Autoregressively extended text-to-4D synthesis with changing text guidance. Align Your Gaussians is able to autoregressively extend dynamic 4D sequences, combine sequences with different text-guidance, and create looping animations, returning to the initial pose. For the dynamic 4D asset on the left, we change from "running" to "walking" to "dancing" motions using the text prompts "Assassin with sword running fast, portrait, game, unreal, 4K, HD.", "Assassin walking, portrait, game, unreal, 4K, HD." and "Assassin dancing, portrait, game, unreal, 4K, HD.". The dynamic 4D scene is shown from two views, using one static and one rotating camera. Another example is shown on the right.
We can create a vivid party scene from different generated dynamic 4D assets (the stage and stars are created manually).
Happy Holidays!
We assembled a large selection of our generated dynamic 4D assets on a grid.
The dogs smoothly alternate between "running" and "barking" motions. They are optimized to return to their initial poses, enabling looping animations.
Text-guided diffusion models have revolutionized image and video generation and have also been successfully used for optimization-based 3D object synthesis. Here, we instead focus on the underexplored text-to-4D setting and synthesize dynamic, animated 3D objects using score distillation methods with an additional temporal dimension. Compared to previous work, we pursue a novel compositional generation-based approach, and combine text-to-image, text-to-video, and 3D-aware multiview diffusion models to provide feedback during 4D object optimization, thereby simultaneously enforcing temporal consistency, high-quality visual appearance and realistic geometry. Our method, called Align Your Gaussians (AYG), leverages dynamic 3D Gaussian Splatting with deformation fields as 4D representation. Crucial to AYG is a novel method to regularize the distribution of the moving 3D Gaussians and thereby stabilize the optimization and induce motion. We also propose a motion amplification mechanism as well as a new autoregressive synthesis scheme to generate and combine multiple 4D sequences for longer generation. These techniques allow us to synthesize vivid dynamic scenes, outperform previous work qualitatively and quantitatively and achieve state-of-the-art text-to-4D performance. Due to the Gaussian 4D representation, different 4D animations can be seamlessly combined, as we demonstrate. AYG opens up promising avenues for animation, simulation and digital content creation as well as synthetic data generation.
We present Align Your Gaussians (AYG) for high-quality text-to-4D dynamic scene generation. AYG uses dynamic 3D Gaussians with deformation fields as its dynamic 4D representation. An advantage of this representation is its explicit nature, which allows us to easily compose different dynamic 4D assets in large scenes. With commonly used neural radiance field-based representations this would be more difficult. AYG's dynamic 4D scenes are generated through score distillation, leveraging composed text-to-image, text-to-video and 3D-aware text-to-multiview-image latent diffusion models. The text-to-video model is used to generate the 4D scenes' temporal dynamics, while the 3D-aware text-to-multiview-image model ensures realistic and consistent 3D geometry. Moreover, the text-to-image model serves as general image prior and improves visual appearance. The optimization is carried out in two stages. First we optimize the 3D Gaussians to produce a high-quality 3D shape, then we optimize the deformation field to add dynamics.
Stage 1: Static 3D Synthesis. In the first stage, we use the multiview text-guided latent diffusion model MVDream and the general text-to-image latent diffusion model Stable Diffusion during score distillation and optimize the 3D Gaussians to form a static 3D scene (see figure below).
