Improving Hyperparameter Optimization with Checkpointed Model Weights
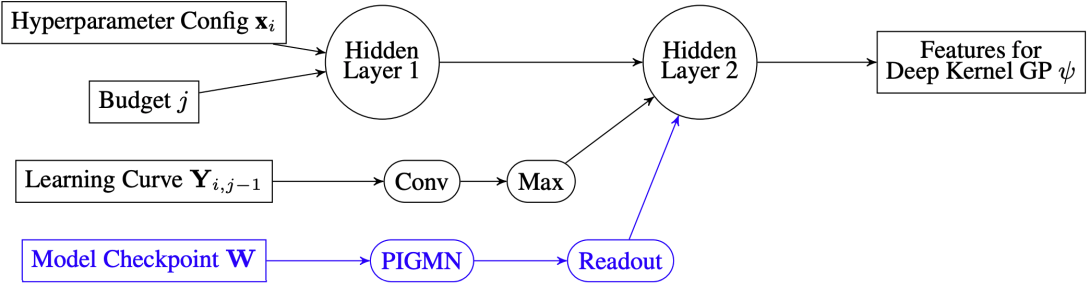
When training deep learning models, the performance depends largely on the selected hyperparameters. However, hyperparameter optimization (HPO) is often one of the most expensive parts of model design. Classical HPO methods treat this as a black-box optimization problem. However, gray-box HPO methods, which incorporate more information about the setup, have emerged as a promising direction for more efficient optimization. For example, we can use intermediate loss evaluations to terminate bad selections. In this work, we propose an HPO method for neural networks that uses logged checkpoints of the trained weights to guide future hyperparameter selections. Our Forecasting Model Search (FMS) method embeds weights into a Gaussian process deep kernel surrogate model, to be data-efficient with the logged network weights. To facilitate reproducibility and further research, we open-source our code.