The following video explains the pipeline of our real-robot reinforcement learning (RL) method.
SPARR is a hybrid framework to pre-train a base policy with low-dimensional state observations in simulation and then learn a residual policy with visual observations in the real world. The base policy provides successful demonstrations, a structured prior and safe early exploration, while the residual policy corrects for discrepancies in physical properties, state estimation errors, and visual or environmental differences. This asymmetric design enables efficient adaptation to real-world environments without reliance on human supervision.
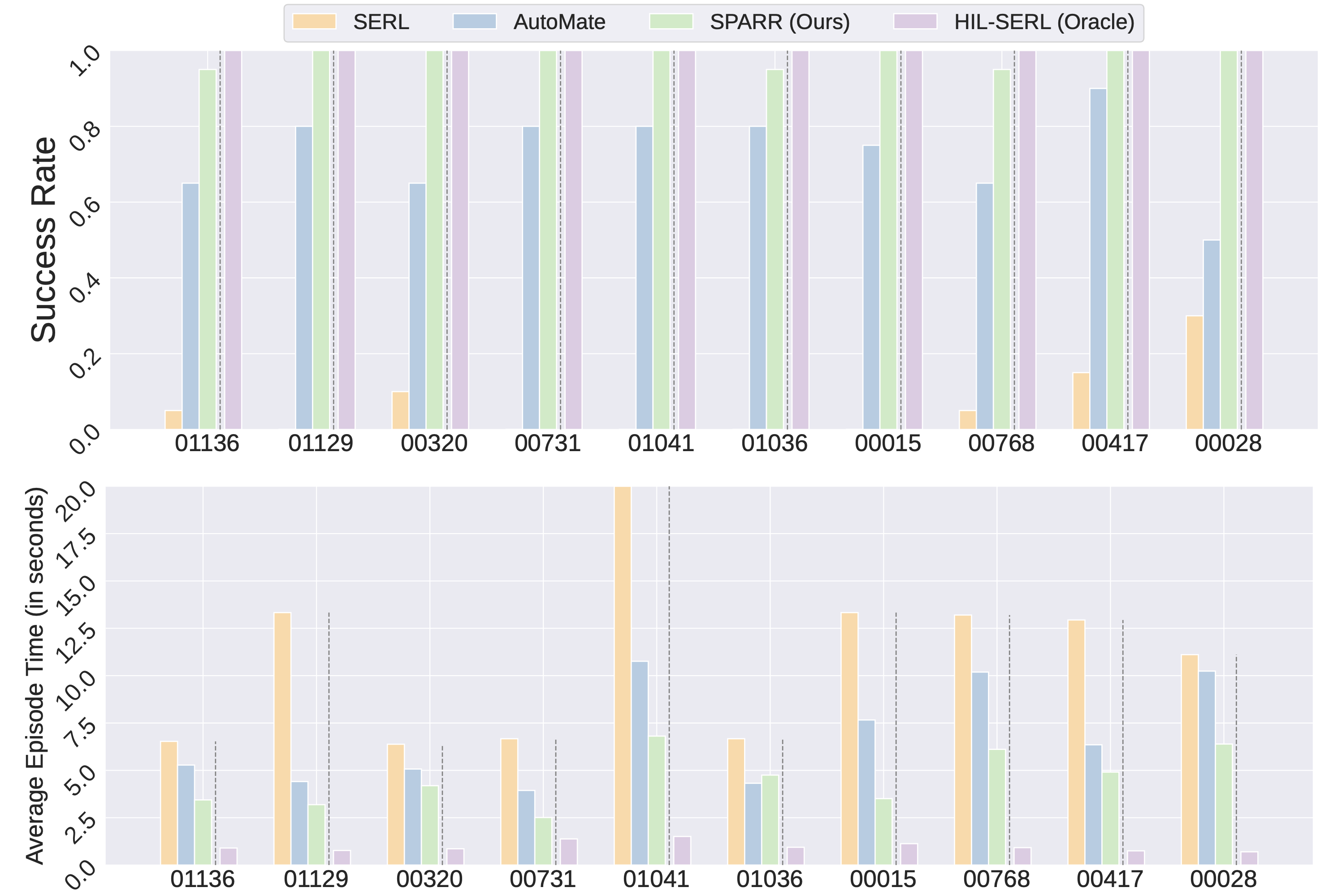
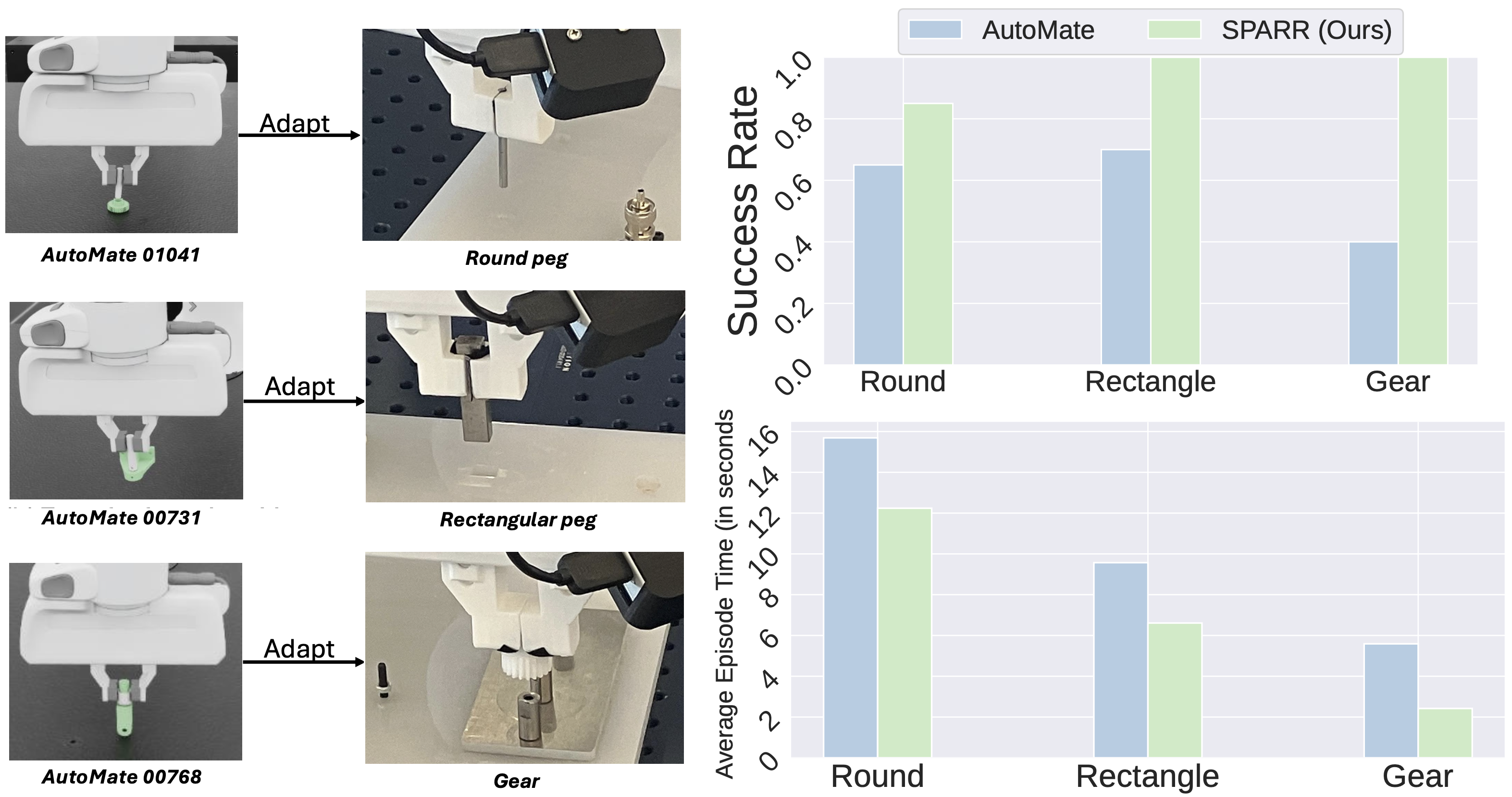
Robotic assembly presents a long-standing challenge due to its requirement for precise, contact-rich manipulation. While simulation-based learning has enabled the development