EquiVDM: Equivariant Video Diffusion Models with Temporally Consistent Noise

Temporally consistent video-to-video generation is essential for applications of video diffusion models in areas such as sim-to-real, style-transfer, video upsampling, etc. In this paper, we propose a video diffusion framework that leverages temporally consistent noise to generate coherent video frames without specialized modules or additional constraints. We show that the standard training objective of diffusion models, when applied with temporally consistent noise, encourages the model to be equivariant to spatial transformations in input video and noise. This enables our model to better follow motion patterns from the input video, producing aligned motion and high-fidelity frames. Furthermore, we extend our approach to 3D-consistent video generation by attaching noise as textures on 3D meshes, ensuring 3D consistency in sim-to-real applications. Experimental results demonstrate that our method surpasses state-of-the-art baselines in motion alignment, 3D consistency, and video quality while requiring only a few sampling steps in practice.
Recent advancements in video diffusion model (VDM) have significantly improved the quality and photo-realisim of generated videos. To achieve temporal consistency in generated videos, 3D convolution or attentinon layers are introduced to better capture and propagate spatiotemporal information. While these designs can improve temporal consistency, they typically rely on extensive training on large-scale, high-quality video datasets to learn to generate realistic frames with natural, coherent motion patterns from random noise.
An alternative line of work aims to generate temporally consistent frames by directly sampling from temporally correlated noise. This is particularly appealing for video-to-video applications where an input video can be used to drive the coherent noise. However, standard diffusion networks are not intrinsically equivariant to noise warping transformations, due to their highly nonlinear layers. Thus sampling-time guidance or regularization strategies are needed to achieve approximate equivariance, which can introduce additional hyperparameters and complexity into the generation pipeline.
In this work, we introduce EquiVDM, a video-to-video diffusion model that is equivariant to the spatial warping transformation of the input noise. We show that the standard training objective of diffusion models, when applied with temporally consistent noise, encourages the model to be equivariant to spatial transformations in the input. Our approach introduces equivariance as an inherent property of the VDM itself during training, thus the temporal coherence comes at no extra cost in terms of model complexity or runtime overhead.

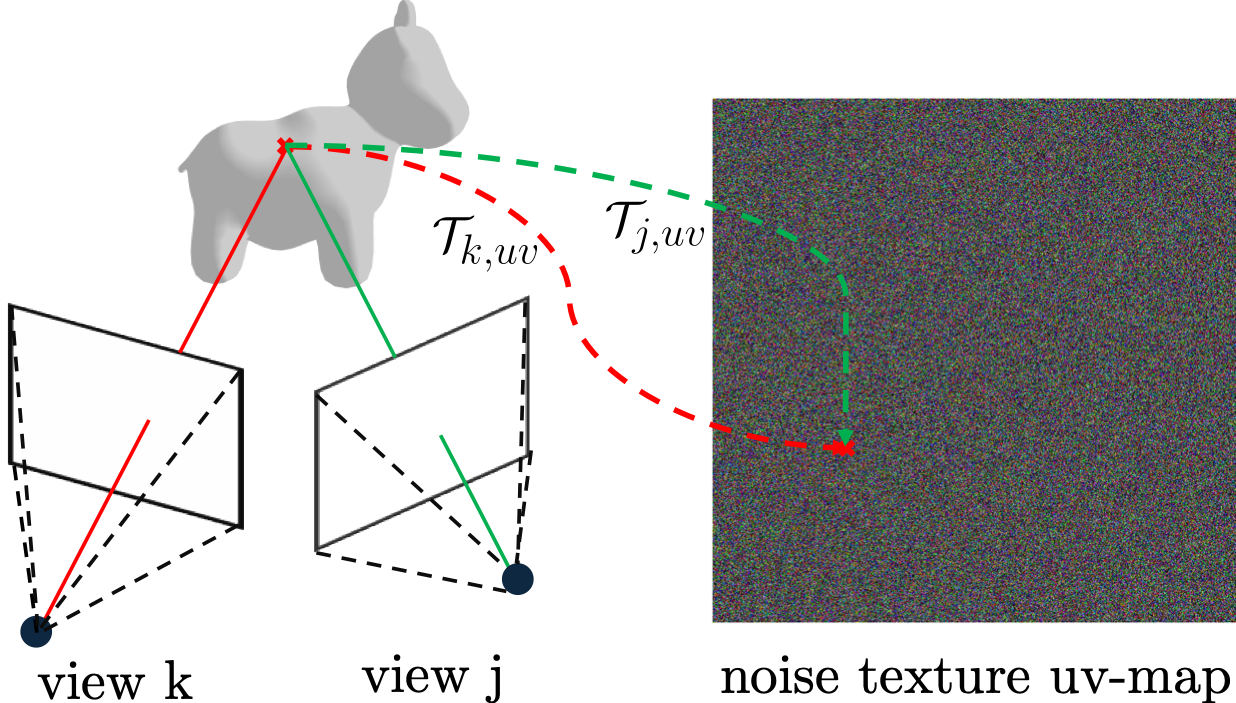
Additionally, we propose a novel approach to construct 3D- consistent noise for 3D-consistent video generation. We attach Gaussian noise as textures to 3D meshes and render the resulting noise images from various camera viewpoints as input to the diffusion model. We train EquiVDM on 2D videos without any 3D information using motion-based warped noise and we switched to the 3D consistent noise at the inference time. We demonstrate that EquiVDM leverages its equivariance properties to align the generated video frames faithfully according to the underlying 3D geometry and camera poses, in applications such as sim2real where a 3D mesh of the input scene is available. Please see the qualitative results demonstrating 3D-consistent video generation here.
