A Causal View of Compositional Zero-Shot Recognition
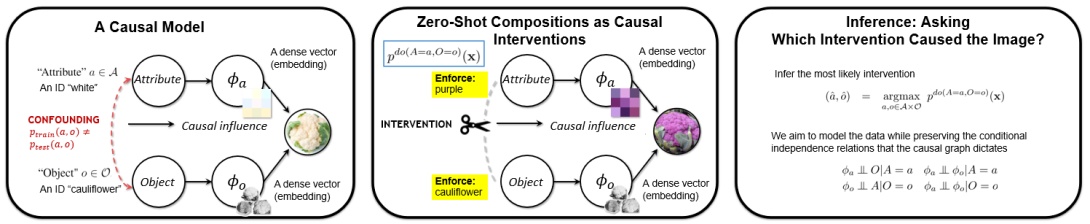
People easily recognize new visual categories that are new combinations of known components. This compositional generalization capacity is critical for learning in real-world domains like vision and language because the long tail of new combinations dominates the distribution. Unfortunately, learning systems struggle with compositional generalization because they often build on features that are correlated with class labels even if they are not "essential" for the class. This leads to consistent misclassification of samples from a new distribution, like new combinations of known components. Here we describe an approach for compositional generalization that builds on causal ideas. First, we describe compositional zero-shot learning from a causal perspective, and propose to view zero-shot inference as finding "which intervention caused the image?". Second, we present a causal-inspired embedding model that learns disentangled representations of elementary components of visual objects from correlated (confounded) training data. We evaluate this approach on two datasets for predicting new combinations of attribute-object pairs: A well-controlled synthesized images dataset and a real world dataset which consists of fine-grained types of shoes. We show improvements compared to strong baselines.