of robust assembly policies, their performance often degrades when deployed in real-world settings due to the sim-to-real gap. Conversely, real-world reinforcement learning (RL) methods avoid the sim-to-real gap, but rely heavily on human supervision and lack generalization ability to environmental changes. In this work, we propose a hybrid approach that combines a simulation-trained base policy with a real-world residual policy to efficiently adapt to real-world variations. The base policy, trained in simulation using low-level state observations and dense rewards, provides strong priors for initial behavior. The residual policy, learned in the real world using visual observations and sparse rewards, compensates for discrepancies in dynamics and sensor noise. Extensive real-world experiments demonstrate that our method, SPARR, achieves near-perfect success rates across diverse two-part assembly tasks. Compared to the state-of-the-art zero-shot sim-to-real methods, SPARR improves success rates by 38.4% while reducing cycle time by 29.7%. Moreover, SPARR requires no human expertise, in contrast to the state-of-the-art real-world RL approaches that depend heavily on human supervision.
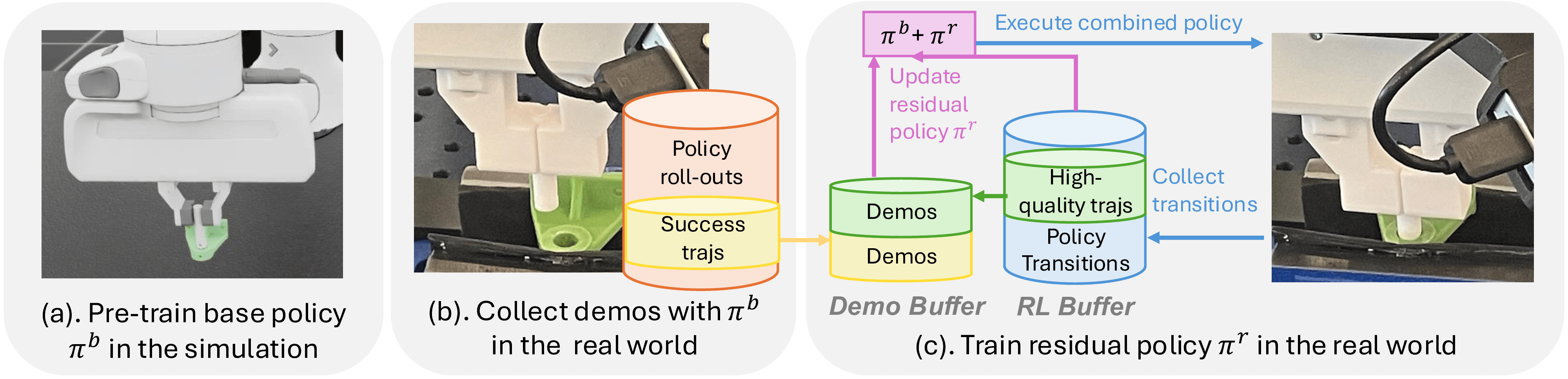
Illustration of our approach, SPARR. (a) A specialist policy is pre-trained in simulation. (b) The simulation policy is deployed zero-shot in the real world, achieving a moderate success rate (e.g., up to 80%). Successful trajectories are collected as demonstrations. (c) A residual policy is trained in the real world on top of the simulation policy, leveraging both the demonstration buffer and the online RL buffer. During training, high-quality trajectories that achieve success quickly are added in demonstrations for further exploitation.