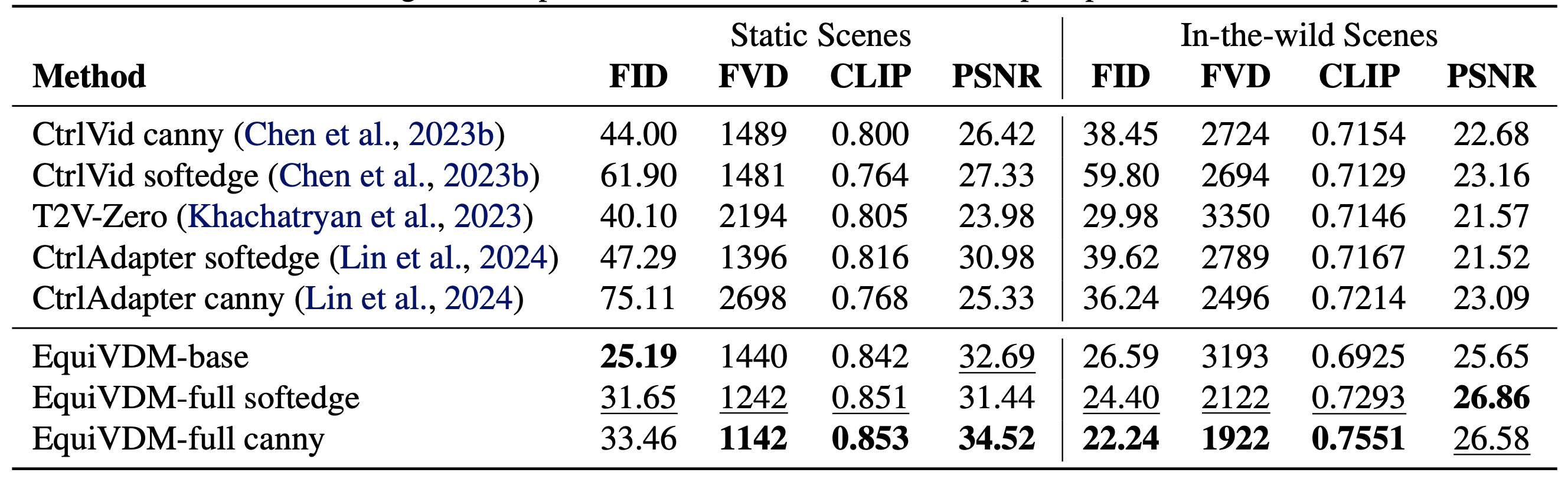
The table below shows the performance comparison between EquiVDM and other methods. EquiVDM-base generates videos from warped noise using text-only prompts, while EquiVDM-full has the additional conditioning modules finetuned from CtrlAdapter [1]. Even without the additional control modules, EquiVDM-base can already perform on par with or better than the compared methods with dedicated control modules. This demonstrates that EquiVDM can learn to generate better videos by taking advantage of the temporal correlation from the warped noise input. It also indicates that the temporal correlation in the warped noise can serve as a strong prior for both motion patterns and semantic information. With additional ControlNet modules, the quality and prompt-following of the generated videos from EquiVDM-full further improve, indicating that the benefit of equivariance is complementary to the additional conditioning modules. As a result, for video-to-video generation tasks, we can improve performance by making the full model noise-equivariant without any architectural modifications.
Reference:
[1] Lin et al., ICLR 2025. Ctrl-Adapter: An Efficient and Versatile Framework for Adapting Diverse Controls to Any Diffusion Model.