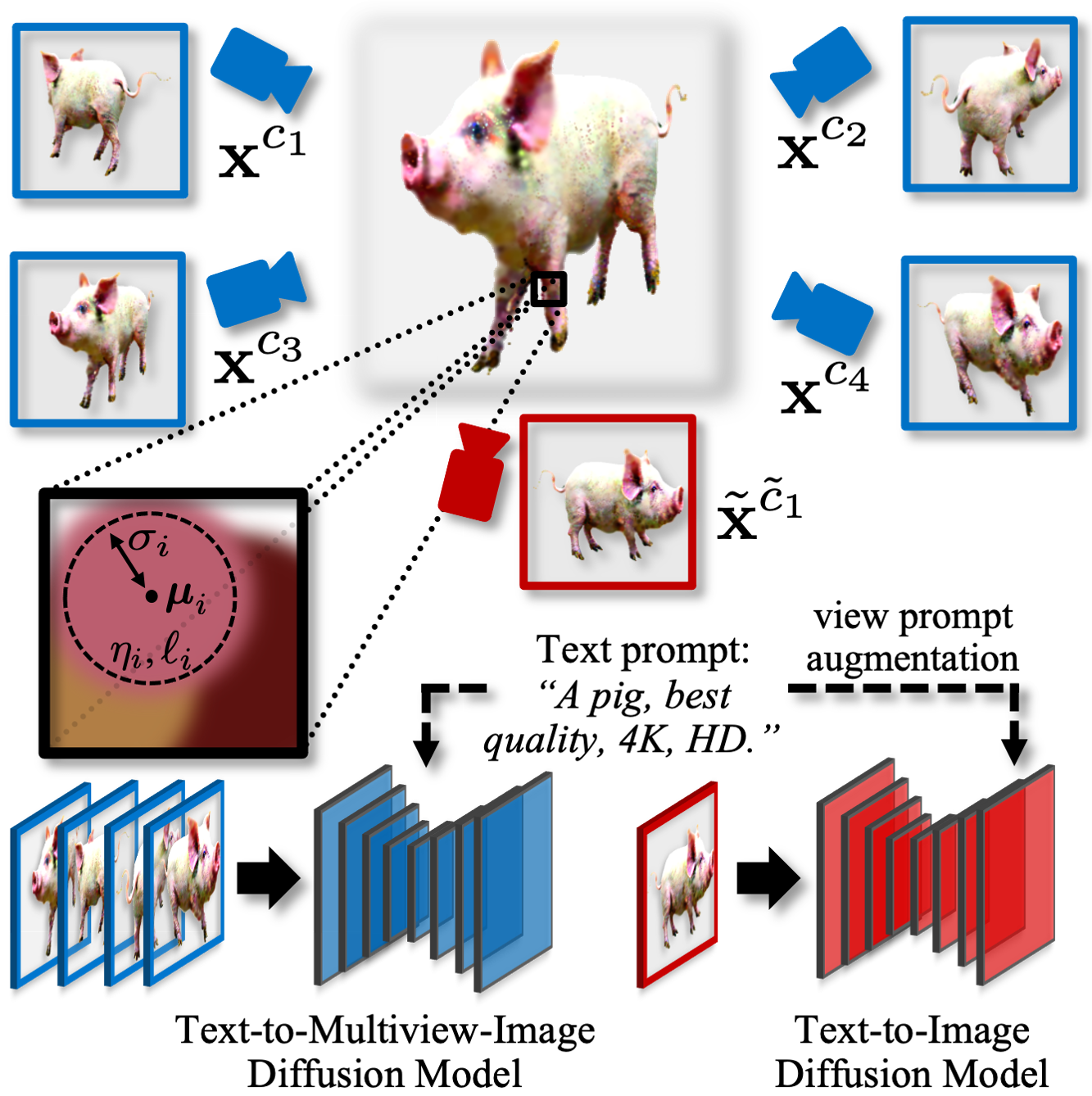
In AYG's initial 3D stage we synthesize a static 3D scene leveraging a text-guided multiview diffusion model (MVDream) and a regular text-to-image model (Stable Diffusion). The text-to-image model receives viewing angle-dependent text prompts and leverages view guidance (see paper).
Stage 2: Dynamic 4D Synthesis. Next, we combine the text-to-video and the text-to-image models and optimize the deformation field to generate the temporal dynamics and thereby produce a moving and deformating dynamic 4D asset (see figure below). We trained our own video model for this purpose, mostly following Video Latent Diffusion Models (see paper for details). Including the text-to-image model in the optimization helps ensuring that high individual frame quality is maintained while optimizing the deformation field.
