
Figure 1. Vesta interleaves acting, thinking, and tool use to solve a long-horizon task: it reads a letter's address, searches the web to determine the destination is international, and places the mail in the correct mailbox.
Abstract
Robots operating in open-world environments must seamlessly integrate localization, spatial reasoning, navigation, and long-horizon planning. While specialist models excel at individual tasks, deploying a multi-model stack is computationally expensive and prone to cascading errors.
We present Vesta, a unified embodied generalist that consolidates these capabilities into a single foundation model. Our approach combines a diverse and massive curated corpus designed to induce spatial grounding with a simple multimodal memory harness that enables reasoning over extended time horizons. Across diverse benchmarks, Vesta on average beats individual SOTA baselines by >20% and beats an ensemble of per-category-best baselines by >10% — demonstrating that a generalist model can match or exceed specialists. On real-world robotic tasks requiring memory and reasoning, Vesta improves task success by >35%. Our work demonstrates that a single generalist is a feasible, scalable, and arguably preferable alternative to combining specialists.
- +20% over the strongest single baseline (avg. across capabilities)
- +10% over an oracle ensemble of per-category best baselines
- +38.3% real-robot success on memory-heavy tasks vs. actor-only
- 4-in-1 localization, navigation, reasoning & planning unified
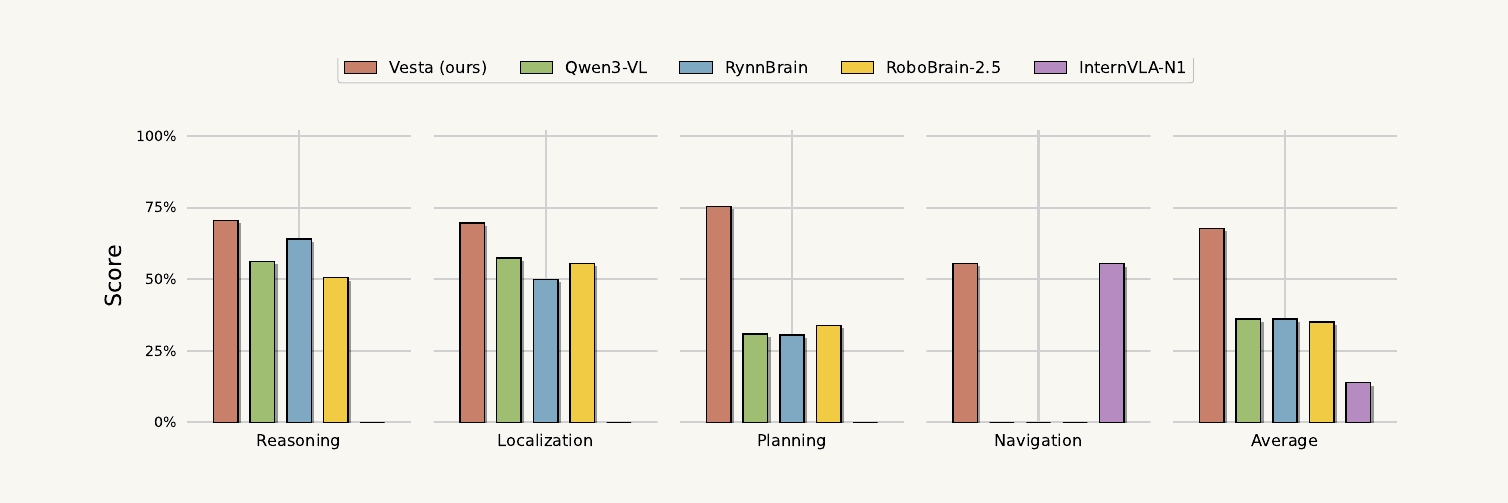
Figure 2. Vesta unifies localization, navigation, embodied reasoning, and action planning into a single generalist model. It scores over 20 points above the average prior baseline and >10 points above the strongest baseline in each individual category. On real robots, it improves success by 38.3% on memory-heavy tasks.
Overview
Modern embodied stacks decouple high-level reasoning from low-level execution: a planner Vision-Language Model (VLM) generates instructions that a specialized action model executes. The academic literature typically develops these planner capabilities in silos — navigation, memory, and reasoning specialists each tuned for their own benchmark. Such modularity introduces latency, complicates the inference stack, and is prone to cascading failures.
Vesta instead posits that these capabilities can — and should — be unified into a single generalist planner, built on three techniques: (1) a curated SFT corpus covering grounding, navigation, embodied reasoning, and real-robot data; (2) a simple multimodal memory harness interleaving history frames with a running textual cache of past subtasks; and (3) empirical validation on a real bimanual robot platform.
