On the Distance between Two Neural Networks and the Stability of Learning
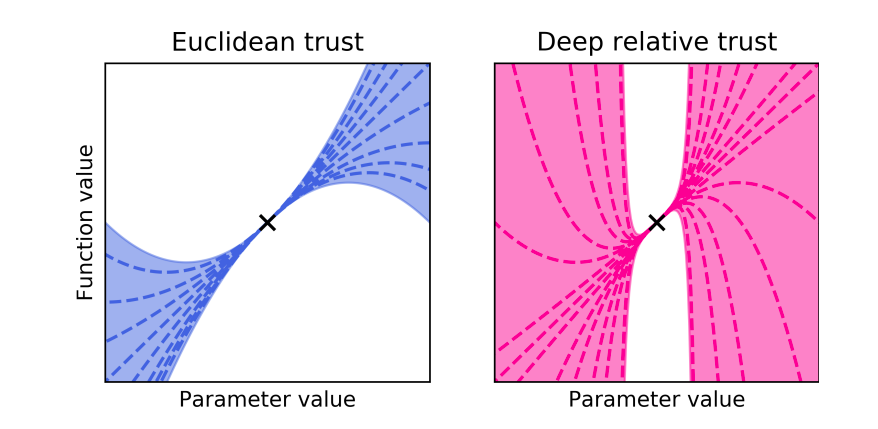
This paper relates parameter distance to gradient breakdown for a broad class of nonlinear compositional functions. The analysis leads to a new distance function called deep relative trust and a descent lemma for neural networks. Since the resulting learning rule seems to require little to no learning rate tuning, it may unlock a simpler workflow for training deeper and more complex neural networks. The Python code used in this paper is available at this URL.