Architecture Considerations for Tracing Incoherent Rays
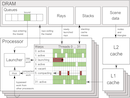
This paper proposes a massively parallel hardware architecture for efficient tracing of incoherent rays, e.g. for global illumination. The general approach is centered around hierarchical treelet subdivision of the acceleration structure and repeated queueing/postponing of rays to reduce cache pressure. We describe a heuristic algorithm for determining the treelet subdivision, and show that our architecture can reduce the total memory bandwidth requirements by up to 90% in difficult scenes. Furthermore the architecture allows submitting rays in an arbitrary order with practically no performance penalty. We also conclude that scheduling algorithms can have an important effect on results, and that using fixed-size queues is not an appealing design choice. Increased auxiliary traffic, including traversal stacks, is identified as the foremost remaining challenge of this architecture.
Publication Date
Published in
Research Area
Uploaded Files
Copyright
Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than Eurographics must be honored.