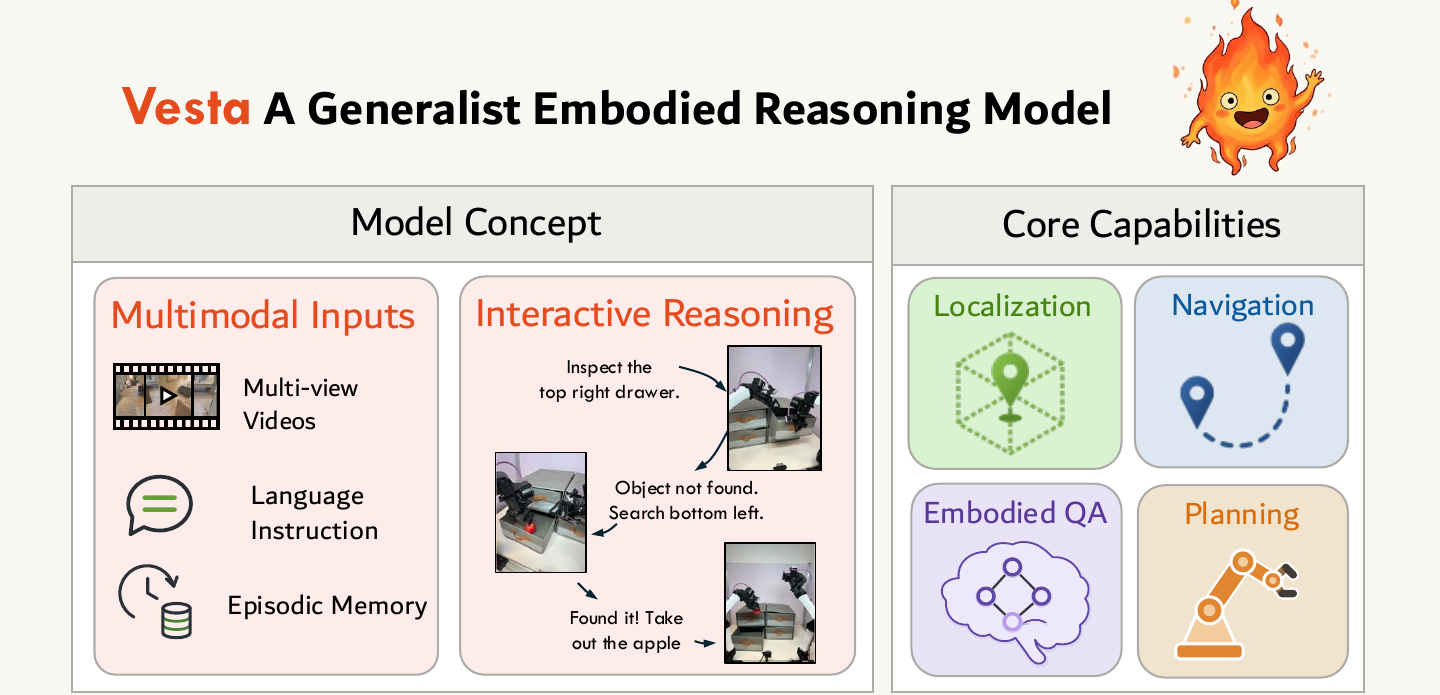
Figure 3. Vesta supports multimodal inputs — multi-view images/videos, language instructions, and episodic memory — alongside hierarchical control, unifying localization, navigation, embodied question-answering, and real-world planning in one model.
Method
Vesta is fine-tuned from the Qwen3-VL-8B base model. Its supervised fine-tuning (SFT) strategy builds base capabilities across four axes, with significant effort invested in data curation.
- 🎯 Localization — Grounding and pointing to predict contact/manipulation points. Built on large-scale detection data (Objects365, COCO, LVIS) plus an embodied tail with egocentric, manipulation-centric annotations. All boxes & points are decoded as text tokens.
- 🧭 Navigation — R2R-style Vision-and-Language Navigation. At each high-level step the planner emits a pixel goal, turn sequence, or stop; low-level motion is handled by a navigation backend. Trained on R2R, RxR, and ScaleVLN in simulation.
- 🧠 Embodied Reasoning — Extends spatial localization to action-conditioned scene understanding — affordance & placement prediction, trajectory generation, and task-progress estimation — for unified what, where, how, and when reasoning.
- 🤖 Action Planning + Memory — Predicts the next subtask in text from egocentric video. A 4-phase output (Observation → Progress → Reasoning → Action) is written to an explicit memory harness that re-injects a curated history of frames and past subtasks.
