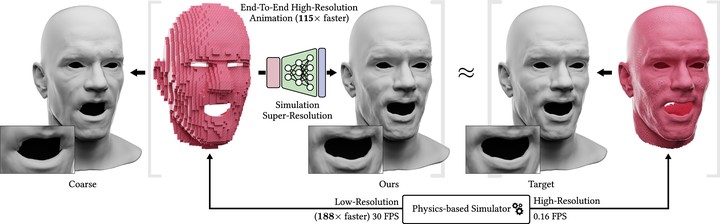
Abstract
We present a neural network-based simulation super-resolution framework that can efficiently and realistically enhance a facial performance produced by a low-cost, real-time physics-based simulation to a level of detail that closely approximates that of a reference-quality off-line simulator with much higher resolution (27 texttimes{} element count in our examples) and accurate physical modeling. Our approach is rooted in our ability to construct a training set of paired frames, from the low- and high-resolution simulators respectively, that are in semantic correspondence with each other. We use face animation as an exemplar of such a simulation domain, where creating this semantic congruence is achieved by simply dialing in the same muscle actuation controls and skeletal pose in the two simulators. Our proposed neural network super-resolution framework generalizes from this training set to unseen expressions, compensates for modeling discrepancies between the two simulations due to limited resolution or cost-cutting approximations in the real-time variant, and does not require any semantic descriptors or parameters to be provided as input, other than the result of the real-time simulation. We evaluate the efficacy of our pipeline on a variety of expressive performances and provide comparisons and ablation experiments for plausible variations and alternatives to our proposed scheme. Our code is available at https://github.com/hjoonpark/3d-sim-super- res.git.