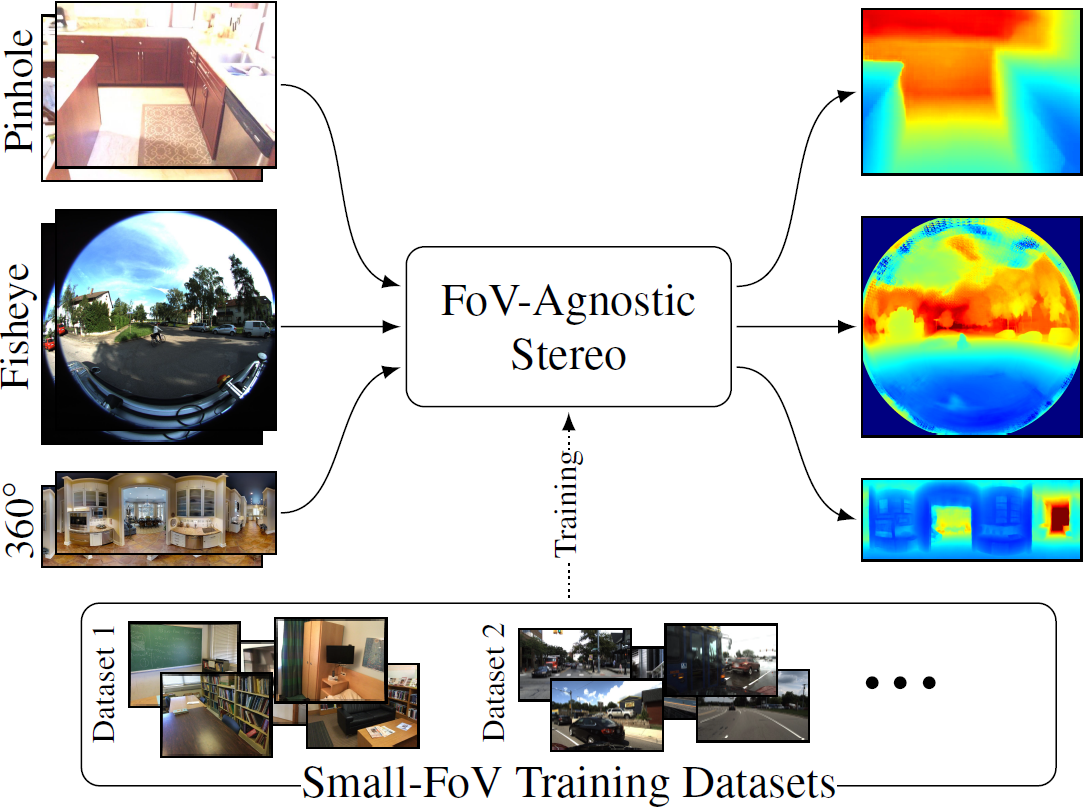
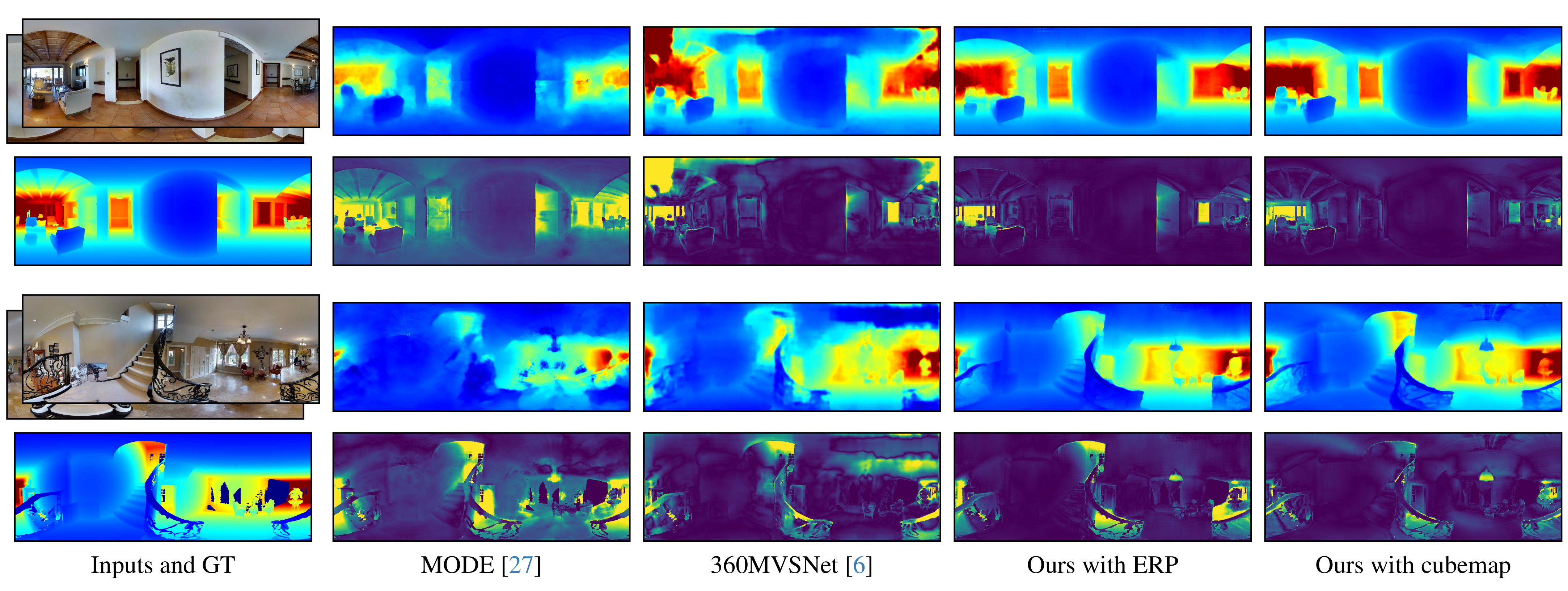
Wide field-of-view (FoV) cameras efficiently capture large portions of the scene, which makes them attractive in multiple domains, such as automotive and robotics. For such applications, estimating depth from multiple images is a critical task, and therefore, a large amount of ground truth (GT) data is available. Unfortunately, most of the GT data is for pinhole cameras, making it impossible to properly train depth estimation models for large-FoV cameras. We propose the first method to train a stereo depth estimation model on the widely available pinhole data, and to generalize it to data captured with larger FoVs. Our intuition is simple: We warp the training data to a canonical, large-FoV representation and augment it to allow a single network to reason about diverse types of distortions that otherwise would prevent generalization. We show strong generalization ability of our approach on both indoor and outdoor datasets, which was not possible with previous methods.
Alongside the project, we developed and released nvTorchCam, a library providing camera-agnostic 3D geometry functions.
