Fine-Grained DRAM: Energy-Efficient DRAM for Extreme Bandwidth Systems
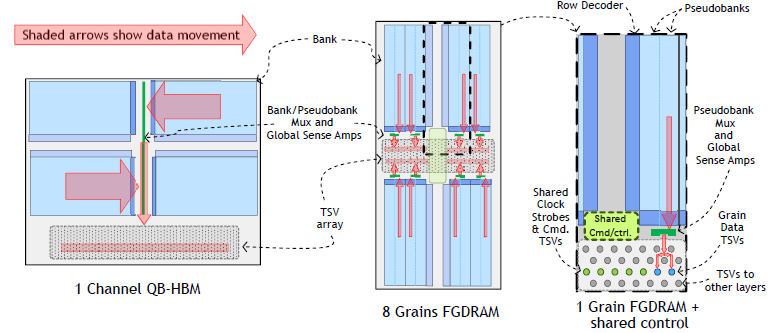
Future GPUs and other high-performance throughput processors will require multiple TB/s of bandwidth to DRAM. Satisfying this bandwidth demand within an acceptable energy budget is a challenge in these extreme bandwidth memory systems. We propose a new high-bandwidth DRAM architecture, Fine-Grained DRAM (FGDRAM), which improves bandwidth by 4× and improves the energy efficiency of DRAM by 2× relative to the highest-bandwidth, most energy-efficient contemporary DRAM, High Bandwidth Memory (HBM2). These benefits are in large measure achieved by partitioning the DRAM die into many independent units, called grains, each of which has a local, adjacent I/O. This approach unlocks the bandwidth of all the banks in the DRAM to be used simultaneously, eliminating shared buses interconnecting various banks. Furthermore, the on-DRAM data movement energy is significantly reduced due to the much shorter wiring distance between the cell array and the local I/O. This FGDRAM architecture readily lends itself to leveraging existing techniques to reducing the effective DRAM row size in an area efficient manner, reducing wasteful row activate energy in applications with low locality. In addition, when FGDRAM is paired with a memory controller optimized to exploit the additional concurrency provided by the independent grains, it improves GPU system performance by 19% over an iso-bandwidth and iso-capacity future HBM baseline. Thus, this energy-efficient, high-bandwidth FGDRAM architecture addresses the needs of future extreme-bandwidth memory systems.
Publication Date
Published in
Research Area
External Links
Uploaded Files
Copyright
Copyright by the Association for Computing Machinery, Inc. Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, to republish, to post on servers, or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from Publications Dept, ACM Inc., fax +1 (212) 869-0481, or permissions@acm.org. The definitive version of this paper can be found at ACM's Digital Library http://www.acm.org/dl/.