Dreaming to Distill: Data-free Knowledge Transfer via DeepInversion
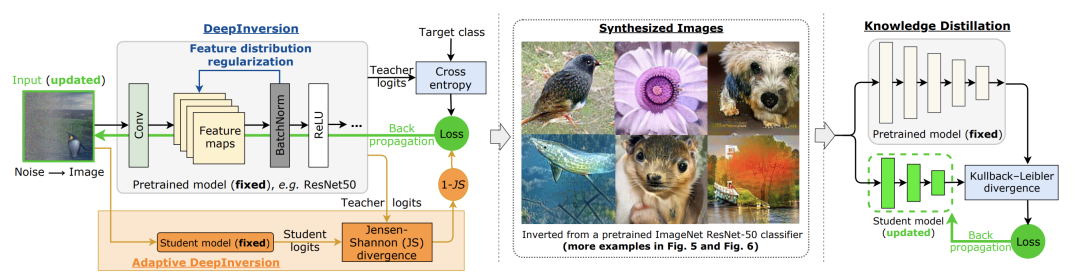
We introduce DeepInversion, a new method for synthesizing images from the image distribution used to train a deep neural network. We “invert” a trained network (teacher) to synthesize class-conditional input images starting from random noise, without using any additional information on the training dataset. Keeping the teacher fixed, our method optimizes the input while regularizing the distribution of intermediate feature maps using information stored in the batch normalization layers of the teacher. Further, we improve the diversity of synthesized images using Adaptive DeepInversion, which maximizes the Jensen-Shannon divergence between the teacher and student network logits. The resulting synthesized images from networks trained on the CIFAR-10 and ImageNet datasets demonstrate high fidelity and degree of realism, and help enable a new breed of data-free applications – ones that do not require any real images or labeled data. We demonstrate the applicability of our proposed method to three tasks of immense practical importance – (i) data-free network pruning, (ii) data-free knowledge transfer, and (iii) data-free continual learning. Code is available at https: //github.com/NVlabs/DeepInversion.