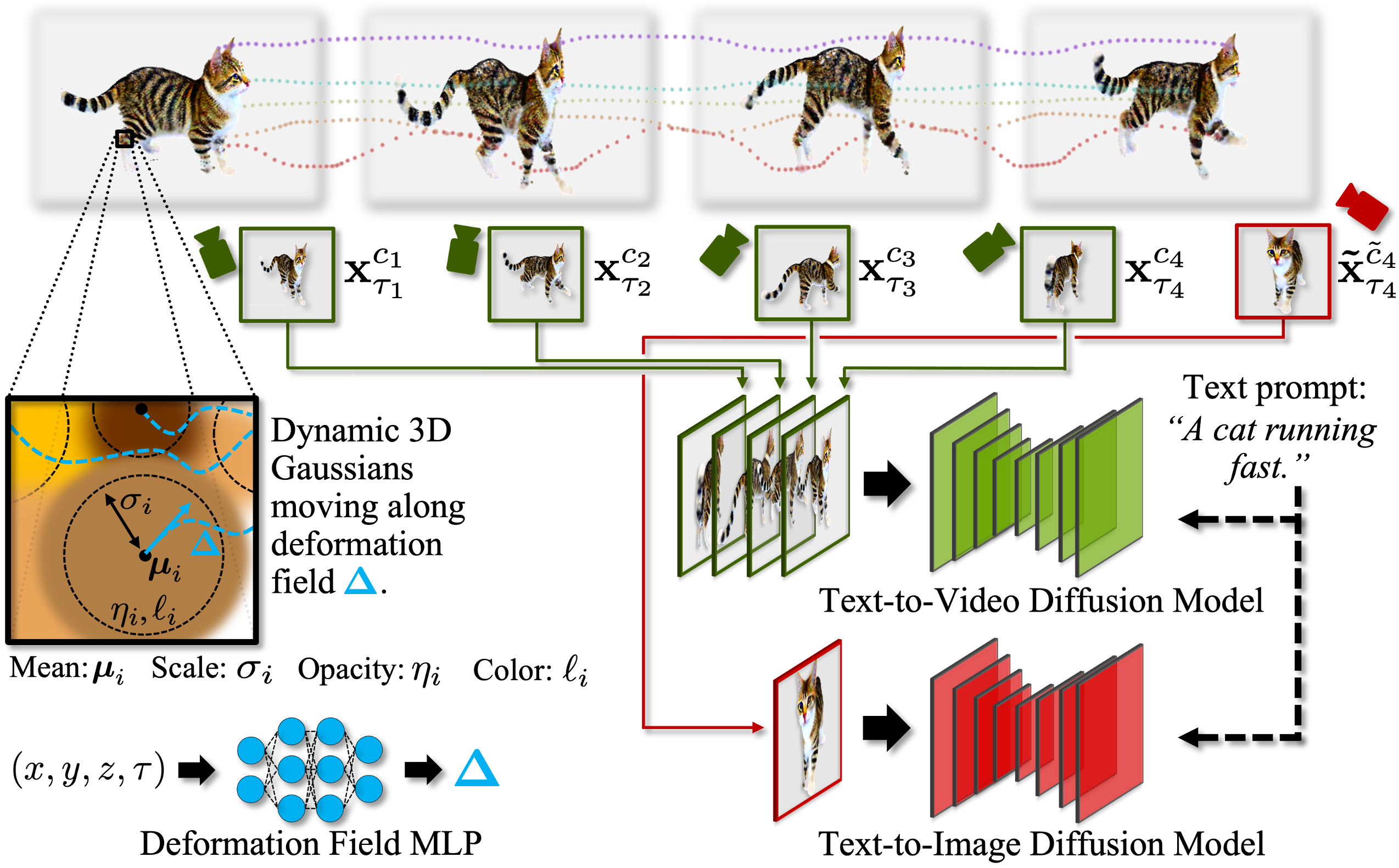
Text-to-4D synthesis with AYG. We generate dynamic 4D scenes via score distillation. We initialize the 4D sequence from a static 3D scene (generated first in stage 1, see above), which is represented by 3D Gaussians with means, scales, opacities and colors. Consecutive rendered frames from the 4D sequence are diffused and fed to a text-to-video diffusion model (green arrows), which provides a distillation gradient that is backpropagated through the rendering process into the deformation field (blue dotted lines) that captures scene motion. Simultaneously, random frames are diffused and given to a text-to-image diffusion model (red arrows) whose gradients ensure that high visual quality is maintained frame-wise. See paper for details.
Moreover, AYG's score distillation uses novel guidance and regularization methods. Among other things, we propose a new motion amplification technique and a novel way to regularize the distribution of the dynamic 3D Gaussians during the second stage optimization of the deformation field. We also developed a scheme for autoregressively extended synthesis, allowing us to generate longer 4D sequences and to change the text-guidance while doing so. For more details, please see the paper.
Future Applications. We find that Align Your Gaussians can generate diverse, vivid, detailed and 3D-consistent dynamic 4D scenes, achieving state-of-the-art text-to-4D performance. We hope that AYG opens up promising new avenues for animation, simulation and digital content creation, where AYG takes a step beyond the literature on text-to-3D synthesis and also captures our world's rich temporal dynamics. Moreover, AYG can generate dynamic 4D scenes with exact tracking labels for free, a potentially valuable feature in synthetic data generation.

Align Your Gaussians:
Text-to-4D with Dynamic 3D Gaussians and Composed Diffusion Models
Huan Ling*, Seung Wook Kim*, Antonio Torralba, Sanja Fidler, Karsten Kreis
* Equal contribution.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024 (Highlight)
@inproceedings{ling2024alignyourgaussians,
title={Align Your Gaussians: Text-to-4D with Dynamic 3D Gaussians and Composed Diffusion Models},
author={Ling, Huan and Kim, Seung Wook and Torralba, Antonio and Fidler, Sanja and Kreis, Karsten},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition ({CVPR})},
year={2024}
}