate-level academic texts, and instruction-tuned SFT data spanning math, code, general QA, and reasoning tasks.
- Nemotron-Pretraining-Dataset-sample: A small sampled version of the dataset provides 10 representative subsets, offering insight into high-quality QA data, math-focused extractions, code metadata, and SFT-style instruction data.
Technical Highlights
Selected highlights for the datasets include:
- Nemotron-CC-Math: Using a text browser (Lynx) to render web pages and then post-processing with an LLM (phi-4) leads to the first pipeline to be able to correctly preserve equations and code across the long tail of math formats encountered at web scale. This is a step-up change from past, heuristic-based methods. In internal pretraining experiments, models trained with Nemotron-CC-Math data saw +4.8 to +12.6 points on MATH over strongest baselines, and +4.6 to +14.3 points on MBPP+ for code generation.
- Nemotron-CC-v2: In the past, we found that synthetic diverse question & answer data generated from high quality English web crawl data is some of the most effective at enhancing an LLM’s general capabilities as tested by benchmarks such as MMLU. Here we extend this finding to more languages by translating this diverse QA data into 15 languages. In our ablation studies, including this translated diverse QA data boosted average Global-MMLU accuracy by +10.0 over using only multilingual Common Crawl data.
- Nemotron-Pretraining-Code: In addition to 175.1B tokens of high-quality synthetic code data, we release metadata to enable the reproduction of a carefully curated, permissively licensed code dataset of 747.4B tokens.
Selected highlights for the models include:
- Pre-training: Nemotron-Nano-12B-v2-Base was pre-trained using FP8 precision over 20 trillion tokens using a Warmup-Stable-Decay learning rate schedule. It then underwent a continuous pre-training long-context extension phase to become 128k-capable without degrading other benchmarks.
- Post-training: Nemotron Nano 2 was then post-trained through a combination of Supervised Fine-Tuning (SFT), Group Relative Policy Optimization (GRPO), Direct Preference Optimization (DPO), and Reinforcement Learning from Human Feedback (RLHF). About 5% of the data contained deliberately truncated reasoning traces, enabling fine-grained thinking budget control at inference time.
- Compression: Finally, both the base model and aligned model were compressed so as to enable inference over context lengths of 128k tokens on a single NVIDIA A10G GPU (22 GiB of memory, bfloat16 precision). This was done by extending a compression strategy based on Minitron to compress reasoning models subject to constraints.
For more details, please see the following technical report and paper.
- NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
- Nemotron-CC-Math: A 133 Billion-Token-Scale High Quality Math Pretraining Dataset
Data Examples
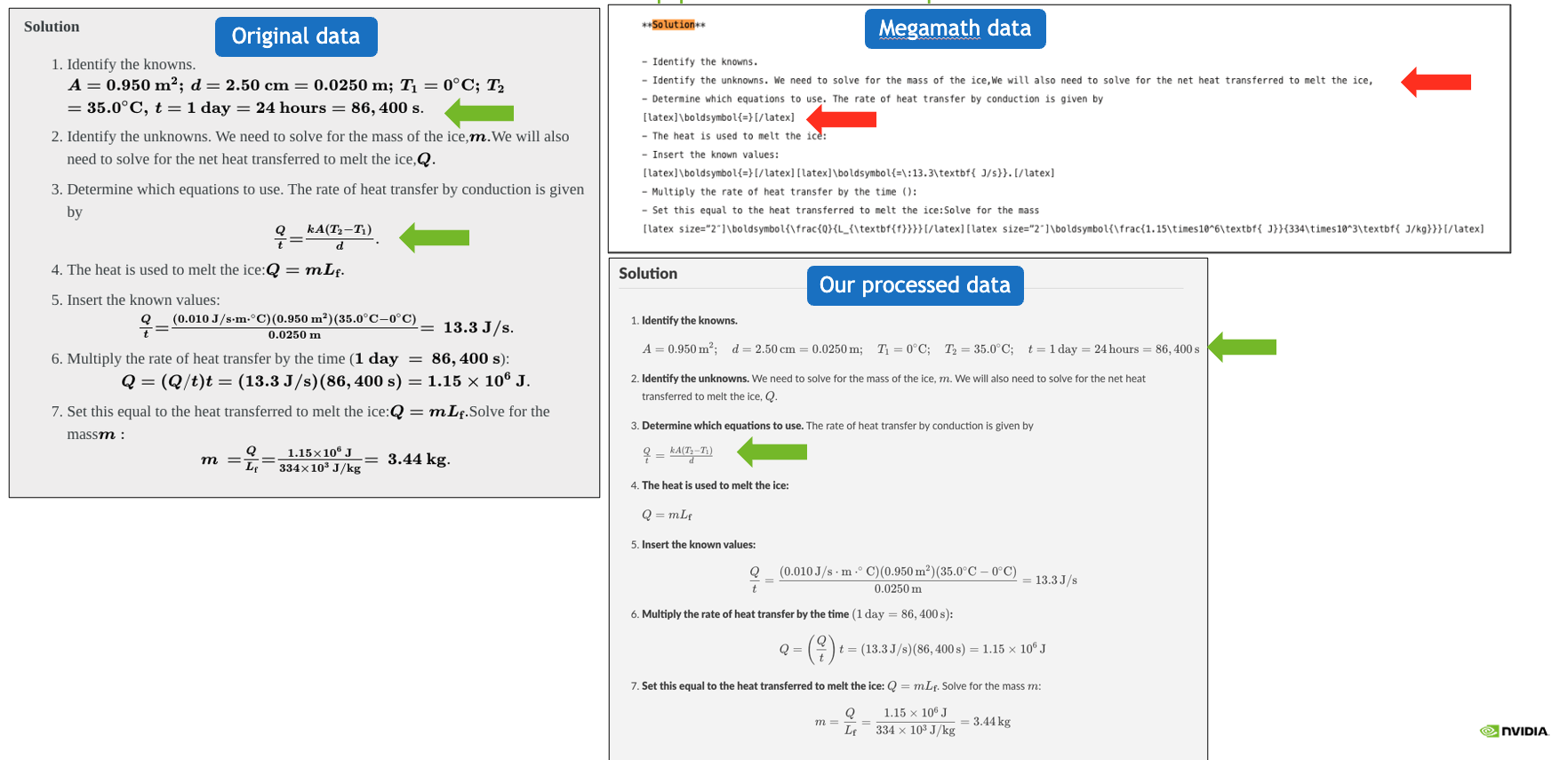
Example 1: Our pipeline preserves both math and code, unlike prior pretraining datasets that often lose or corrupt math equations.
Citation
@misc{nvidia2025nvidianemotronnano2,
title={NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model},
author={NVIDIA},
year={2025},
eprint={2508.14444},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2508.14444},
}