Taming optimization variance in compact neural shading networks
Abstract
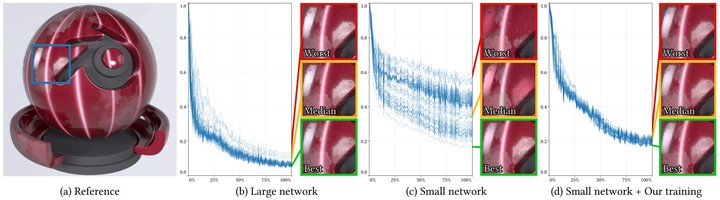
We present a training algorithm to mitigate optimization instabilities in small neural networks, like those used in real-time neural shading applications. While large, overparameterized models exhibit predictable convergence, smaller architectures often suffer from high optimization variance: differently initialized models converge to disparate local minima. To reduce these training instabilities, we introduce an optimization approach that utilizes an ensemble of network instances during training. We prune underperforming instances and dynamically resize training batches to maintain wall-clock timings comparable to—or faster than—single-instance training. This strategy allows efficiently exploring the weight space yielding a well-performing model with significantly higher likelihood than optimizing a single instance only. We develop and analyze the algorithm in the context of learning reflectance functions for neural shading. This is a challenging task for small neural models due to the high dynamic range of the target function. In addition to our multi-instance training method, we also revisit the choices of loss functions, activation functions, and input parameterization to further improve quality and training robustness.