The SFT mix spans six categories and is intentionally biased toward spatially grounded capabilities — Spatial Intelligence (27.1%), Navigation (21.8%), and Grounding (20.8%) form the bulk, with General VLM (16.2%), Embodied Reasoning (9.8%), and Real Robots (4.3%) rounding it out. The model is trained for 1 epoch over the full mixture with a learning rate of 1e-5 and weight decay 0.01, on 128 H100 GPUs with a batch size of 256.
Demo
Manipulation. We show Vesta's agentic planning capability by combining it with a GR00T N1.6 policy model, and conduct experiments on the YAM robot arms. We first show how the model puts a specific number of fruits into the picnic bowl and then closes it. GR00T N1.6 alone cannot complete this task as it does not have any memory. Secondly we show how the model packs candy into a box, closes the box, and then places it into the matching tray. At last we demonstrate how the model can make agentic tool calls to determine if a letter should be sorted as domestic or international.
Manipulation Demo Videos
Navigation. We further show a few snippets from navigation trajectories collected inside a humanoid G1 simulator. The Vesta model navigates by providing 2D way points which the low-level SONIC-based controller translates into robot movements.
Navigation Demo Videos
Results
Across embodied cognition, localization, action planning, and navigation, a single Vesta checkpoint matches or beats SOTA specialists of the same size. Vesta's column is highlighted; bold marks the best result in each row.
| Cognition | Vesta | RynnBrain | RoboBrain 2.5 | Qwen3-VL |
|---|---|---|---|---|
| Open-X VQA | 89.3 | 74.0 | 52.9 | 59.8 |
| SAT | 81.3 | 70.0 | 67.3 | 65.3 |
| VSI-Bench | 64.5 | 71.0 | 42.9 | 60.3 |
| MMSI-Bench | 40.8 | 39.6 | 29.4 | 30.8 |
| ERQA | 44.9 | 46.8 | 44.0 | 44.8 |
| MindCube-Tiny | 80.9 | 56.6 | 29.2 | 36.0 |
| CV-Bench | 88.1 | 87.7 | 87.6 | 86.2 |
| PAI-U | 57.9 | 56.6 | 55.0 | 57.9 |
| EgoTaskQA | 81.9 | 72.5 | 85.0 | 57.8 |
| RoboSpatial | 57.8 | 73.1 | 73.0 | 58.2 |
| Average | 68.7 | 64.8 | 56.6 | 55.7 |
Table 1 — Embodied cognition (8B models). Vesta achieves the highest average, leading the majority of individual benchmarks.
| Localization | Vesta | RynnBrain | RoboBrain 2.5 | Qwen3-VL |
|---|---|---|---|---|
| CrossPoint | 76.0 | 44.3 | 75.4 | 28.7 |
| EmbSpatial | 81.9 | 79.3 | 75.8 | 78.5 |
| Where2Place | 68.3 | 66.9 | 66.0 | 64.7 |
| RefSpatial | 59.9 | 59.2 | 60.5 | 53.4 |
| PointBench | 63.2 | 59.7 | 69.1 | 61.4 |
| Average | 69.9 | 61.9 | 69.4 | 57.3 |
Table 2 — Localization (8B models). Vesta achieves the highest average across localization benchmarks.
| Model | CD | PF | SP | FS | RS | Diverse | Avg. |
|---|---|---|---|---|---|---|---|
| RoboBrain-2.5-8B | 35.3 | 81.6 | 15.9 | 38.3 | 33.0 | 27.0 | 38.5 |
| Qwen3-VL-8B | 36.7 | 67.8 | 18.1 | 22.1 | 30.2 | 26.7 | 33.6 |
| RynnBrain-8B | 38.7 | 69.5 | 16.0 | 18.4 | 32.4 | 26.0 | 33.5 |
| Vesta | 74.4 | 91.0 | 64.0 | 80.3 | 82.3 | 60.5 | 75.4 |
Table 3 — Real-world action planning. Zero-shot planning on AgiBot (CD = Clear Desk, PF = Place Fruit, SP = Sort Parts, FS = Fold Shirts, RS = Refill Shelf) and an internal Egocentric Human-Hand suite of diverse tasks. Vesta outperforms all baselines by a wide margin.
| Model | SR ↑ | NE ↓ | OS ↑ | SPL ↑ |
|---|---|---|---|---|
| RynnBrain-8B | 0.0 | 8.86 | 0.0 | 0.0 |
| RoboBrain-2.5-8B | 0.0 | 9.03 | 0.0 | 0.0 |
| Qwen3-VL-8B | 0.0 | 8.83 | 0.0 | 0.0 |
| UniNaVid | 47.0 | 5.58 | 53.3 | 42.7 |
| InternVLA-N1-8B (specialist) | 55.4 | 4.89 | 60.6 | 52.1 |
| Vesta | 55.5 | 5.16 | 61.4 | 50.8 |
Table 4 — Navigation in R2R-CE. On the R2R val-unseen split, Vesta ties the SOTA navigation specialist InternVLA-N1 (leading on SR and OS) while every generalist baseline fails out-of-domain. ↑ higher is better, ↓ lower is better.
