SuperCollider: Scalable and Effective Data Race Detection for CUDA
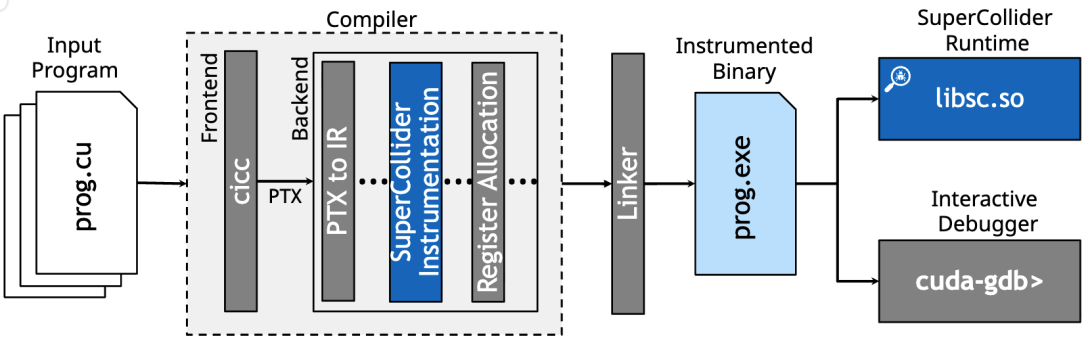
Data races, which occur when two or more threads incorrectly access the same memory location without appropriate synchronization, cause CUDA programmers considerable pain. Even experts struggle to reason about extreme parallelism, multiple memory spaces and scopes, and diverse synchronization mechanisms. Races can manifest as subtle data corruption, deadlock, or livelock, which are difficult to reproduce in a debugging environment. To date, there is no generally reliable tool for identifying races in GPU programs at scale. State-of-the-art dynamic GPU race detectors attempt to detect data races by faithfully tracking the memory operations, barriers, and memory fences executed by tens of thousands of threads. While this complexity enables the detection of subtle races, it comes with a cost: existing tools incur substantial memory-footprint overheads (e.g., greater than 9x) and/or runtime overheads (e.g., 1000x), and tend to report false positives. This paper introduces SuperCollider, a simple race detector for CUDA that tracks only thread-level state, is agnostic to synchronization protocols, introduces no memory-footprint overhead, seamlessly handles shared, global, and tensor memory spaces, does not produce false positives, and is relatively fast. Although SuperCollider cannot detect all races, we demonstrate that it effectively catches many data races in professionally authored CUDA programs, including races that prior art cannot. Our approach exposed over 90 data races across libraries and CUDA benchmarks, and even found a race in the CUDA Programming Guide. Unlike prior art, SuperCollider can operate at the extreme scales required by modern GPU workloads.
Publication Date
Published in
Research Area
Uploaded Files
Copyright
This work is licensed under a Creative Commons Attribution 4.0 International License.
© 2026 Copyright held by the owner/author(s).