As showcased in FoVA-Depth, nvTorchCam is particularly useful for developing PyTorch models that leverage plane-sweep
volumes (PSV) and related concepts such as sphere-sweep volumes or epipolar attention.
Key features of nvTorchCam include:
Check out the library 👉👉 here!
If you are interested in field-of-view agnostic depth estimation, you should also check out Depth Any Camera by Guo et al.
Citations:
[1] Li et al., MODE: Multi-view omnidirectional depth estimation with 360° cameras, ECCV 2022 [2] Chiu et al., 360MVSNet: Deep multi-view stereo network with 360° images for indoor scene reconstruction, WACV 2023 [3] Rey-Area et al., 360MonoDepth: High-resolution 360° monocular depth estimation, CVPR 2022 [4] Dai et al., ScanNet: Richly-annotated 3D reconstructions of indoor scenes, CVPR 2017 [5] Guizilini et al., 3D packing for self-supervised monocular depth estimation, CVPR 2020 [6] Liao et al., KITTI-360: A novel dataset and benchmarks for urban scene understanding in 2D and 3D, TPAMI 2022
@inproceedings{lichy2024fova,
title = {{FoVA-Depth}: {F}ield-of-View Agnostic Depth Estimation for Cross-Dataset Generalization},
author = {Lichy, Daniel and Su, Hang and Badki, Abhishek and Kautz, Jan and Gallo, Orazio},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2024}
}