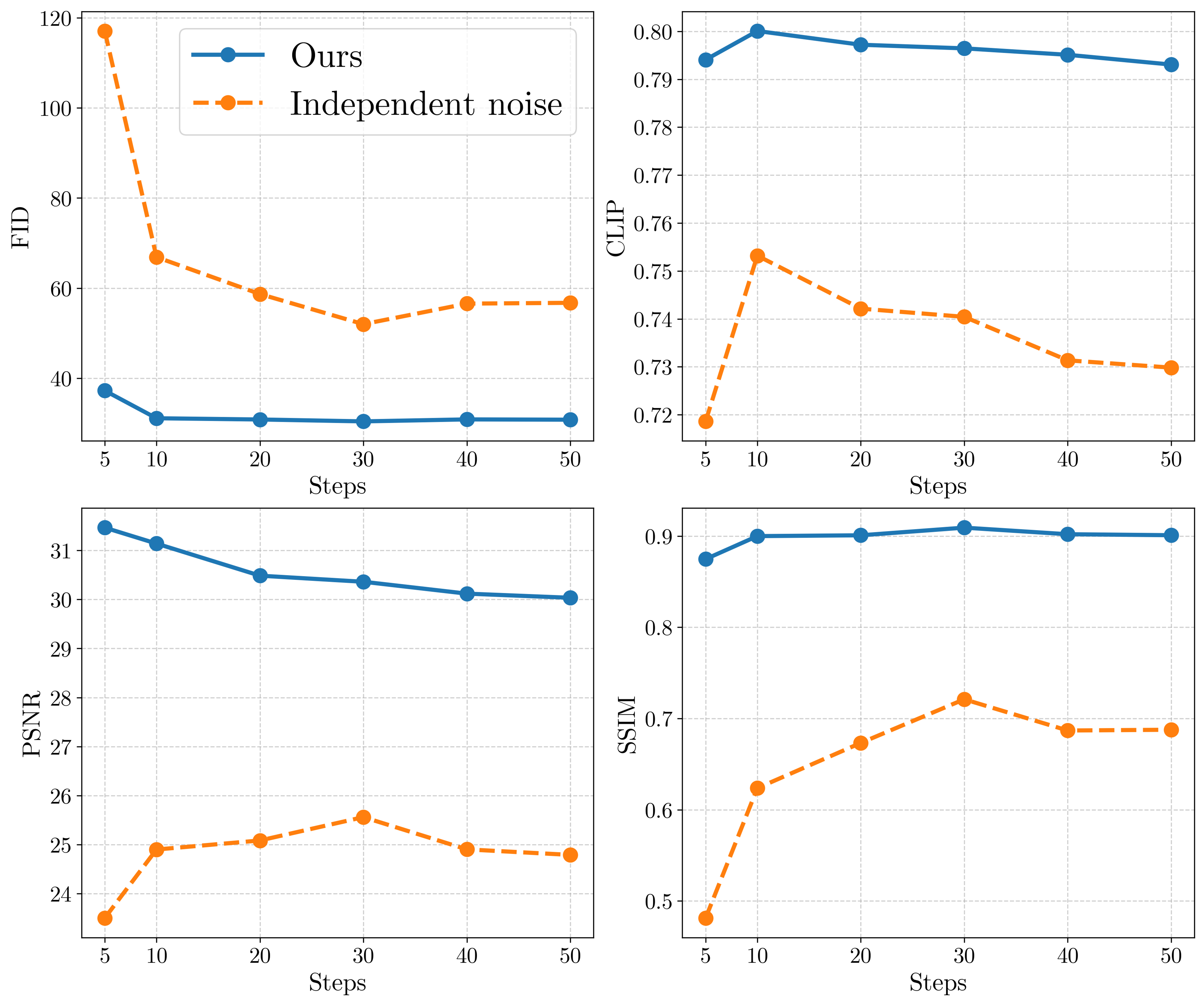
Since the motion information about the video is already included in the warped noise, less sampling steps are needed compared to the one using independent noise where both the motion and appearance have to be generated from scratch, as shown in the videos below.

We compare our method with video-to-video diffusion models with per-frame dense conditioning. In the results below, CtrlAdapter (Lin et al., 2024) and EquiVDM-full used soft-edge map as control signal for each frame along with the text prompt. EquiVDM-base only used text prompt. Our base EquiVDM (EquiVDM-base) without additinal controlling modules outperforms models that employ dense frame-level conditioning. Moreover, when EquiVDM is paired with ControlNet (EquiVDM-full), its performance improves even further. Please see the comparisons with more methods.
| CtrlAdapter | EquiVDM-base | EquiVDM-full | Ground Truth | Noise |
|---|---|---|---|---|
