LANA: Latency Aware Network Acceleration
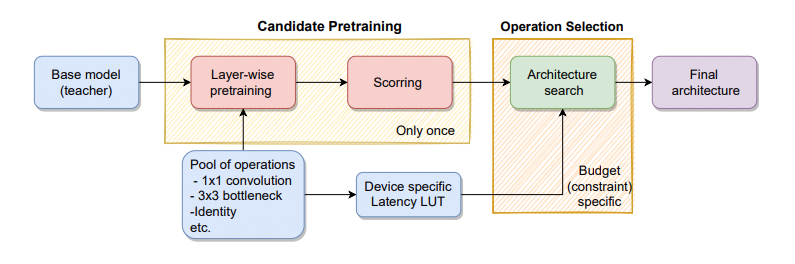
We introduce latency-aware network acceleration (LANA) - an approach that builds on neural architecture search techniques and teacher-student distillation to accelerate neural networks. LANA consists of two phases: in the first phase, it trains many alternative operations for every layer of the teacher network using layer-wise feature map distillation. In the second phase, it solves the combinatorial selection of efficient operations using a novel constrained integer linear optimization (ILP) approach. ILP brings unique properties as it (i) performs NAS within a few seconds to minutes, (ii) easily satisfies budget constraints, (iii) works on the layer-granularity, (iv) supports a huge search space O(10^100), surpassing prior search approaches in efficacy and efficiency. In extensive experiments, we show that LANA yields efficient and accurate models constrained by a target latency budget while being significantly faster than other techniques. We analyze three popular network architectures: EfficientNetV1, EfficientNetV2, and ResNeST, and achieve accuracy improvement for all models (up to 3.0%) when compressing larger models to the latency level of smaller models. LANA achieves significant speed-ups (up to 5×) with minor to no accuracy drop on GPU and CPU. The code will be shared soon.