Heterogeneous Dataflow Accelerators for Multi-DNN Workloads
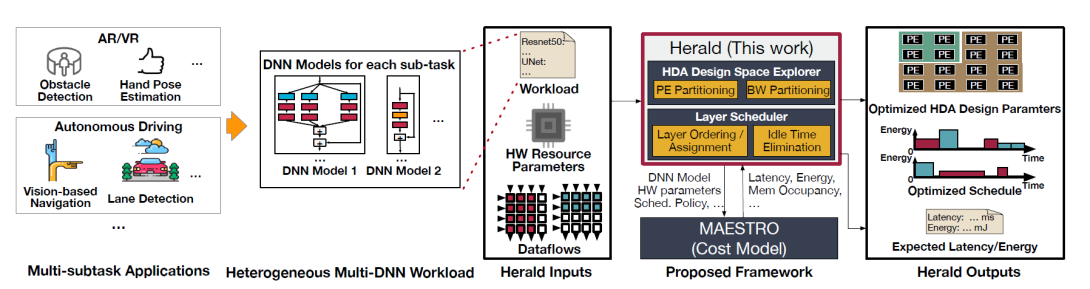
AI-enabled applications such as augmented and virtual reality (AR/VR) leverage multiple deep neural network (DNN) models for various sub-tasks such as object detection, image segmentation, eye-tracking, speech recognition, and so on. Because of the diversity of the sub-tasks, the layers within and across the DNN models are highly heterogeneous in operation and shape. Diverse layer operations and shapes are major challenges for a fixed dataflow accelerator (FDA) that employs a fixed dataflow strategy on a single DNN accelerator substrate since each layer prefers different dataflows (computation order and parallelization) and tile sizes. Reconfigurable DNN accelerators (RDAs) have been proposed to adapt their dataflows to diverse layers to address the challenge. However, the dataflow flexibility in RDAs is enabled at the cost of expensive hardware structures (switches, interconnects, controller, etc.) and requires per-layer reconfiguration, which introduces considerable energy costs. Alternatively, this work proposes a new class of accelerators, heterogeneous dataflow accelerators (HDAs), which deploy multiple accelerator substrates (i.e., sub-accelerators), each supporting a different dataflow. HDAs enable coarser-grained dataflow flexibility than RDAs with higher energy efficiency and lower area cost comparable to FDAs. To exploit such benefits, hardware resource partitioning across sub-accelerators and layer execution schedule need to be carefully optimized. Therefore, we also present Herald, a framework for co-optimizing hardware partitioning and layer scheduling. Using Herald on a suite of AR/VR and MLPerf workloads, we identify a promising HDA architecture, Maelstrom, which demonstrates 65.3% lower latency and 5.0% lower energy compared to the best fixed dataflow accelerators and 22.0% lower energy at the cost of 20.7% higher latency compared to a state-of-the-art reconfigurable DNN accelerator (RDA). The results suggest that HDA is an alternative class of Pareto-optimal accelerators to RDA with strength in energy, which can be a better choice than RDAs depending on the use cases.
Publication Date
External Links
Uploaded Files
Copyright
This material is posted here with permission of the IEEE. Internal or personal use of this material is permitted. However, permission to reprint/republish this material for advertising or promotional purposes or for creating new collective works for resale or redistribution must be obtained from the IEEE by writing to pubs-permissions@ieee.org.