Real-Robot Evaluation
Vesta is deployed as the planner on tabletop bimanual YAM grippers across three reasoning- and memory-heavy tasks — Find Object, Count Fruits, and Memorize Candy — using GR00T N1.6 as the low-level actor. Using Vesta as the planner improves average success by 38.3% over the actor-only baseline and 25% over a Qwen3-VL planner, with statistical significance over 4σ.

Figure 4. Real robot tasks on a bimanual platform: count fruits, locate object, and memorize candy. Each requires the planner to track progress and recall past observations across a long horizon.
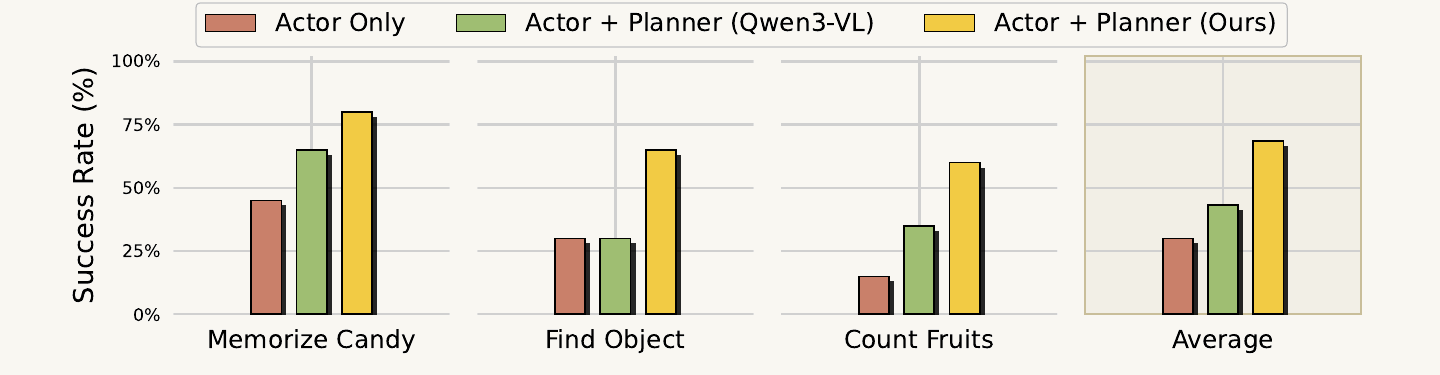
Figure 5. Across all tasks, Vesta-as-planner significantly beats the actor-only and Qwen3-VL planner baselines, lifting average success rate by 38.3% over actor-only.
Acknowledgements
We thank Cristaldo Campos, Curie Park, Yuhe Zhang, and the AutoModel team for their valuable support and contributions.
BibTeX
@techreport{bjorck2026vesta,
title = {Vesta: A Generalist Embodied Reasoning Model},
author = {Bjorck, Johan and Li, Zhiqi and Man, Yunze and Wang, Jing
and Cheng, An-Chieh and Liu, Sifei and Wang, Shihao and Yu, Zhiding
and Fan, Linxi and Zhu, Yuke and Kautz, Jan and others},
institution = {NVIDIA},
year = {2026},
type = {Technical Report}
}Johan Bjorck*, Zhiqi Li*, Yunze Man*1, Jing Wang*, An-Chieh Cheng†,2, Sifei Liu†, Shihao Wang†,1,3, Zhiding Yu†, Abhishek Badki, Stan Birchfield, Valts Blukis, Yevgen Chebotar, Siyi Chen4, Sicong Leng5, Yu-Cheng Chou6, Tianli Ding, Boyi Li, Zhengyi Luo, Hang Su, Jonathan Tremblay, Tingwu Wang, Bowen Wen, Jimmy Wu, Xianghui Xie7, Hanrong Ye, Hongxu Yin, K.R. Zentner, Liangyan Gui1, Yu-Xiong Wang1, Yuke Zhu‡, Linxi "Jim" Fan‡, Jan Kautz‡
* Co-first authors (alphabetical order) · † Core authors (alphabetical order) · ‡ Joint advising · Unmarked: NVIDIA
1 UIUC 2 UC San Diego 3 HK Polytechnic University 4 University of Michigan 5 Nanyang Technological University 6 Johns Hopkins University 7 University of Tübingen